このページの目次
NorthStar コントローラ トラブルシューティング ガイド
このドキュメントには、明らかな問題がNorthStarコントローラまたはルータに起因するものかどうかを判断するための戦略が含まれており、NorthStarコントローラに起因すると識別された問題のトラブルシューティング手法を提供します。
トラブルシューティングの調査を開始する前に、すべてのシステム プロセスが稼働していることを確認してください。プロセスのサンプルリストを以下に示します。実際のプロセスのリストは異なる場合があります。
[root@node-1 ~]# supervisorctl status bmp:bmpMonitor RUNNING pid 2957, uptime 0:58:02 collector:worker1 RUNNING pid 19921, uptime 0:01:42 collector:worker2 RUNNING pid 19923, uptime 0:01:42 collector:worker3 RUNNING pid 19922, uptime 0:01:42 collector:worker4 RUNNING pid 19924, uptime 0:01:42 collector_main:beat_scheduler RUNNING pid 19770, uptime 0:01:53 collector_main:es_publisher RUNNING pid 19771, uptime 0:01:53 collector_main:task_scheduler RUNNING pid 19772, uptime 0:01:53 config:cmgd RUNNING pid 22087, uptime 0:01:53 config:cmgd-rest RUNNING pid 22088, uptime 0:01:53 docker:dockerd RUNNING pid 4368, uptime 0:57:34 epe:epeplanner RUNNING pid 9047, uptime 0:50:34 infra:cassandra RUNNING pid 2971, uptime 0:58:02 infra:ha_agent RUNNING pid 9009, uptime 0:50:45 infra:healthmonitor RUNNING pid 9172, uptime 0:49:40 infra:license_monitor RUNNING pid 2968, uptime 0:58:02 infra:prunedb RUNNING pid 19770, uptime 0:01:53 infra:rabbitmq RUNNING pid 7712, uptime 0:52:03 infra:redis_server RUNNING pid 2970, uptime 0:58:02 infra:zookeeper RUNNING pid 2965, uptime 0:58:02 ipe:ipe_app RUNNING pid 2956, uptime 0:58:02 listener1:listener1_00 RUNNING pid 9212, uptime 0:49:29 netconf:netconfd_00 RUNNING pid 19768, uptime 0:01:53 northstar:anycastGrouper RUNNING pid 19762, uptime 0:01:53 northstar:configServer RUNNING pid 19767, uptime 0:01:53 northstar:mladapter RUNNING pid 19765, uptime 0:01:53 northstar:npat RUNNING pid 19766, uptime 0:01:53 northstar:pceserver RUNNING pid 19441, uptime 0:02:59 northstar:privatet1vproxy RUNNING pid 19432, uptime 0:02:59 northstar:prpdclient RUNNING pid 19763, uptime 0:01:53 northstar:scheduler RUNNING pid 19764, uptime 0:01:53 northstar:topologyfilter RUNNING pid 19760, uptime 0:01:53 northstar:toposerver RUNNING pid 19762, uptime 0:01:53 northstar_pcs:PCServer RUNNING pid 19487, uptime 0:02:49 northstar_pcs:PCViewer RUNNING pid 19486, uptime 0:02:49 web:app RUNNING pid 19273, uptime 0:03:18 web:gui RUNNING pid 19280, uptime 0:03:18 web:notification RUNNING pid 19272, uptime 0:03:18 web:proxy RUNNING pid 19275, uptime 0:03:18 web:restconf RUNNING pid 19271, uptime 0:03:18 web:resthandler RUNNING pid 19275, uptime 0:03:18
「実行中」ではなく「停止済み」と表示されているプロセスを再起動します。
すべてのプロセスを停止、開始、または再起動するには、 、 service northstar start、および service northstar restart のコマンドを使用しますservice northstar stop。
NorthStar Controller Web UI からシステム プロセスのステータス情報にアクセスするには、[>Administration] に移動して More Optionsを選択しますSystem Health。
各システムプロセスの現在のCPU%、メモリ使用量、仮想メモリ使用量、およびその他の統計が表示されます。 図 1 に例を示します。
実行中のプロセスのみがこの画面に含まれます。
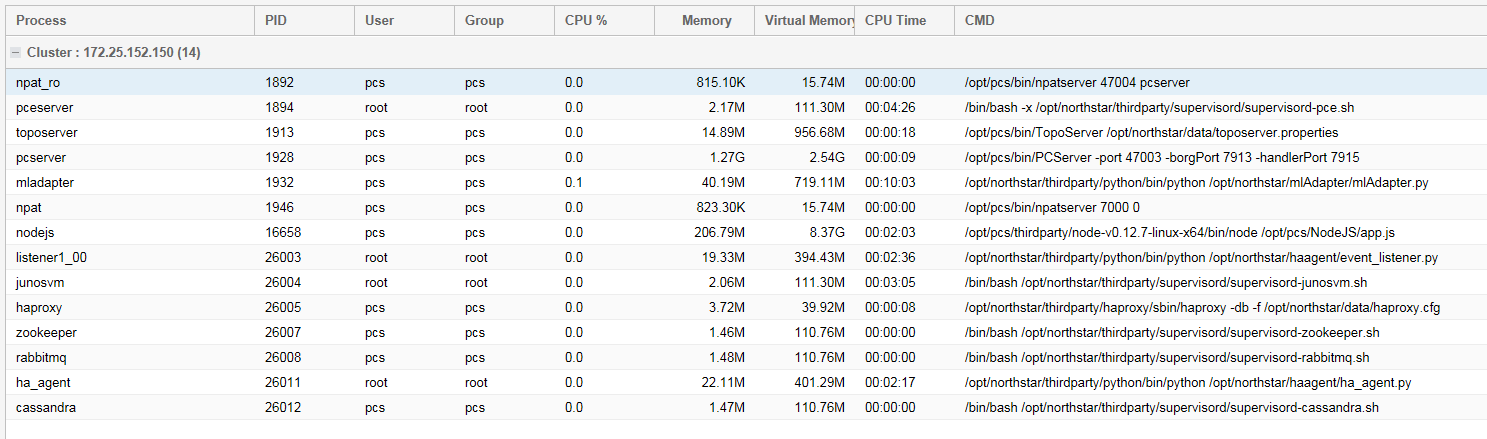
表 1 に、「プロセス状況」テーブルに表示される各フィールドを示します。
| フィールド | の説明 |
|---|---|
プロセス |
NorthStar Controller プロセスの名前。 |
Pid |
プロセス ID 番号。 |
ユーザー |
このプロセスに関する情報にアクセスするために必要なNorthStar Controllerユーザー権限。 |
グループ |
このプロセスに関する情報にアクセスするには、NorthStar Controllerユーザーグループの権限が必要です。 |
CPU% |
このプロセスによって現在使用されている CPU の現在の割合を表示します。 |
メモリ |
このプロセスによって現在使用されているメモリの現在の割合を表示します。 |
仮想メモリ |
このプロセスで使用されている現在の仮想メモリを表示します。 |
CPU 時間 |
プロセスの命令を処理するために CPU が使用された時間 |
Cmd |
システム プロセスの特定のコマンド オプションを表示します。 |
トラブルシューティング情報は、次のセクションで説明します。
NorthStar コントローラのログ ファイル
トラブルシューティング作業を通して、さまざまなNorthStar Controllerログファイルを表示すると役立つ場合があります。ログ ファイルにアクセスするには:
NorthStar Controller Web UIにログインします。
[>] に移動しMore Options、[] を選択しますLogs。 Administration
NorthStar システムのログおよびメッセージ・ファイルのリストが表示されます。その切り捨てられた例を 図 2 に示します。
図2:システムログファイルとメッセージファイルの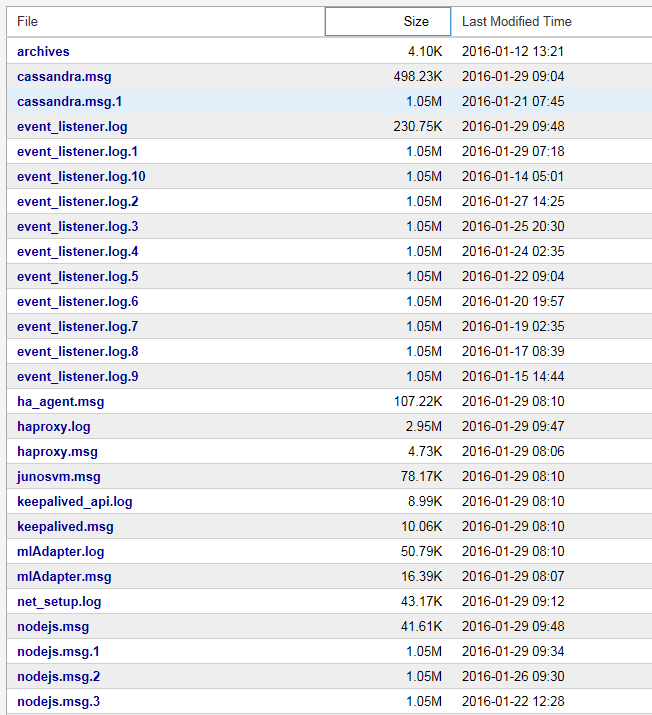 サンプル
サンプル
表示するログ・ファイルまたはメッセージ・ファイルをクリックします。
ログファイルの内容がポップアップウィンドウに表示されます。
別のブラウザウィンドウまたはタブでファイルを開くには、ポップアップウィンドウ内をクリックします View Raw Log 。
ポップアップ ウィンドウを閉じて、ログ ファイルとメッセージ ファイルのリストに戻るには、ポップアップ ウィンドウの右上隅にある [X ] をクリックします。
表 2 に、PCS および PCE の問題の特定とトラブルシューティングに最もよく使用される NorthStar Controller ログ ファイルを示します。
ログ ファイル |
説明 |
場所 |
|---|---|---|
pcep_server.log |
PCEPサーバに関連するログエントリ。PCEP サーバは PCEP セッションを維持します。ログには、PCC と PCE 間の双方向の通信に関する情報が含まれています。 詳細な PCEP サーバ ロギングを設定するには、次の手順を実行します。
|
/var/log/jnc |
pcs.log |
PC に関連するログ エントリ。PCS はパスの計算を担当します。このログには、プロビジョニング命令など、Toposerver から PC によって受信されたイベントが含まれます。また、PCの正常な起動を妨げる通信エラーや問題の通知も含まれています。 |
/opt/northstar/logs |
toposerver.log |
トポロジー・サーバーに関連したログ項目。トポロジー・サーバーは、トポロジーの保守を担当します。これらのログには、PCS とトポサーバー、トポサーバーと NTAD、およびトポサーバーと PCE サーバー間のイベントのレコードが含まれています |
/opt/northstar/logs |
表 3 に、トラブルシューティングに役立つその他のログ ファイルを示します。 表 3 のすべてのログ・ファイルは、 /opt/northstar/logs ディレクトリーの下にあります。
| ログ ファイル | 説明 |
cassandra.msg |
cassandra データベースに関連するイベントをログに記録します。 |
ha_agent.msg |
HA コーディネーター ログ |
mlAdaptor.log |
トランスポート コントローラー ログへのインターフェイス。 |
net_setup.log |
構成スクリプト ログ。 |
nodejs.msg |
nodejs に関連するイベントをログに記録します。 |
pcep_server.log |
PCC と PCE 間の双方向通信に関連するログ ファイル。 |
pcs.log |
PCS に関連するログ ファイル (PCS がトポサーバーから受信したイベントと、プロビジョニング命令を含むトポサーバーから PCS へのイベントが含まれます)。このログには、通信エラーや、PCSの正常な起動を妨げる問題も含まれています。 |
rest_api.log |
REST API リクエストのログファイル。 |
toposerver.log |
トポロジー・サーバーに関連したログ・ファイル。 PC とトポロジー・サーバー、トポロジー・サーバーと NTAD、およびトポロジー・サーバーと PCE サーバー間のイベントのレコードが含まれます。
メモ:
pcshandler.log ファイルに転送されたメッセージは、pcs.log ファイルにも転送されます。 |
Junos VM に関連するログを表示するには、ルーターへの telnet セッションを確立する必要があります。Junos VM のデフォルト IP アドレスは 172.16.16.2 です。Junos VM は、必要な BGP、ISIS、または OSPF セッションを維持する役割を担います。
空のトポロジ
図 3 は、ルーターからトポロジー サーバーへの情報フローを示しています。その結果、NorthStar Controller UI にトポロジーが表示されます。トポロジ表示が空の場合は、このフローが中断されている可能性があります。フローが中断された場所を見つけることは、問題解決プロセスの指針となります。
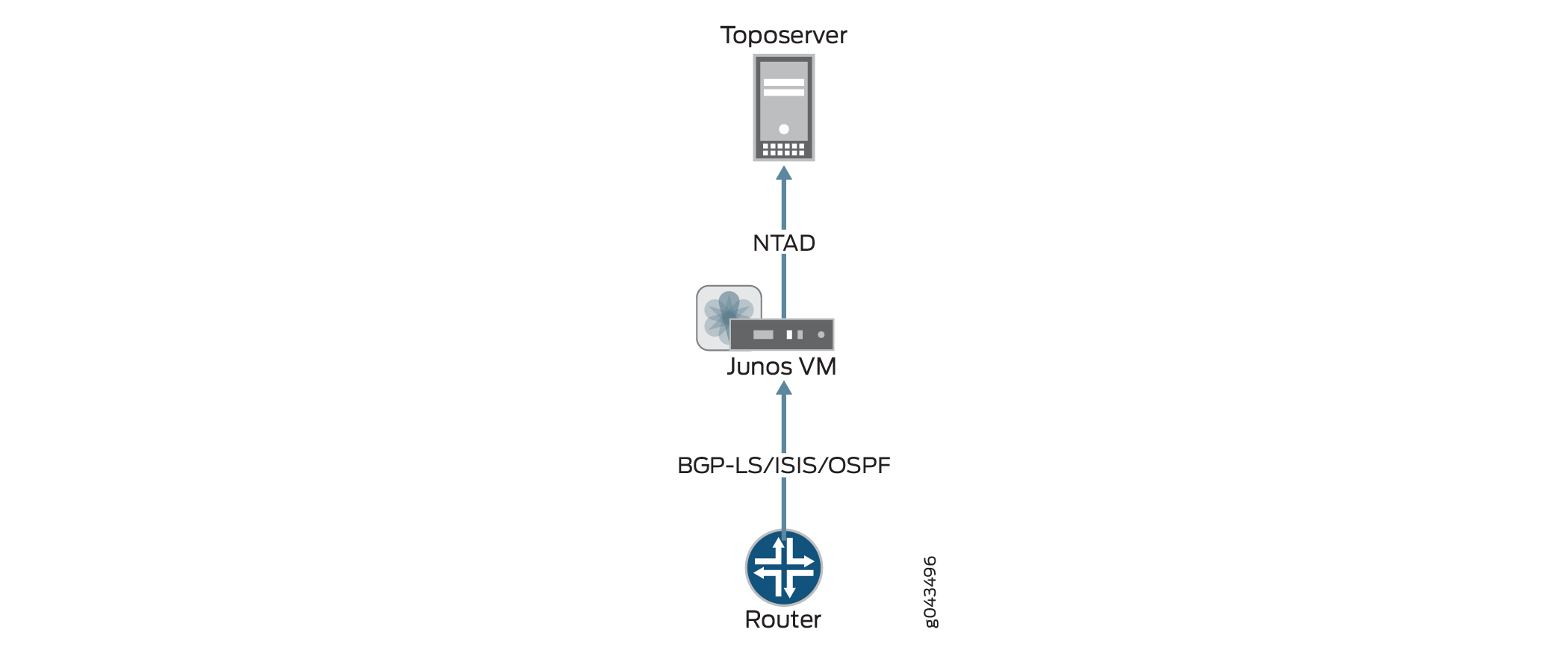
トポロジーはルーターから始まります。NorthStar Controllerがトポロジーを受信するには、ネットワーク内のルーターの1つからJunos VMへのBGP-LS、ISIS、またはOSPFセッションが必要です。また、Junos VMとToposerverの間には、確立されたネットワークトポロジー抽象デーモン(NTAD)セッションが必要です。
これらの接続を確認するには:
次の例に示すように、NorthStar Controller CLI を使用して、Toposerver と Junos VM 間の NTAD 接続が正常に確立されたことを確認します。
[root@northstar ~]# netstat -na | grep :450 tcp 0 0 172.16.16.1:55752 172.16.16.2:450 ESTABLISHED
メモ:ポート450は、Junos VMからトポサーバーへの接続に使用されるポートです。
次の例では、NTAD 接続が確立されていません。
[root@northstar ~]# netstat -na | grep :450 tcp 0 0 172.16.16.1:55752 172.16.16.2:450 LISTENING
Junos VM にログインして、NTAD がトポロジのエクスポートを有効にするように設定されているかどうかを確認します。以下のgrepコマンドにより、Junos VMのIPアドレスが表示されます。
[root@northstar ~]# grep "ntad_host" /opt/northstar/data/northstar.cfg ntad_host=172.16.16.2 [root@northstar ~]# telnet 172.16.16.2 Trying 172.16.16.2... Connected to 172.16.16.2. Escape character is '^]'. northstar_junosvm (ttyp0) login: northstar Password: --- JUNOS 14.2R4.9 built 2015-08-25 21:01:39 UTC This JunOS VM is running in non-persistent mode. If you make any changes on this JunOS VM, Please make sure you save to the Host using net_setup.py utility, otherwise the config will be lost if this VM is restarted. northstar@northstar_junosvm> show configuration protocols | display set set protocols topology-export
topology-exportステートメントが指定されていない場合、Junos VM はデータをトポサーバーにエクスポートできません。Junos OSコマンドを使用して
show、Junos VMとルーター間のBGP、ISIS、またはOSPFの関係がアクティブかどうかを確認します。セッションがアクティブでない場合、トポロジー情報をJunos VMに送信できません。Junos VM で、lsdist.0 ルーティング テーブルに次のエントリがあるかどうかを確認します。
northstar@northstar_junosvm> show route table lsdist.0 terse | match lsdist.0 lsdist.0: 54 destinations, 54 routes (54 active, 0 holddown, 0 hidden)
lsdist.0のルーティングテーブルにゼロしか表示されない場合、送信できるトポロジーはありません。トポロジー取得の設定に関する 『NorthStar Controllerスタートアップガイド 』セクションを参照してください。
lsdist.0のルーティングテーブルに少なくとも1つのリンクがあることを確認します。Topoサーバーは、少なくとも 1 つの NTAD リンク イベントを受け取った場合にのみ、初期トポロジを生成できます。他のノードとのIGP隣接関係のない単一ノードで構成されるネットワーク(たとえば、ラボ環境で可能)では、Toposerverはトポロジを生成できません。 図 4 は、初期トポロジを作成するための Toposerver の論理プロセスを示しています。
図4: 初期トポロジ作成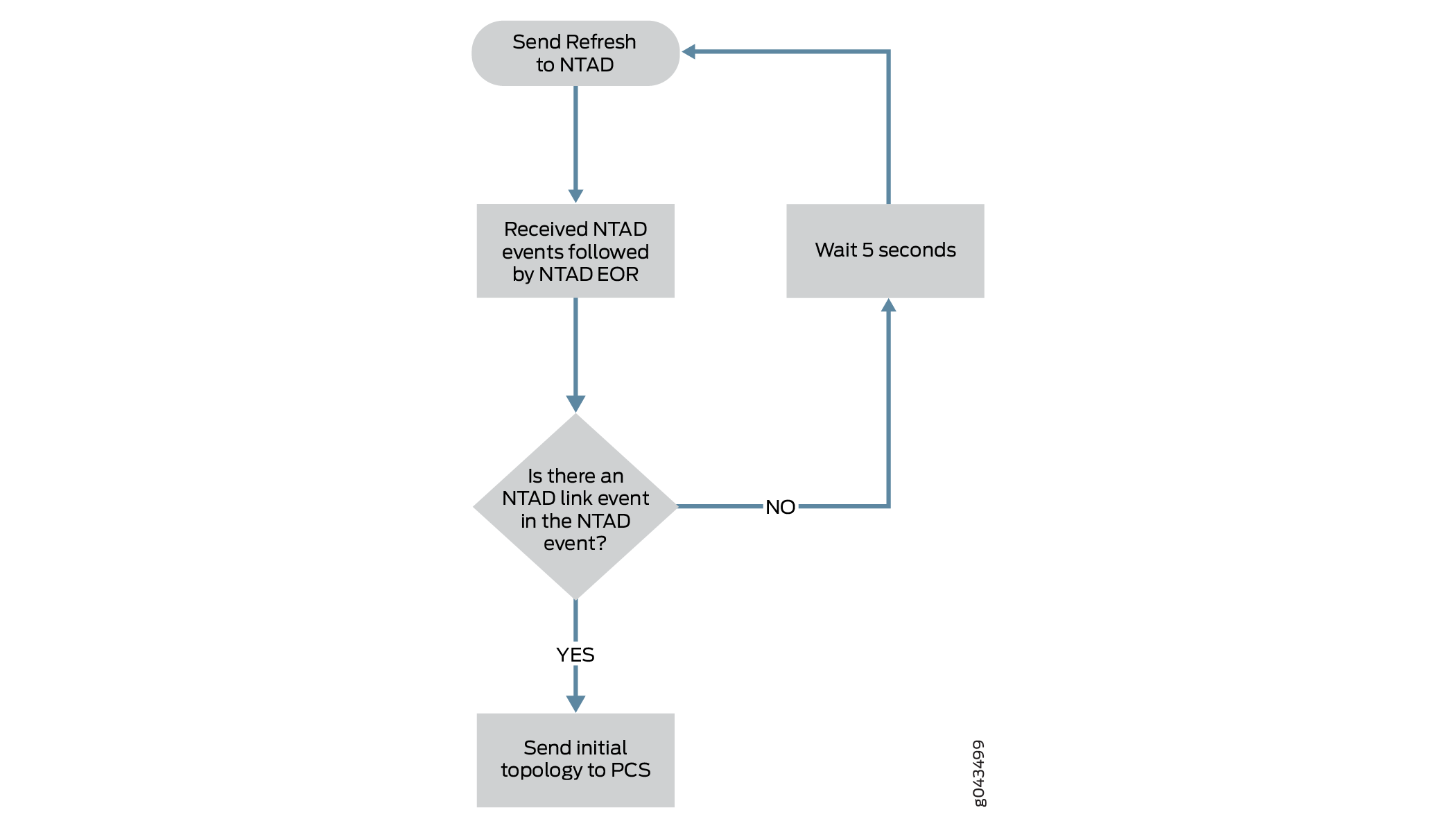 の論理プロセス
の論理プロセス
この理由で初期トポロジを作成できない場合、toposerver.logは次の例のようなエントリを生成します。
Dec 9 16:03:57.788514 fe-cluster-03 TopoServer Did not send the topology because no links were found.
NTADバージョン
SR LSP がプロビジョニングされておらず、pcs.logに次の例のようなメッセージが表示される場合:
2020 Apr 27 15:05:36.430366 ns1-site1-q-pod07 PCServer [NorthStar][PCServer][Routing] msg=0x0000300b Provided path is not valid for SR for sean427@0110.0000.0101 path=sean427, node 0110.0000.0104 has no NodeIndex
NTADのバージョンが正しくない可能性があります。NTADバージョンの詳細については 、NorthStarコントローラのインストール を参照してください。
不正なトポロジー
Toposerver の重要な機能の 1 つは、NTAD リンク イベントからの送信元と宛先の IPv4 Link_Identifiersを照合することによって、ルーターからの単方向リンク(インターフェイス)情報を双方向リンクに関連付けることです。NorthStar UIに表示されるトポロジーが正しくないと思われる場合は、Toposerverが双方向リンクの生成とメンテナンスをどのように処理するかを理解しておくと役立つ場合があります。
双方向リンクの生成と維持は複雑なプロセスですが、以下の重要なポイントをご紹介します。
各双方向リンクを構成する 2 つのノードでは、最初に割り当てられた(したがってノード ID 番号が小さい)ノード ID にノード A 指定が与えられ、もう一方のノードにはノード Z 指定が与えられます。
メモ:ノード ID は、トポサーバーが最初に NTAD からノード イベントを受信するときに割り当てられます。
ノード ID がクリアされて再割り当てされるたびに (Toposerver の再起動中やネットワーク モデルのリセット中など)、ノード ID、したがって A と Z の指定が変更される可能性があります。
Toposerver は、ネットワーク内のリンクが追加または変更されると、リンク更新メッセージを受信します。
Toposerver は、リンクがネットワークから削除されると、リンク撤回メッセージを受信します。
リンク更新およびリンク取り消しメッセージは、ノードの運用状況に影響を与えます。
ノードの運用ステータスとプロトコル(IGP 対 IGP と MPLS)によって、リンクを使用して LSP をルーティングできるかどうかが決まります。リンクを使用してLSPをルーティングするには、動作ステータスUPとMPLSプロトコルの両方がアクティブである必要があります。
LSPの欠落
トポロジーが正しく表示されているにもかかわらずLSPが欠落している場合は、 図5に示すように、PCCからトポサーバーへの情報フローを確認します。その結果、NorthStar Controller UIにトンネルが追加されています。フローは PCC での設定から始まり、LSP アップデート メッセージが PCEP セッションを介して PCEP サーバに渡され、次に AMQP(アドバンスト メッセージ キューイング プロトコル)接続を介してトポサーバに渡されます。
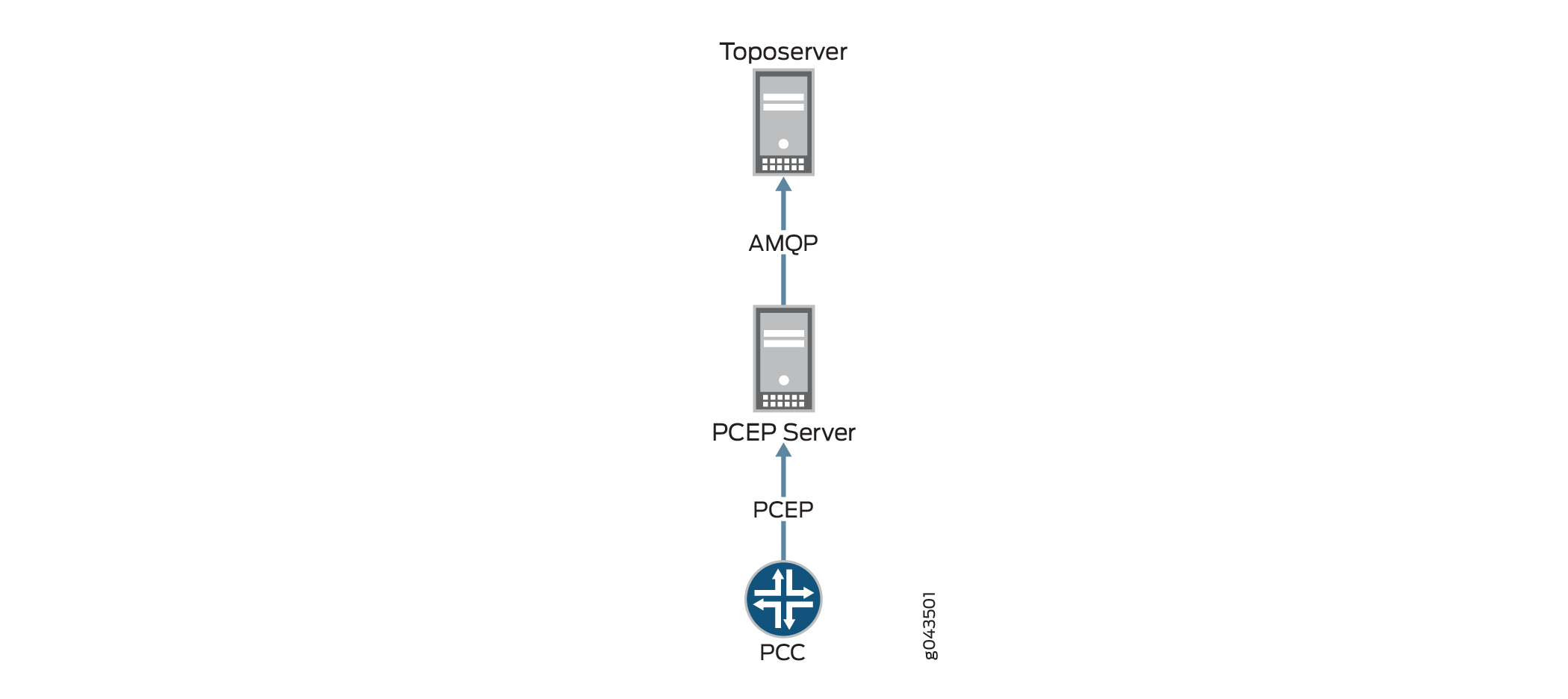
これらの接続を確認するには:
toposerver.logを見てください。ログは、PCEP サーバとの接続が失われたか、正常に確立されなかったことを検出すると、15 秒ごとにメッセージを出力します。次の例では、トポサーバと PCEP サーバ間の接続がダウンとしてマークされていることに注意してください。
Toposerver log: Apr 22 16:21:35.016721 user-PCS TopoServer Warning, did not receive the PCE beacon within 15 seconds, marking it as down. Last up: Fri Apr 22 16:21:05 2016 Apr 22 16:21:35.016901 user-PCS TopoServer [->PCS] PCE Down: Warning, did not receive the PCE beacon within 15 seconds, marking it as down. Last up: Fri Apr 22 16:21:05 2016 Apr 22 16:21:50.030592 user-PCS TopoServer Warning, did not receive the PCE beacon within 15 seconds, marking it as down. Last up: Fri Apr 22 16:21:05 2016 Apr 22 16:21:50.031268 user-PCS TopoServer [->PCS] PCE Down: Warning, did not receive the PCE beacon within 15 seconds, marking it as down. Last up: Fri Apr 22 16:21:05 2016
NorthStar コントローラの CLI を使用して、この例に示すように、PCC と PCEP サーバ間の PCEP セッションが正常に確立されたことを確認します。
[root@northstar ~]# netstat -na | grep :4189 tcp 0 0 0.0.0.0:4189 0.0.0.0:* LISTEN tcp 0 0 172.25.152.42:4189 172.25.155.50:59143 ESTABLISHED tcp 0 0 172.25.152.42:4189 172.25.155.48:65083 ESTABLISHED
メモ:ポート 4189 は、PCC から PCEP サーバーへの接続に使用されるポートです。
セッションが確立されたことを知ることは有用ですが、必ずしもデータが転送されたことを意味するわけではありません。
PCEPサーバがPCCからLSPについて学習したかどうかを確認します。
[root@user-PCS ~]# pcep_cli # show lsp all list 2016-04-22 17:09:39.696061(19661)[DEBUG]: pcc_lsp_table.begin: 2016-04-22 17:09:39.696101(19661)[DEBUG]: pcc-id:1033771436/172.25.158.61, state: 0 2016-04-22 17:09:39.696112(19661)[DEBUG]: START of LSP-NAME-TABLE … 2016-04-22 17:09:39.705358(19661)[DEBUG]: Summary pcc_lsp_table: 2016-04-22 17:09:39.705366(19661)[DEBUG]: Summary LSP name tabl: 2016-04-22 17:09:39.705375(19661)[DEBUG]: client_id:1033771436/172.25.158.61, state:0,num LSPs:13 2016-04-22 17:09:39.705388(19661)[DEBUG]: client_id:1100880300/172.25.158.65, state:0,num LSPs:6 2016-04-22 17:09:39.705399(19661)[DEBUG]: client_id:1117657516/172.25.158.66, state:0,num LSPs:23 2016-04-22 17:09:39.705410(19661)[DEBUG]: client_id:1134434732/172.25.158.67, state:0,num LSPs:4 2016-04-22 17:09:39.705420(19661)[DEBUG]: Summary LSP id table: 2016-04-22 17:09:39.705429(19661)[DEBUG]: client_id:1033771436/172.25.158.61, state:0, num LSPs:13 2016-04-22 17:09:39.705440(19661)[DEBUG]: client_id:1100880300/172.25.158.65, state:0, num LSPs:6 2016-04-22 17:09:39.705451(19661)[DEBUG]: client_id:1117657516/172.25.158.66, state:0, num LSPs:23 2016-04-22 17:09:39.705461(19661)[DEBUG]: client_id:1134434732/172.25.158.67, state:0, num LSPs:4
出力の右端の列には、学習されたLSPの数が表示されます。この数値が 0 の場合、LSP 情報は PCEP サーバに送信されませんでした。その場合は、 『NorthStar Controller Getting Started Guide』の説明に従って、PCC 側の設定を確認してください。
LSP コントローラのステータス
LSP Controller Status のコントローラステータスは、(NorthStar コントローラ GUI の)ネットワーク情報テーブル の トンネル タブの 列で確認できます。
表 4 に、さまざまなコントローラのステータスとその説明を示します。
コントローラのステータス |
は、 |
|---|---|
失敗 しました |
NorthStar Controller は LSP のプロビジョニングに失敗しました。 |
保留 中 |
PCS は、LSP プロビジョニング オーダーを PCEP サーバーに送信しました。PCS は PCEP サーバからの応答を待機しています。 |
PCC_PENDING |
PCEP サーバが LSP プロビジョニング オーダーを PCC に送信しました。PCS は PCC からの応答を待っています。 |
NETCONF_PENDING |
PCS が LSP プロビジョニング命令を netconfd に送信しました。PCS は netconfd からの応答を待っています。 |
PRPD_PENDING |
PCS は、BGP ルートをプロビジョニングするために、PRPD クライアントに LSP プロビジョニング オーダーを送信しました。PCS は、PRPD クライアントからの応答を待機しています。 |
SCHEDULED_DELETE |
PCS は LSP の削除をスケジュールしました。PCS は削除プロビジョニング順序を PCC に送信します。 |
SCHEDULED_DISCONNECT |
PCS は LSP を切断するようにスケジュールしました。LSP はシャットダウン ステータスに移行します。LSP は、永続状態が関連付けられた NorthStar データストアに保持され、CSPF の計算では使用されません。 |
NoRoute_Rescheduled |
PCS は LSP のパスを見つけていません。PCS は LSP を定期的にスキャンし、ルーティングされていない LSP のパスを見つけてから、再プロビジョニングをスケジュールします。 |
FRR_DETOUR_Rescheduled |
PCS は LSP を迂回し、LSP の再プロビジョニングを再スケジュールしました。 |
Provision_Rescheduled |
PCS は、プロビジョニングされる LSP をスケジュールしました。 |
Maint_NotHandled |
LSPはNorthStarによって制御されていないため、LSPは継続的なメンテナンスイベントの一部ではありません。 |
Maint_Rerouted |
PCS はメンテナンスのため LSP を再ルーティングしました。 |
Callsetup_Scheduled |
PCS は、イベントの開始時に LSP をプロビジョニングする必要があります。 |
Disconnect_Scheduled |
イベントが終了したら、PCS は LSP を切断する必要があります。 |
パスが見つかりません |
PCS は LSP のパスを見つけることができませんでした。 |
ダウン LSP で見つかったパス |
PCEP サーバーは LSP がダウンしていることを報告しましたが、PCS は LSP のパスを見つけました。 |
パスインクルードループ |
SR-LSP には 1 つ以上のループがあります。 |
Maint_NotReroute_DivPathUp |
スタンバイ パスがすでに稼働しているため、メンテナンス イベントによって LSP が再ルーティングされることはありません。 |
Maint_NotReroute_NodeDown |
メンテナンスイベントはLSPのエンドポイント向けであるため、LSPは再ルーティングされません。 |
PLANNED_LSP |
LSP はプロビジョニングする必要がありますが、まだプロビジョニング キューにありません。 |
PLANNED_DISCONNECT |
LSP は切断する必要がありますが、まだプロビジョニング キューにありません。 |
PLANNED_DELETE |
LSP は削除する必要がありますが、まだプロビジョニング キューにありません。 |
Candidate_ReOptimization |
PCS は、LSP を再最適化の候補として選択しました。 |
アクティベート(used_by_primary) |
LSP のセカンダリパスがアクティブになります。 |
Time_Expired |
LSP のスケジュールされたウィンドウが期限切れになりました。 |
PCEP_Capability_not_supported |
PCEP がデバイスでサポートされていないか、サポートされている場合でも、PCEP が設定されていないか、無効になっているか、またはデバイスで正しく設定されていない可能性があります。 |
非アクティブ化 |
NorthStar Controllerは、セカンダリLSPを非アクティブ化しました。 |
NS_ERR_NCC_NOT_FOUND |
NorthStar コントローラは、Netconf Connection Client(NCC)を使用してデバイスへのNetconf接続を確立できません。回避策: NorthStarサーバーでNetconfを再起動します。 [root@pcs-1 templates]# supervisorctl restart netconf netconf:netconf: stopped netconf:netconf: started |
SR LSPのプロビジョニングには、LSPステートフルSR機能が必要 |
SR LSPをプロビジョニングするには、CLIを使用してJunosデバイスで次のコマンドを設定する必要があります。 set protocols pcep pce <name> spring-capability |
PCEP 非対応の PCC
トポロジーサーバは、ノードを PCEP 対応にするために、PCEP セッションを TED からのトポロジ内のノードに関連付けます。PCC が PCEP セッションを確立するために使用する IP アドレスが、トポサーバが TED から自動的に学習した IP アドレスでない場合、このトポサーバ機能は妨げられます。例えば、管理 IP アドレスを使用して PCEP セッションが確立された場合、トポサーバは TED からその IP アドレスを受信しません。
PCC は、PCEP セッションを正常に確立すると、PCC_SYNC_COMPLETE メッセージをトポサーバに送信します。このメッセージは、同期が完了したことを NorthStar に示します。以下は、対応するtoposerverログエントリのサンプルで、NorthStarが認識する場合と認識しない場合があるPCC_SYNC_COMPLETEメッセージとPCEP IPアドレスの両方を示しています。
Dec 9 17:12:11.610225 fe-cluster-03 TopoServer NSTopo::updateNode (PCCNodeEvent) ip: 172.25.155.26 pcc_ip: 172.25.155.26 evt_type: PCC_SYNC_COMPLETE Dec 9 17:12:11.610230 fe-cluster-03 TopoServer Adding PCEP flag to pcep_ip: 172.25.155.26 node_id: 0880.0000.0026 router_ID: 10.0.0.26 protocols: 4 Dec 9 17:12:11.610232 fe-cluster-03 TopoServer Setting live pcep_ip: 172.25.155.26 for router_ID: 88.0.0.26
認識されないIPアドレスの問題を修正するためのいくつかのオプションは次のとおりです。
>に移動して、NorthStar Web UI More Options のデバイスプロファイル> Administration Device Profile認識できないIPアドレスを手動で入力します。
ルーターで発信されている LSP が少なくとも 1 つあることを確認し、これにより Toposerver が PCEP セッションを TED データベース内のノードに関連付けることができます。
IP アドレスの問題が解決され、Toposerver が PCEP セッションをトポロジ内のノードに正常に関連付けることができると、PCS ログで確認できるように、PCEP IP アドレスがノード属性に追加されます。
Dec 9 17:12:11.611392 fe-cluster-03 PCServer [<-TopoServer] routing_key = ns_node_update_key Dec 9 17:12:11.611394 fe-cluster-03 PCServer [<-TopoServer] NODE UPDATE(Live): ID=0880.0000.0026 protocols=(20)ISIS2,PCEP status=UNKNOWN hostname=skynet_26 router_ID=88.0.0.26 iso=0880.0000.0026 isis_area=490001 AS=41 mgmt_ip=172.25.155.26 source=NTAD Hostname=skynet_26 pcep_ip=172.25.155.26
LSP が保留中またはPCC_PENDING状態でスタックしている
ノードがPCEP対応として正しく確立されると、LSPのプロビジョニングを開始できます。LSP コントローラのステータスは、Web UI ネットワーク情報テーブル(コントローラのステータス列)の トンネル タブに表示されるように、保留中またはPCC_PENDINGを示すことができます。このセクションでは、これらのステータスを解釈する方法について説明します。
LSP がプロビジョニングされると、PCS サーバは LSP のすべての要件を満たすパスを計算し、プロビジョニング順序を PCEP サーバに送信します。このプロセスの実行中に、次の例のようなログ メッセージが PCS ログに表示されます。
Apr Apr 25 10:06:44.798336 user-PCS PCServer [->TopoServer] push lsp configlet, action=ADD
Apr 25 10:06:44.798341 user-PCS PCServer {#012"lsps":[#012{"request-id":928380025,"name":"JTAC","from":"10.0.0.102",
"to":"10.0.0.104","pcc":"172.25.158.66","bandwidth":"100000","metric":0,"local-protection":false,"type":"primary",
"association-group-id":0,"path-attributes":{"admin-group":{"exclude":0,"include-all":0, "include-any":0},"setup-priority":
7,"reservation-priority":7,"ero":[{"ipv4-address":"10.102.105.2"},{"ipv4-address":"10.105.107.2"}, {"ipv4-address":
"10.114.117.1"}]}}#012]#012}
Apr 25 10:06:44.802500 user-PCS PCServer provisioning order sent, status = SUCCESS
Apr 25 10:06:44.802519 user-PCS PCServer [->TopoServer] Save LSP action, id=928380025 event=Provisioning Order(ADD) sent request_id=928380025
Apr 25 10:06:44.802534 user-PCS PCServer lsp action=ADD JTAC@10.0.0.102 path= controller_state=PENDING
この時点では、LSP コントローラのステータスは PENDING であり、プロビジョニング命令は PCEP サーバに送信されましたが、確認応答はまだ受信されていないことを意味します。LSP が PENDING でスタックしている場合は、PCEP サーバに問題があることを示しています。PCEPサーバーにログインし、考えられるトラブルシューティング値の追加情報を提供できる詳細ログメッセージを設定できます。
pcep_cli set log-level all
PCEPサーバには、有用な情報を表示できるさまざまな show コマンドもあります。Junos OSの構文と同様に、 を入力する show ? とコマンドオプション show が表示されます。
PCEP サーバは、プロビジョニング順序を正常に受信すると、次の 2 つのアクションを実行します。
注文が PCC に転送されます。
確認応答を PCS に送り返します。
PCEP サーバ ログには、次の例のようなエントリが表示されます。
2016-04-25 10:06:45.196263(27897)[EVENT]: 172.25.158.66:JTAC UPD RCVD FROM PCC, ack 928380025 2016-04-25 10:06:45.196517(27897)[EVENT]: 172.25.158.66:JTAC ADD SENT TO PCS 928380025, UP
LSP コントローラのステータスが [PCC_PENDING] に変わり、PCEP サーバがプロビジョニング命令を受信して PCC に転送したが、PCC がまだ応答していないことを示します。LSP が PCC_PENDING でスタックしている場合は、PCC に問題があることを示しています。
PCC がプロビジョニング順序を正常に受信すると、PCEP サーバに応答が送信され、PCEP サーバが応答を PCS に転送します。PCS がこの応答を受信すると、LSP コントローラのステータスが完全にクリアされ、LSP が完全にプロビジョニングされており、PCEP サーバまたは PCC からのアクションを待機していないことを示します。その後、動作ステータス([運用ステータス]列)がトンネルの状態を示すインジケータになります。
PCS ログには、次の例のようなエントリが表示されます。
Apr 25 10:06:45.203909 user-PCS PCServer [<-TopoServer] JTAC@10.0.0.102, LSP event=(0)CREATE request_id=928380025 tunnel_id=9513 lsp_id=1 report_type=ACK
非アクティブな LSP
LSP プロビジョニング順序が正常に送信および確認され、コントローラのステータスがクリアされた場合でも、LSP が稼働していない可能性があります。LSP の動作ステータスが DOWN の場合、PCC は LSP にシグナリングできません。このセクションでは、LSP の運用ステータスが DOWN になる理由をいくつか考えていきます。
使用率は、DOWN でスタックしている LSP に関連する重要な概念です。利用には 2 つのタイプがあり、特定の時点では互いに異なっていてもかまいません。
ライブ使用率—このタイプは、LSPパスをシグナリングするためにネットワーク内のルーターによって使用されます。このタイプの使用率は、NTADを介してTEDから学習されます。次の例のような PCS ログ エントリが表示される場合があります。特に、リンク上のRSVP使用率をアドバタイズする予約可能な帯域幅(reservable_bw)エントリに注意してください。
Apr 25 10:10:11.475686 user-PCS PCServer [<-TopoServer] LINK UPDATE: ID=L10.105.107.1_10.105.107.2 status=UP nodeA=0110.0000.0105 nodeZ=0110.0000.0107 protocols=(260)ISIS2,MPLS Apr 25 10:10:11.475690 user-PCS PCServer [A->Z] ID=L10.105.107.1_10.105.107.2 IP address=10.105.107.1 bw=10000000000 max_rsvp_bw=10000000000 te_metric=10 color=0 reservable_bw={9599699968 8599699456 7599699456 7599699456 7599699456 7599699456 7599699456 7099599360 } Apr 25 10:10:11.475694 user-PCS PCServer [Z->A] ID=L10.105.107.1_10.105.107.2 IP address=10.105.107.2 bw=10000000000 max_rsvp_bw=10000000000 te_metric=10 color=0 reservable_bw={10000000000 10000000000 10000000000 8999999488 7899999232 7899999232 7899999232 7899999232 }計画使用率—このタイプは、パス計算のためにNorthStar Controller内で使用されます。この使用率は、ルーターがLSPをアドバタイズし、LSP帯域幅とLSPが使用するパスをNorthStarに通信するときに、PCEPから学習されます。次の例のような PCS ログ エントリが表示される場合があります。特に、リンク上のRSVP使用率をアドバタイズする帯域幅(bw)とレコードルートオブジェクト(RRO)エントリに注意してください。
Apr 25 10:06:45.208021 ns-PCS PCServer [<-TopoServer] routing_key = ns_lsp_link_key Apr 25 10:06:45.208034 ns-PCS PCServer [<-TopoServer] JTAC@10.0.0.102, LSP event=(2)UPDATE request_id=0 tunnel_id=9513 lsp_id=1 report_type=STATE_CHANGE Apr 25 10:06:45.208039 ns-PCS PCServer JTAC@10.0.0.102, lsp add/update event lsp_state=ACTIVE admin_state=UP, delegated=true Apr 25 10:06:45.208042 ns-PCS PCServer from=10.0.0.102 to=10.0.0.104 Apr 25 10:06:45.208046 ns-PCS PCServer primary path Apr 25 10:06:45.208049 ns-PCS PCServer association.group_id=128 association_type=1 Apr 25 10:06:45.208052 ns-PCS PCServer priority=7/7 bw=100000 metric=30 Apr 25 10:06:45.208056 ns-PCS PCServer admin group bits exclude=0 include_any=0 include_all=0 Apr 25 10:06:45.208059 ns-PCS PCServer PCE initiated Apr 25 10:06:45.208062 ns-PCS PCServer ERO=0110.0000.0102--10.102.105.2--10.105.107.2--10.114.117.1 Apr 25 10:06:45.208065 ns-PCS PCServer RRO=0110.0000.0102--10.102.105.2--10.105.107.2--10.114.117.1 Apr 25 10:06:45.208068 ns-PCS PCServer samepath, state changed
2 つの使用率が互いに十分に異なるため、パスの計算の成功やシグナリングに干渉する可能性があります。たとえば、計画された使用率がライブ使用率よりも高い場合、PCS がパスの余地がないと見なしてパスを計算できないというパス計算の問題が発生する可能性があります。ただし、計画された使用率は実際のライブ使用率よりも高いため、余地が十分にある可能性があります。
また、計画された使用率がライブ使用率よりも低くなる可能性もあります。その場合、PCCはパスの余地がないと判断するため、パスをシグナリングしません。
Web UI トポロジ マップで使用率を表示するには、[トポロジ] ビューの左側のペインにある [オプション] に移動します。RSVP ライブ使用率を選択した場合、トポロジ マップにはルータからのライブ使用率が反映されます。RSVP使用率を選択した場合、トポロジマップには、計画されたプロパティに基づいてNorthStarコントローラによって計算される計画された使用率が反映されます。
Web UI のより優れたトラブルシューティング ツールは、[ダッシュボード] ビューの [ネットワーク モデル監査] ウィジェットです。[RSVP 使用率のリンク] 行項目は、ライブ使用率と計画使用率の間に不一致があるかどうかを反映します。存在する場合は、Web UI から [ネットワーク モデルの同期] を実行して Administration 、> System Settingsに移動し、結果のウィンドウの右上隅をクリックして Advanced Settings みることができます。
右上隅のボタンが と Advanced Settingsを切り替えますGeneral Settings。
PCS がトポサーバーと同期していない
PCS が Toposerver と同期しなくなり、LSP の状態が一致しない場合、同期を復元するには、PCEP プロトコルを非アクティブ化してから再アクティブ化する必要があります。NorthStar サーバーで次の手順を実行します。
次の手順に従うことに注意してください。
問題がある PCC だけでなく、すべての PCC の PCEP セッションを強制終了します。
すべてのユーザー データが失われるため、再入力が必要になります。
再同期により本番システムに影響する。
PCE サーバーを停止し、PCC が残留 LSP をすべて削除するまで 10 秒間待ちます。
supervisorctl stop northstar:pceserver
PCE サーバーを再起動します。
supervisorctl start northstar:pceserver
トポサーバーを再起動します。
supervisorctl restart northstar:toposerver
メモ:Toposerverを再起動する別の方法は、NorthStar Controller web UI(Administration>System Settings、詳細)からネットワークモデルのリセットを実行することです。および Reset Network Model 操作の詳細についてはSync Network Model、「消える変更」セクションを参照してください。
消える変化
Web UI では、トポロジをライブ ネットワークと同期するための 2 つのオプションを使用できます。これらのオプションはシステム管理者のみが使用でき、最初に > System Settingsに移動しAdministration、結果のウィンドウの右上隅をクリックAdvanced Settingsすることでアクセスできます。
右上隅のボタンが と Advanced Settingsを切り替えますGeneral Settings。
図 6 に、表示される 2 つのオプションを示します。
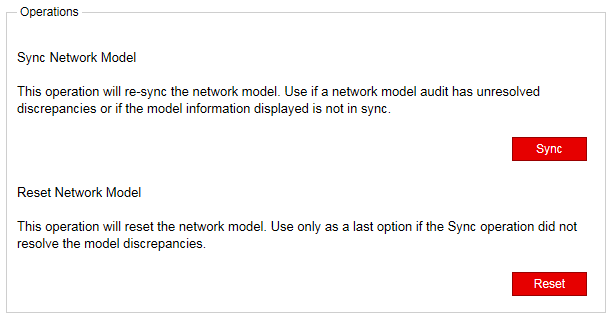
Web UI で [ネットワーク モデルのリセット] を実行すると、データベースに加えた変更が失われることに注意してください。マルチユーザー環境では、1 人のユーザーが他のユーザーに気付かれることなくネットワーク モデルをリセットする可能性があります。リセットが要求されると、要求は PCS サーバーからトポサーバーに送信され、PCS ログには次の内容が反映されます。
Apr 25 10:54:50.385008 user-PCS PCServer [->TopoServer] Request topology reset
Toposerver ログには、データベース要素が削除されていることが反映されます。
Apr 25 10:54:50.386912 user-PCS TopoServer Truncating pcs.links... Apr 25 10:54:50.469722 user-PCS TopoServer Truncating pcs.nodes... Apr 25 10:54:50.517501 user-PCS TopoServer Truncating pcs.lsps... Apr 25 10:54:50.753705 user-PCS TopoServer Truncating pcs.interfaces... Apr 25 10:54:50.806737 user-PCS TopoServer Truncating pcs.facilities...
トポロジーノードとリンクを取得するためにJunos VMとの同期を要求し、LSPを取得するためにPCEPサーバーとの同期を要求します。このようにして、Toposerver はトポロジを再学習しますが、ユーザーの更新が欠落しています。 図 7 は、トポロジーのリセット要求から Junos VM および PCEP サーバーとの同期要求までのフローを示しています。
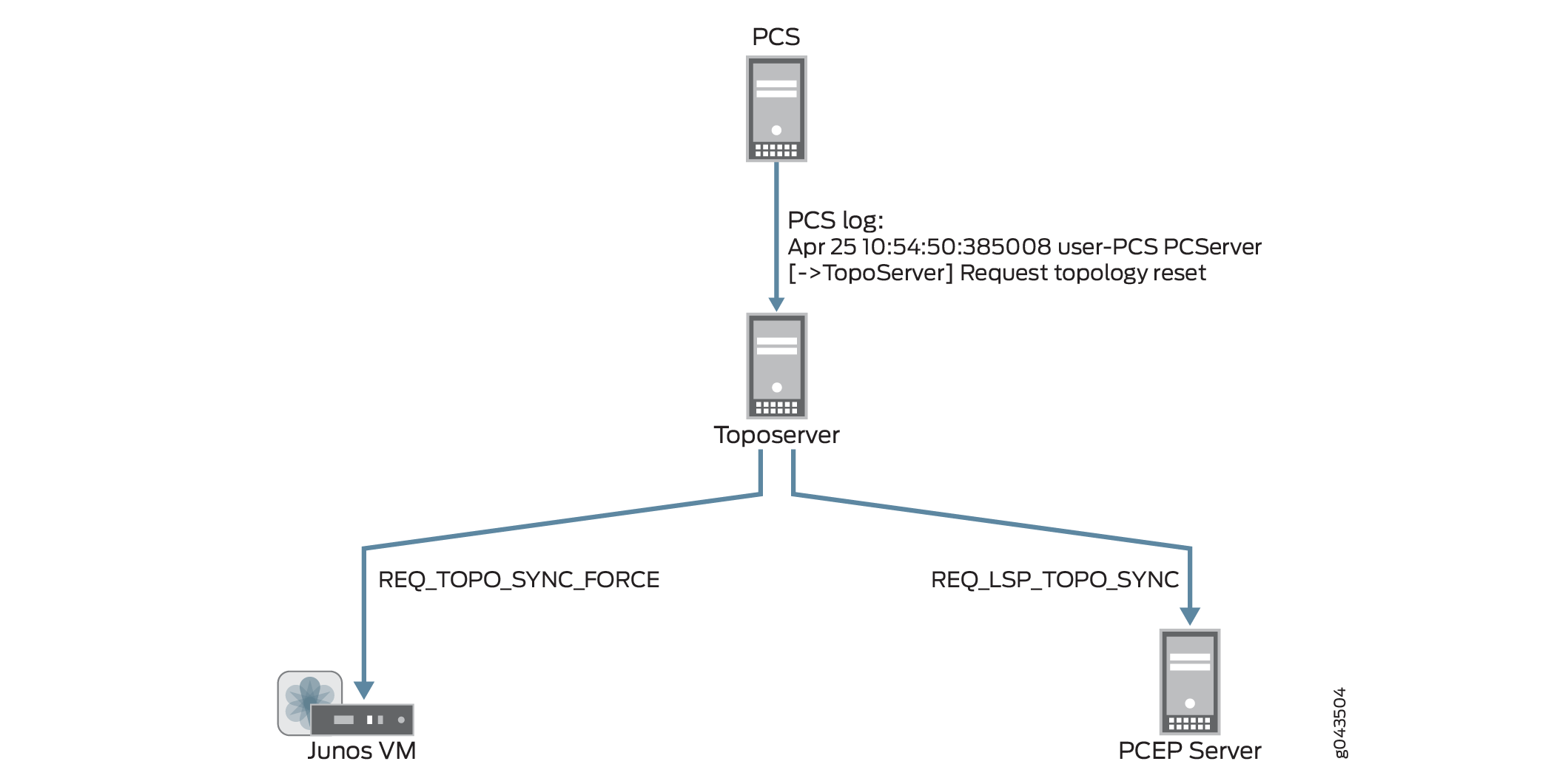 のリセット
のリセット
同期リクエストを受信すると、Junos VMとPCEPサーバーは、現在のライブネットワークを反映したトポロジーの更新を返します。PCS ログには、次の情報がデータベースに追加されていることが示されます。
Apr 25 10:54:52.237882 user-PCS PCServer [<-TopoServer] Update Topology Apr 25 10:54:52.237894 user-PCS PCServer [<-TopoServer] Update Topology Persisted Nodes (0) Apr 25 10:54:52.238957 user-PCS PCServer [<-TopoServer] Update Topology Live Nodes (7) Apr 25 10:54:52.242336 user-PCS PCServer [<-TopoServer] Update Topology Persisted Links (0) Apr 25 10:54:52.242372 user-PCS PCServer [<-TopoServer] Update Topology live Links (10) Apr 25 10:54:52.242556 user-PCS PCServer [<-TopoServer] Update Topology Persisted Facilities (1) Apr 25 10:54:52.242674 user-PCS PCServer [<-TopoServer] Update Topology Persisted LSPs (0) Apr 25 10:54:52.279716 user-PCS PCServer [<-TopoServer] Update Topology Live LSPs (47) Apr 25 10:54:52.279765 user-PCS PCServer [<-TopoServer] Update Topology Finished
図 8 は、Junos VM と PCEP サーバーからトポサーバーと PC にトポロジーの更新が返される様子を示しています。
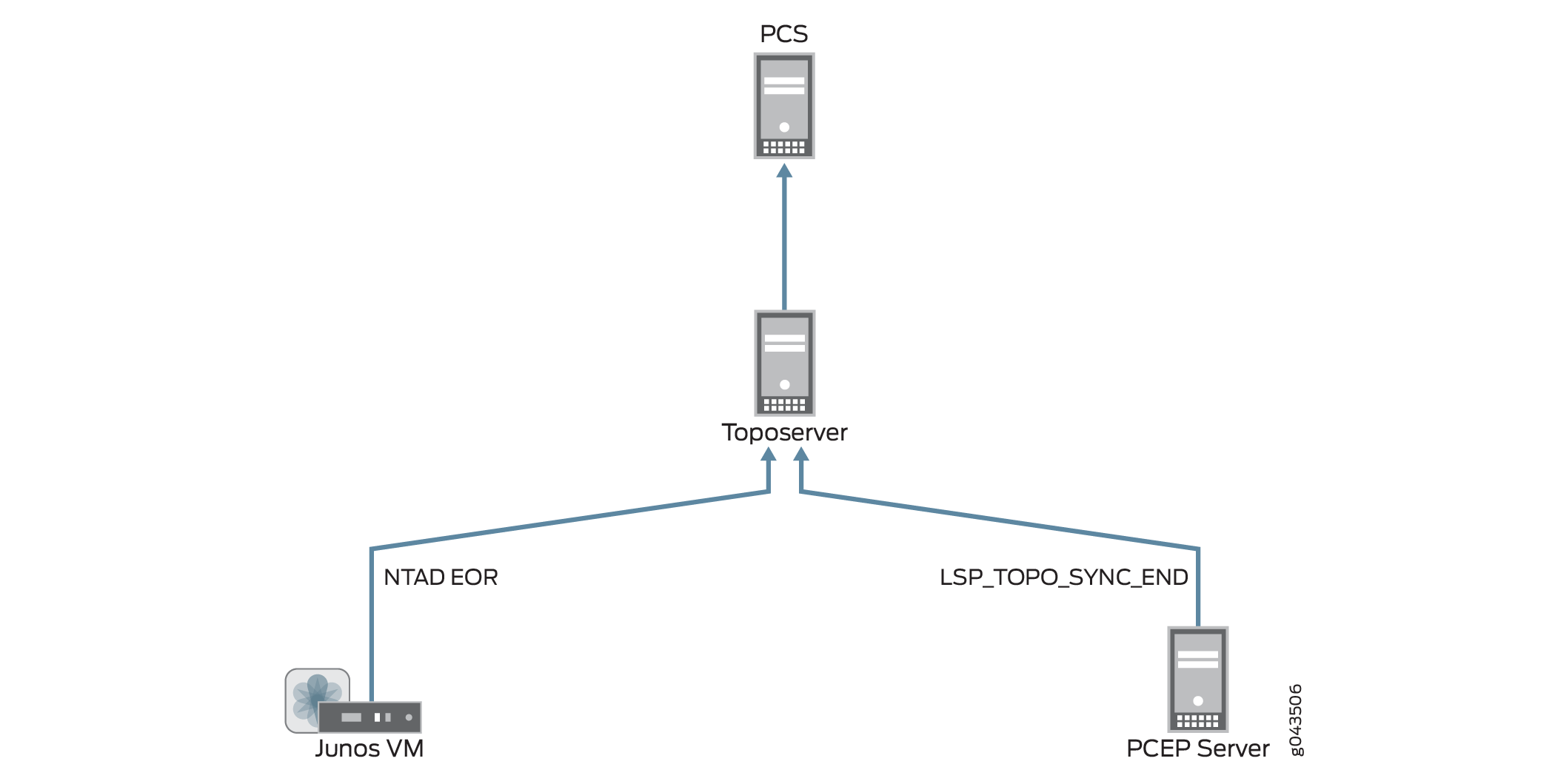 リセットを使用したモデルの更新
リセットを使用したモデルの更新
トポロジを最初からやり直す場合は [ネットワーク モデルのリセット] を使用する必要がありますが、稼働中のネットワークと同期するときにユーザー プランニング データを失いたくない場合は、代わりに [ネットワーク モデルの同期] 操作を実行します。この操作では、PCS は引き続きトポロジ同期を要求しますが、Toposerver は既存の要素を削除しません。 図 9 は、PC から Junos VM および PCEP サーバーへのフローと、更新が Toposerver に戻される様子を示しています。
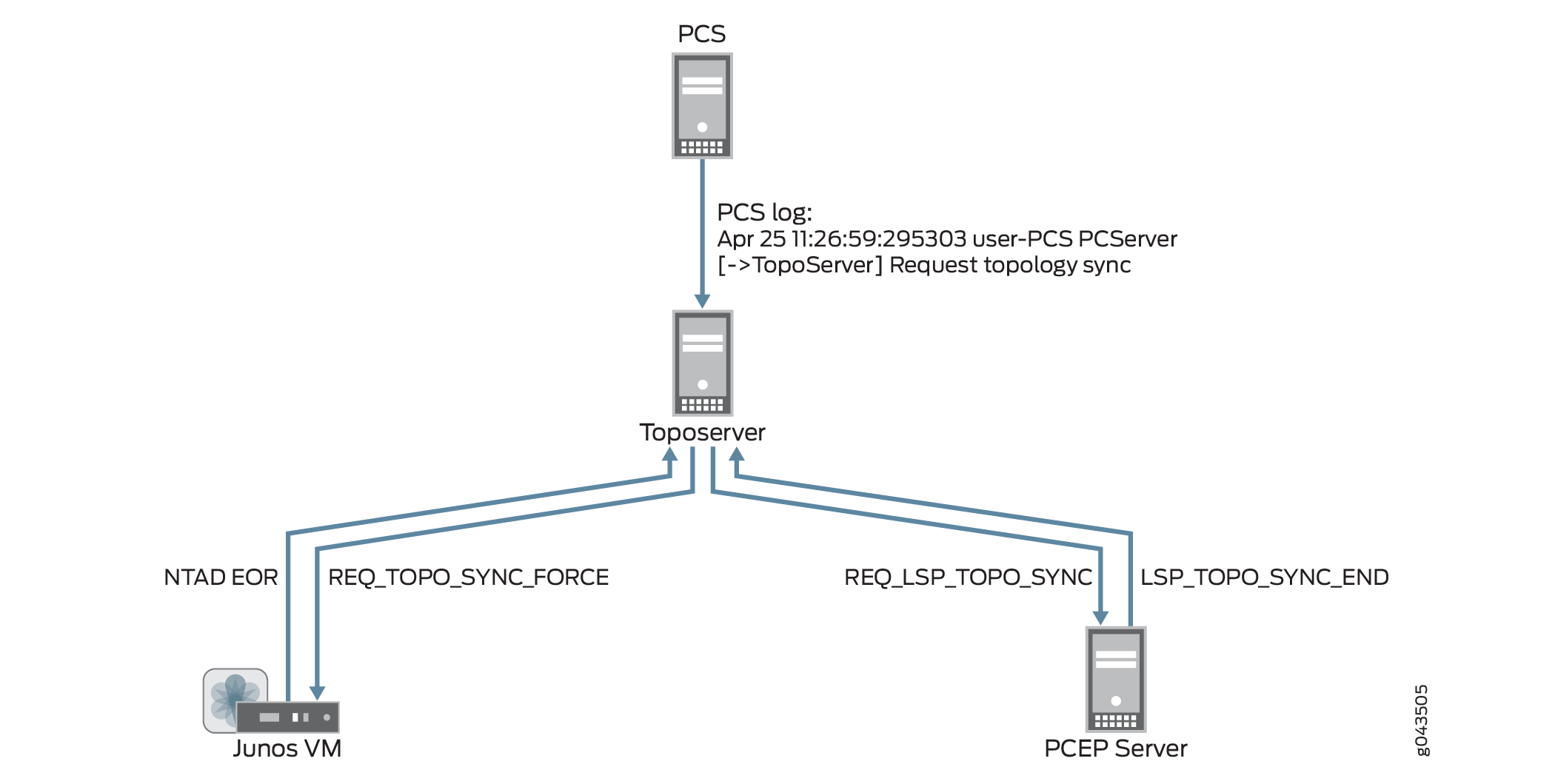 を使用した同期要求とモデルの更新
を使用した同期要求とモデルの更新
クライアント側の問題の調査
問題の原因を探していて、システムのサーバー側で見つからない場合は、クライアント側で見つけるのに役立つデバッグフラグがあります。このフラグは、サーバーとクライアントの間で交換された内容に関する詳細なメッセージを Web ブラウザー・コンソールで有効にします。たとえば、更新が Web UI に反映されないことがあります。これらの詳細なメッセージを使用すると、サーバーが実際に更新を送信していないなど、サーバーとクライアントの間で発生する可能性のある通信ミスを特定できます。
このデバッグ フラグを有効にするには、Web UI の起動に使用する URL を次のように変更します。
https://server_address:8443/client/app.html?debug=true
帯域幅サイジングスケジュールタスクの不完全な結果
帯域幅サイジングスケジュールタスクを実行しても、帯域幅サイジングが有効なすべてのLSPの統計情報が公開されない場合は、スケジュールされた期間に、帯域幅サイジングが有効なすべてのLSPのトラフィック統計が収集されているかどうかを確認します。トラフィック統計が利用できない場合、それらのLSPの帯域幅統計はサイズ変更できません。
NorthStar Collector Web UIを使用して、トラフィック統計が収集されているかどうかを判断できます。
ネットワーク情報テーブルの [トンネル] タブを開きます。
サイズ変更されていない LSP を選択します。
右クリックして を選択します View LSP Traffic。
左上隅の をクリックし custom 、スケジュール期間を入力して、 をクリックします Submit。
NorthStarとHealthBotとの統合のトラブルシューティング
NorthStar で HealthBot へのデバイスの更新が失敗した場合は、まず NorthStar Web アプリケーション サーバー ログにエラーがないかどうかを確認します。
[root@ns1-site1 ~]# tail -f /opt/northstar/logs/web_app.msg
2019 Oct 15 02:46:49.824 - info: Request: User:admin (full):http:GET:127.0.0.1:/NorthStar/API/v1/tenant/1/RouterProfiles/vendorList
2019 Oct 15 02:46:52.165 - info: Request: User:admin (full):http:GET:127.0.0.1:/NorthStar/API/v1/tenant/1/RouterProfiles/liveNetwork
2019 Oct 15 02:47:10.466 - info: Request: User:admin (full):http:POST:127.0.0.1:/NorthStar/API/v2/tenant/1/RouterProfiles/healthbot/updateDevices
req: {}
2019 Oct 15 02:47:17.084 - debug: Devices updated, Healthbot response body = ""
2019 Oct 15 02:47:17.512 - info: Request: User:admin (full):http:POST:127.0.0.1:/NorthStar/API/v2/tenant/1/RouterProfiles/healthbot/updateDeviceGroup
req: {"devices":["vmx104","vmx101","vmx107","vmx103","vmx106","vmx105","vmx102"]}
2019 Oct 15 02:47:18.453 - debug: Device Group updated, Healthbot response body = ""
2019 Oct 15 02:47:18.860 - info: Request: User:admin (full):http:POST:127.0.0.1:/NorthStar/API/v2/tenant/1/RouterProfiles/healthbot/commitConfigs
2019 Oct 15 02:47:18.935 - debug: Commit completed, Healthbot response body = "{\n \"detail\": \"Committing the configuration.\",\n \"status\": 202,\n \"url\": \"/api/v1/configuration/jobs/?job_id=c6be7387-bfbf-45e4-97c8-993f27bcbe09\"\n}\n"
HealthBot API サーバーのログは、HealthBot へのデバイスの更新が失敗した場合に役立つ情報も提供する場合があります。
root@healthbot-vm1:~# healthbot logs --device-group healthbot -s api_server docker logs 1557243a5b 2>&1 | vi - Vim: Reading from stdin...
RPM プローブデータと LDP 要求統計収集が機能しているかどうかを確認するには、IAgent コンテナログにアクセスします。IAgent は RPM データ(リンク遅延)に使用され、LDP は統計情報を収集を要求します。
root@healthbot-vm1:~# docker ps | grep iagent | grep northstar 3492c1f3774f healthbot_iagent:2.1.0-beta-custom "/entrypoint.sh salt…" 23 hours ago Up 23 hours device-group-northstar_device-group-northstar-iagent_1 root@healthbot-vm1:~# docker exec -it 7382325c375f bash root@3492c1f3774f:/# tail -f /tmp/inter-packet-export.log 2019-10-15 07:19:15,329 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx106 2019-10-15 07:19:24,546 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx102 2019-10-15 07:19:27,522 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx101 2019-10-15 07:19:33,788 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx105 2019-10-15 07:19:38,110 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx104 2019-10-15 07:19:39,251 inter-packet.ns_demand aggregates sent for 6 objects for node=vmx103 2019-10-15 07:20:04,654 inter-packet.ns_link_latency Aggregates sent for 2 objects for node=vmx104 2019-10-15 07:20:05,878 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx105 2019-10-15 07:20:06,535 inter-packet.ns_link_latency Aggregates sent for 1 objects for node=vmx103 2019-10-15 07:20:07,537 inter-packet.ns_link_latency Aggregates sent for 3 objects for node=vmx101 2019-10-15 07:20:09,479 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx102 2019-10-15 07:20:15,332 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx106 2019-10-15 07:21:04,657 inter-packet.ns_link_latency Aggregates sent for 2 objects for node=vmx104 2019-10-15 07:21:05,881 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vmx105 2019-10-15 07:21:06,538 inter-packet.ns_link_latency Aggregates sent for 1 objects for node=vmx103 2019-10-15 07:21:07,540 inter-packet.ns_link_latency Aggregates sent for 3 objects for node=vmx101 2019-10-15 07:21:09,484 inter-packet.ns_link_latency Aggregates sent for 4 objects for node=vm
JTI LSPとインターフェイス統計データの収集が機能しているかどうかを確認するには、fluentdコンテナログにアクセスします。JTIデータの収集にはネイティブGBPが使用されます。
root@healthbot-vm1:~# docker ps | grep fluentd | grep northstar 5fa268d0410b healthbot_fluentd:2.1.0-beta-custom "/fluentd/etc/startu…" 20 hours ago Up 20 hours 5140/tcp, 0.0.0.0:4000->4000/tcp, 0.0.0.0:4000->4000/udp, 24224/tcp device-group-northstar_device-group-northstar-fluentd_1 root@healthbot-vm1:~# docker exec -it 5fa268d0410b bash root@5fa268d0410b:/# tail -f /tmp/inter-packet-export.log 2019-10-15 06:00:01,241 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:01:01,245 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:02:01,248 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:03:01,255 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:04:01,259 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:05:01,265 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:06:01,269 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:07:01,274 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:08:01,279 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105 2019-10-15 06:09:01,285 inter-packet.ns_interface_traffic aggregates sent for 24 objects for node=vmx105
統計データが HealthBot サーバから PC に通知されているかどうかを判断するには、PCS ログにアクセスしてライブ統計通知情報を確認します。
[root@ns1-site1-q-pod21 ~]# tail -f /opt/northstar/logs/pcs.log
2019 Oct 15 00:09:19.221768 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005002 ge-0/0/5.3@vmx102 out=0 in=-1
2019 Oct 15 00:09:19.221783 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005002 ge-0/0/1.0@vmx102 out=0 in=-1
2019 Oct 15 00:09:19.221798 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005002 ge-0/0/5.200@vmx102 out=0 in=-1
2019 Oct 15 00:09:19.221812 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005002 ge-0/0/5.301@vmx102 out=0 in=-1
2019 Oct 15 00:09:19.880395 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][<-AMQP] msg=0x00004018 exchange=controller.wan.stats routing_key=ns_tunnel_traffic
2019 Oct 15 00:09:19.880456 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 test1_102_105-1@vmx102 3836219
2019 Oct 15 00:09:19.880463 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 rsvp-102-105@vmx102 0
2019 Oct 15 00:09:19.880469 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 Silver-102-101@vmx102 1041649
2019 Oct 15 00:09:19.880479 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 Silver-102-104@vmx102 3390530
2019 Oct 15 00:09:19.880483 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Traffic] msg=0x00005004 Silver-102-103@vmx102 4261408
2019 Oct 15 00:09:26.795447 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][<-AMQP] msg=0x00004018 exchange=controller.wan.stats routing_key=ns_link_latency
2019 Oct 15 00:09:26.795453 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/1/8.0@vmx103 20.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795462 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/0/6.0@vmx101 4.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795471 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/0/5.0@vmx101 3.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795473 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/1/1.0@vmx101 19.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795476 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/1/9.0@vmx104 10.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:26.795479 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][Latency] msg=0x00007002 ge-0/1/7.0@vmx104 0.00 ms, packet_loss=0.00%
2019 Oct 15 00:09:27.710072 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][<-AMQP] msg=0x00004018 exchange=controller.wan.stats routing_key=ns_demand
2019 Oct 15 00:09:27.710264 ns1-site1-q-pod21 PCServer [Debug][PCServer] node:vmx102 prefix:10.0.0.101/32 bit_rate:0 demand_name=vmx102_10.0.0.101/32 to=10.0.0.101/32 SNMP_ifIndex:0 next_hope=
2019 Oct 15 00:09:27.710599 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][->pcs_tunnel_event] msg=0x00004002 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.710667 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x00004027 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.710697 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x0000400a vmx102_10.0.0.101/32@10.0.0.102 pathname=10.0.0.101 to=10.0.0.101 bw=0 pri=7 pre=7 type=R,A2Z,PATH(10.0.0.101) path= op_state=ACTIVE ns_lsp_id =42 demand=true prefix=10.0.0.101/32
2019 Oct 15 00:09:27.710724 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Topology 1 OBJ: ns:1:pcs_lsp:id:int:obj 42 {buf} index:ns:1:pcs_lsp:indexes id_str:
2019 Oct 15 00:09:27.711440 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Done
2019 Oct 15 00:09:27.711450 ns1-site1-q-pod21 PCServer [Debug][PCServer] node:vmx102 prefix:10.0.0.105/32 bit_rate:0 demand_name=vmx102_10.0.0.105/32 to=10.0.0.105/32 SNMP_ifIndex:0 next_hope=
2019 Oct 15 00:09:27.711454 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][->pcs_tunnel_event] msg=0x00004002 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.711457 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x00004027 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.711461 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x0000400a vmx102_10.0.0.105/32@10.0.0.102 pathname=10.0.0.105 to=10.0.0.105 bw=0 pri=7 pre=7 type=R,A2Z,PATH(10.0.0.105) path= op_state=ACTIVE ns_lsp_id =44 demand=true prefix=10.0.0.105/32
2019 Oct 15 00:09:27.711464 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Topology 1 OBJ: ns:1:pcs_lsp:id:int:obj 44 {buf} index:ns:1:pcs_lsp:indexes id_str:
2019 Oct 15 00:09:27.712010 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Done
2019 Oct 15 00:09:27.712033 ns1-site1-q-pod21 PCServer [Debug][PCServer] node:vmx102 prefix:10.0.0.103/32 bit_rate:0 demand_name=vmx102_10.0.0.103/32 to=10.0.0.103/32 SNMP_ifIndex:0 next_hope=
2019 Oct 15 00:09:27.712039 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][->pcs_tunnel_event] msg=0x00004002 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.712042 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x00004027 LSP action, UPDATE id=3718607015 event=demand update
2019 Oct 15 00:09:27.712048 ns1-site1-q-pod21 PCServer [NorthStar][PCServer][tunnelEvent] msg=0x0000400a vmx102_10.0.0.103/32@10.0.0.102 pathname=10.0.0.103 to=10.0.0.103 bw=0 pri=7 pre=7 type=R,A2Z,PATH(10.0.0.103) path= op_state=ACTIVE ns_lsp_id =48 demand=true prefix=10.0.0.103/32
2019 Oct 15 00:09:27.712808 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Topology 1 OBJ: ns:1:pcs_lsp:id:int:obj 48 {buf} index:ns:1:pcs_lsp:indexes id_str:
2019 Oct 15 00:09:27.713209 ns1-site1-q-pod21 PCServer [Debug][PCServer] Redis Obj Save: Done
2019 Oct 15 00:09:27.713219 ns1-site1-q-pod21 PCServer [Debug][PCServer] node:vmx102 prefix:10.0.0.104/32 bit_rate:0 demand_name=vmx102_10.0.0.104/32 to=10.0.0.104/32 SNMP_ifIndex:0 next_hope=
NorthStar Controllerデバッグファイルの収集
NorthStar コントローラの問題を解決できない場合は、NorthStar コントローラ デバッグユーティリティで生成されたデバッグファイルを評価のためにJTACに転送することをお勧めします。現在、すべてのデバッグファイルは u/wandl/tmp ディレクトリの下のサブディレクトリにあります。
デバッグ ファイルを収集するには、NorthStar Controller CLI にログインし、 コマンド u/wandl/bin/system-diagnostic.sh filenameを実行します。
出力が生成され、.tbz2 デバッグ ファイルの /tmp ディレクトリfilenameから使用できます。
リモートSyslog
NorthStar プロセスのほとんどは /etc/rsyslog.conf で定義されている rsyslog を使用します。rsyslog の使用の詳細については、Linux システムで実行されている特定の rsyslog バージョンについて、 http://www.rsyslog.com/doc を参照してください。
SNMP収集の規模を拡大する
5 分のポーリング間隔内で SNMP 収集の規模を拡大するには、以下のタスクを実行します。
viなどのテキスト編集ツールを使用して、ファイルを開いて
supervisord_snmp_slave.conf編集します。構成ファイルが開きます。
vi opt/northstar/data/supervisord/supervisord_snmp_slave.conf
次のコマンドを追加して、スレッドの数を 100 から 200 に増やします。
/opt/northstar/thirdparty/python3/bin/celery -A collector.celery -Q netsnmp -n worker2@%%n worker -P threads -c 200--loglevel=info
前のワーカーを複製して、さらにワーカー (たとえば、worker3) を追加します。
[program:worker3] /opt/northstar/thirdparty/python3/bin/celery -A collector.celery -Q netsnmp -n worker3@%%n worker -P threads -c 200--loglevel=info process_name=%(program_name)s numprocs=1 ;directory=/tmp ;umask=022 priority=999 autostart=true autorestart=true startsecs=10 startretries=3 exitcodes=0,2 stopsignal=TERM stopwaitsecs=10 user=pcs stopasgroup=true killasgroup=true redirect_stderr=true stopasgroup=true stdout_logfile=/opt/northstar/logs/celery_worker3.msg stdout_logfile_maxbytes=10MB stdout_logfile_backups=10 stdout_capture_maxbytes=10MB stderr_logfile=/opt/northstar/logs/celery_worker3.err stderr_logfile_maxbytes=10MB stderr_logfile_backups=10 stderr_capture_maxbytes=10MB environment=PYTHONPATH="/opt/northstar/snmp-collector",LD_LIBRARY_PATH="/opt/northstar/lib" ;environment=A="1",B="2" ;serverurl=AUTO
グループステートメントにワーカーを追加します。
ベスト プラクティス:追加できるワーカーの数は、CPU のコア数以下である必要があります。
[group:collector] programs=worker1,worker2,worker3
スーパーバイザーで を再起動します
collector:* group。supervisorctl reread supervisorctl update
ワーカー 1、ワーカー 2、およびワーカー 3 のスーパーバイザーの状態を表示して、それらが稼働していることを確認します。
supervisorctl status
出力にいくつかの worker 1 プロセスが表示され、worker2 と worker3 にはそれぞれ 1 つの親プロセスのみが表示されることを確認します。
ps -ef | grep celery
スケーラビリティを高めるためにスレッド数を増やすには、次のタスクを実行します。
viなどのテキスト編集ツールを使用して、ファイルを開いて
data_gateway.py編集します。構成ファイルが開きます。
vi /opt/northstar/snmp-collector/collector/data_gateway.py
プール内のスレッド数を 10 から 20 に増やします。
pool_size = 20
collector_main:data_gatewayプロセスを停止し、プロセスを再開します。supervisorctl stop collector_main:data_gateway supervisorctl restart collector_main:data_gateway
スケーラビリティを高めるためにスループットを向上させるには、次のタスクを実行します。
viなどのテキスト編集ツールを使用して、ファイルを開いて
es_publisher.cfg編集します。構成ファイルが開きます。
vi /opt/northstar/data/es_publisher/es_publisher.cfg
以下のパラメータを設定します。
polling_interval=5 batch_size=5000 pool_size=20
メモ:1回の操作でElasticSearchデータベース(batch_size)に送信されるレコードの最大数は5000ですが、SNMP統計pool_sizeを収集するために実行できるスレッドの最大数(スレッドプール内)は20です。
ポーリングごとにより多くのルーター インターフェイスからデータを収集するには、以下のタスクを実行します。
NorthStar Controller GUIのデバイスプロファイル(デバイスプロファイル>管理)ページに移動します。
デバイスリストで、ルーターを選択し、 変更 をクリックします。
[デバイスの変更] ページが表示されます。
[ユーザー定義プロパティ] タブの [名前] 列で、プロパティの名前を bulk_size に指定します。[値] 列で、バルク サイズを 100 に設定します。
バルク サイズは、ネットワークがポーリングされるたびに収集されるインターフェイスの数を示します。
[ 変更] をクリックします。
[デバイス プロファイル(Device Profile)] ページにリダイレクトされ、変更が保存されたことを示す確認メッセージが表示されます。