Paragon Automationのインストールのトラブルシューティング
概要 以下のトピックを読んで、インストール中およびインストール後に発生する可能性のある一般的な問題のトラブルシューティング方法について説明します。
構成ファイルのマージの競合を解決する
init スクリプトは、テンプレート構成ファイルを作成します。インストールに使用したのと同じ config-dir ディレクトリーを使用して既存のインストール済み環境を更新する場合、init スクリプトが作成するテンプレート・ファイルは、既存の構成ファイルとマージされます。場合によっては、このマージ アクションによって、解決が必要なマージの競合が発生します。スクリプトは、競合を解決する方法についてプロンプトを表示します。プロンプトが表示されたら、次のいずれかのオプションを選択します。
-
C - 既存のコンフィギュレーション ファイルを保持し、新しいテンプレート ファイルを破棄できます。これはデフォルトのオプションです。
-
n:既存のコンフィギュレーション ファイルを破棄し、テンプレート ファイルを再初期化できます。
-
m - ファイルを手動でマージできます。競合するセクションは、
<<<<<<<<、||||||||、========、および>>>>>>>>で始まる行でマークされます。更新を続行する前に、ファイルを編集し、差し込みマーカーを削除する必要があります。 -
d - 競合の解決方法を決定する前に、ファイル間の相違点を表示できます。
バックアップと復元に関する一般的な問題の解決
既存のクラスタを破棄し、同じクラスタ ノードにソフトウェア イメージを再展開するとします。このような場合、以前にバックアップした設定フォルダから設定を復元しようとすると、復元操作が失敗することがあります。バックアップされた構成のマウント パスが変更されているため、復元操作が失敗します。既存のクラスターを破棄すると、永続ボリュームは削除されます。新しいイメージを再デプロイすると、永続ボリュームは、使用可能な領域があるクラスター ノードの 1 つに再作成されますが、必ずしも以前と同じノードに存在する必要はありません。その結果、復元操作は失敗します。
これらのバックアップと復元の問題を回避するには:
-
新しい永続ボリュームのマウント パスを決定します。
-
以前の永続ボリュームのマウントパスの内容を新しいパスにコピーします。
-
復元操作を再試行します。
インストールログファイルの表示
deploy スクリプトが失敗した場合は、config-dir ディレクトリー内のインストール・ログ・ファイルを確認する必要があります。既定では、config-dir ディレクトリには 6 つの圧縮されたログ ファイルが格納されます。現在のログ ファイルは log として保存され、以前のログ ファイルは log.1 から log.5 ファイルとして保存されます。deploy スクリプトを実行するたびに、現在のログが保存され、最も古いログは破棄されます。
通常、エラー メッセージはログ ファイルの末尾にあります。エラー メッセージを表示し、構成を修正します。
kubectl インターフェイスを使用したトラブルシューティング
kubectl(Kube Control)は、Kubernetes APIと対話するコマンドラインユーティリティであり、最も一般的なコマンドラインはKubernetesクラスターを制御するために使用されました。
kubectl コマンドは、インストール直後に 1 次ノードで発行できます。ワーカー ノードで kubectl コマンドを発行するには、 admin.conf ファイルをコピーして kubeconfig 環境変数を設定するか、 エクスポート KUBECONFIG=config-dir /admin.conf コマンドを使用する必要があります。 admin.conf ファイルは、インストール・プロセスの一環として、コントロール・ホストの config-dir ディレクトリーにコピーされます。
kubectl コマンド ライン ツールを使用して、Kubernetes API と通信し、ノード、ポッド、サービスなどの API リソースに関する情報の取得、ログ ファイルの表示、およびそれらのリソースの作成、削除、または変更を行います。
kubectl コマンドの構文は次のとおりです。
kubectl [command] [TYPE] [NAME] [flags]
[command] は単に実行するアクションです。
次のコマンドを使用して、kubectl コマンドのリストを表示できます。
root@primary-node:/# kubectl [enter]
詳細を取得し、特定のコマンドに関連付けられているすべてのフラグとオプションを一覧表示するために、ヘルプを求めることができます。例えば:
root@primary-node:/# kubectl get -h
Paragon Automationでの動作を確認およびトラブルシューティングするには、以下のコマンドを使用します。
| [コマンド] | 説明 |
|---|---|
| 取得 | 1 つまたは複数のリソースを表示します。 出力には、指定されたリソースに関する最も重要な情報のテーブルが表示されます。 |
| 写す | 特定のリソースまたはリソースのグループの詳細を表示します。 |
| 説明する | リソースのドキュメント。 |
| ログ | ポッド内のコンテナーのログを表示します。 |
| ロールアウトの再開 | リソースのロールアウトを管理します。 |
| 編集 | リソースを編集します。 |
[TYPE] 表示するリソースの種類を表します。リソースの種類では大文字と小文字が区別されず、単数形、複数形、または省略形を使用できます。
たとえば、ポッド、ノード、サービス、デプロイなどです。リソースの完全なリストと、許可される省略形 (例: pod = po) については、次のコマンドを発行します。
kubectl api-resources
リソースの詳細については、次のコマンドを発行してください。
kubectl explain [TYPE]
例えば:
root@primary-node:/# kubectl explain pod
KIND: Pod
VERSION: v1
DESCRIPTION:
Pod is a collection of containers that can run on a host. This resource is
created by clients and scheduled onto hosts.
---more---
[NAME] は、特定のリソースの名前 (サービスやポッドの名前など) です。名前では大文字と小文字が区別されます。
root@primary-node:/# kubectl get pod pod_name
[flags] コマンドの追加オプションを提供します。たとえば、 -o には、リソースのより多くの属性が一覧表示されます。ヘルプ (-h) を使用して、使用可能なフラグに関する情報を取得します。
ほとんどの Kubernetes リソース (ポッドやサービスなど) は一部の名前空間にありますが、他の名前空間 (ノードなど) にはないことに注意してください。
名前空間は、1 つのクラスター内でリソースのグループを分離するためのメカニズムを提供します。リソースの名前は、名前空間内で一意である必要がありますが、名前空間間で一意である必要はありません。
名前空間内のリソースでコマンドを使用する場合は、コマンドの一部として名前空間を含める必要があります。名前空間では大文字と小文字が区別されます。適切な名前空間がないと、目的の特定のリソースが表示されない場合があります。
root@primary-node:/# kubectl get services mgd Error from server (NotFound): services "mgd" not found root@primary-node:/# kubectl get services mgd -n healthbot NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE mgd ClusterIP 10.102.xx.12 <none> 22/TCP,6500/TCP,8082/TCP 18h
すべての名前空間のリストを取得するには、 kubectl get namespace コマンドを発行します。
すべての名前空間のリソースを表示する場合、または関心のある特定のリソースがどの名前空間に属しているかわからない場合は、「 --all-namespaces 」または「 - A」と入力します。
Kubernetes の詳細については、以下を参照してください。
- https://kubernetes.io/docs/reference/kubectl/overview/
- https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
kubectl インターフェイスを使用してインストールの詳細をトラブルシューティングおよび表示するには、次のトピックを使用します。
- ノードステータスの表示
- ポッドのステータスの表示
- ポッドに関する詳細情報の表示
- ポッド内のコンテナーのログを表示する
- ポッド内のコンテナーでコマンドを実行する
- サービスを見る
- 頻繁に使用される kubectl コマンド
ノードステータスの表示
kubectl get no コマンドと略される kubectl get nodes コマンドを使用して、クラスター ノードの状態を表示します。ノードの状態は [Ready] で、ロールは [control-plane] または [none] である必要があります。例えば:
root@primary-node:~# kubectl get no NAME STATUS ROLES AGE VERSION 10.49.xx.x1 Ready control-plane,master 5d5h v1.20.4 10.49.xx.x6 Ready <none> 5d5h v1.20.4 10.49.xx.x7 Ready <none> 5d5h v1.20.4 10.49.xx.x8 Ready <none> 5d5h v1.20.4
ノードが Readyされていない場合は、kubeletプロセスが実行されているかどうかを確認します。ノードのシステム ログを使用して問題を調査することもできます。
kubeletを検証するには: root@primary-node:/# kubelet
ポッドのステータスの表示
kubectl get po –n namespace コマンドまたは kubectl get po -A コマンドを使用して、ポッドのステータスを表示します。個々の名前空間 (healthbot、northstar、common など) を指定することも、-A パラメーターを使用してすべての名前空間の状態を表示することもできます。例えば:
root@primary-node:~# kubectl get po -n northstar NAME READY STATUS RESTARTS AGE bmp-854f8d4b58-4hwx4 3/3 Running 1 30h dcscheduler-55d69d9645-m9ncf 1/1 Running 1 7h13m
正常なポッドの状態は Running または Completed である必要があり、準備完了コンテナーの数は合計と一致する必要があります。ポッドの状態が Running でない場合、またはコンテナーの数が一致しない場合は、 kubectl describe po または kubectl log (POD | TYPE/NAME) [-c CONTAINER] コマンドを使用して、問題のトラブルシューティングをさらに進めます。
ポッドに関する詳細情報の表示
kubectl describe po -n namespace pod-name コマンドを使用して、特定のポッドに関する詳細情報を表示します。例えば:
root@primary-node:~# kubectl describe po -n northstar bmp-854f8d4b58-4hwx4
Name: bmp-854f8d4b58-4hwx4
Namespace: northstar
Priority: 0
Node: 10.49.xx.x1/10.49.xx.x1
Start Time: Mon, 10 May 2021 07:11:17 -0700
Labels: app=bmp
northstar=bmp
pod-template-hash=854f8d4b58
…
ポッド内のコンテナーのログを表示する
kubectl logs -n namespace pod-name [-c container-name] コマンドを使用して、特定のポッドのログを表示します。ポッドに複数のコンテナーがある場合は、ログを表示するコンテナーを指定する必要があります。例えば:
root@primary-node:~# kubectl logs -n common atom-db-0 | tail -3
2021-05-31 17:39:21.708 36 LOG {ticks: 0, maint: 0, retry: 0}
2021-05-31 17:39:26,292 INFO: Lock owner: atom-db-0; I am atom-db-0
2021-05-31 17:39:26,350 INFO: no action. i am the leader with the lock
ポッド内のコンテナーでコマンドを実行する
kubectl exec –ti –n namespacepod-name [-c container-name] -- command-line コマンドを使用して、ポッド内のコンテナーでコマンドを実行します。例えば:
root@primary-node:~# kubectl exec -ti -n common atom-db-0 -- bash
____ _ _
/ ___| _ __ (_) | ___
\___ \| '_ \| | |/ _ \
___) | |_) | | | (_) |
|____/| .__/|_|_|\___/
|_|
This container is managed by runit, when stopping/starting services use sv
Examples:
sv stop cron
sv restart patroni
Current status: (sv status /etc/service/*)
run: /etc/service/cron: (pid 29) 26948s
run: /etc/service/patroni: (pid 27) 26948s
run: /etc/service/pgqd: (pid 28) 26948s
root@atom-db-0:/home/postgres#
execコマンドを実行すると、Postgresデータベースサーバーにbashシェルが表示されます。コンテナー内の bash シェルにアクセスし、コマンドを実行してデータベースに接続できます。すべてのコンテナがbashシェルを提供するわけではありません。一部のコンテナはSSHのみを提供し、一部のコンテナにはシェルがありません。
サービスを見る
kubectl get svc -n namespace コマンドまたは kubectl get svc -A コマンドを使用して、クラスター・サービスを表示します。個々の名前空間 (healthbot、northstar、common など) を指定することも、-A パラメーターを使用してすべての名前空間のサービスを表示することもできます。例えば:
root@primary-node:~# kubectl get svc -A --sort-by spec.type NAMESPACE NAME TYPE EXTERNAL-IP PORT(S) … healthbot tsdb-shim LoadBalancer 10.54.xxx.x3 8086:32081/TCP healthbot ingest-snmp-proxy-udp LoadBalancer 10.54.xxx.x3 162:32685/UDP healthbot hb-proxy-syslog-udp LoadBalancer 10.54.xxx.x3 514:31535/UDP ems ztpservicedhcp LoadBalancer 10.54.xxx.x3 67:30336/UDP ambassador ambassador LoadBalancer 10.54.xxx.x2 80:32214/TCP,443:31315/TCP,7804:32529/TCP,7000:30571/TCP northstar ns-pceserver LoadBalancer 10.54.xxx.x4 4189:32629/TCP …
この例では、サービスはタイプ別にソートされ、タイプ LoadBalancer のサービスのみが表示されます。クラスターによって提供されるサービスと、それらのサービスにアクセスするためにロードバランサーによって選択された外部 IP アドレスを表示できます。
これらのサービスには、クラスターの外部からアクセスできます。外部 IP アドレスは公開され、クラスター外のデバイスからアクセスできます。
頻繁に使用される kubectl コマンド
-
レプリケーション コントローラーを一覧表示します。
# kubectl get –n namespace deploy
# kubectl get –n namespace statefulset
-
コンポーネントを再起動します。
kubectl rollout restart –n namespace deploy deployment-name
-
Kubernetes リソースの編集: デプロイまたは任意の Kubernetes API オブジェクトを編集でき、これらの変更はクラスターに保存されます。ただし、クラスターを再インストールした場合、これらの変更は保持されません。
# kubectl edit –ti –n namespace deploy deployment-name
paragon CLIユーティリティを使用したトラブルシューティング
paragon コマンド CLI ユーティリティを導入しました。
paragon コマンドは、クラスターの分析、クエリ、トラブルシューティングを可能にする直感的なコマンドのセットです。コマンドを実行するには、いずれかのプライマリノードにログインします。一部のコマンドでは、
paragon コマンド・ユーティリティーが kubectl の代わりに kubecolor コマンドを実行するため、一部のコマンドの出力は色分けされています。出力例については、
図 1 を参照してください。
paragon CLI ユーティリティー・コマンドを実行するには、root ユーザーであるか、スーパーユーザー(sudo)権限を持つ非 root ユーザーである必要があります。
使用可能なコマンド ヘルプ オプションのセット全体を表示するには、次のいずれかのコマンドを使用します。
root@primary-node:~# paragon ? root@primary-node:~# paragon --help root@primary-node:~# paragon -h
ヘルプ オプションは、(トップ レベルだけでなく) 任意のコマンド レベルで表示できます。例えば:
root@primary-node:~# paragon insights cli ? paragon insights cli alerta => Gets into the CLI of paragon insights alerta pod. paragon insights cli byoi => Gets into the CLI of byoi plugin.Usage : --byoi <BYOI plugin name>. paragon insights cli configserver => Gets into the CLI of paragon insights config-server pod. paragon insights cli grafana => Gets into the CLI of paragon insights grafana pod. paragon insights cli influxdb => Gets into the CLI of paragon insights InfluxDB pod.Use Argument: --influx <influxdb-nodeip> to specify the node ip ,else the command will use first influx node as default.Eg: --influx influxdb-172-16-18-21 paragon insights cli mgd => Gets into the CLI of paragon insights mgd pod.
タブオプションを使用して、コマンドの可能なオートコンプリートオプションを表示できます。最上位のコマンドのオートコンプリートを表示するには、 paragon と入力して Tab キーを押します。例えば:
root@primary-node:~# paragon ambassador describe get pathfinder set common ems insights rookceph
paragon コマンドが実行する基になるコマンドを表示するには、echo または -e オプションを使用します。例えば:
root@primary-node:~# paragon -e get nodes all >>>> command: kubecolor --force-colors get nodes
paragon コマンドを実行し、そのコマンドが実行する基になるコマンドを表示するには、debug オプションまたは -d オプションを使用します。例えば:
root@primary-node:~# paragon -d get nodes all >>>> command: kubecolor --force-colors get nodes NAME STATUS ROLES AGE VERSION ix-pgn-pr-01 Ready control-plane,etcd,master 17d v1.26.6+rke2r1 ix-pgn-pr-02 Ready control-plane,etcd,master 17d v1.26.6+rke2r1 ix-pgn-pr-03 Ready control-plane,etcd,master 17d v1.26.6+rke2r1 ix-pgn-wo-01 Ready <none> 17d v1.26.6+rke2r1
paragonコマンドの全リストと、それらが実行する対応する基になるコマンドを表示するには、次のコマンドを使用します。
root@primary-node:~# paragon --mapped
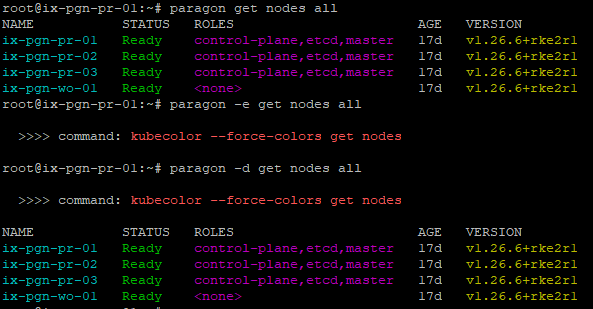
paragon例
引数や前提条件 (ある場合) などの特定の使用基準については、各コマンドのヘルプ セクションの指示に従ってください。一部のコマンドには必須の引数が必要です。たとえば、 paragon insights logs devicegroup analytical コマンドには引数 --dg devicegroup-name-with subgroup が必要です。例えば:
paragon insights logs devicegroup analytical --dg controller-0
一部のコマンドには前提条件があります。たとえば、 paragon insights get playbooks コマンドを使用する前に、 paragon set username --cred username コマンドと paragon set password --cred password コマンドを使用してユーザー名とパスワードを設定する必要があります。
コマンドの完全なセットとその使用基準を 表 1 に示します。
| 命令 |
形容 |
|---|---|
|
|
は、パラゴン大使の使者ポッドを示しています。 |
|
|
すべての Paragonアンバサダーポッドを表示します。 |
|
|
すべてのParagonアンバサダーサービスを表示します。 |
|
|
Postgresの役割を見つけるのに役立ちます。 |
|
|
クラスタ内の特定のノードの説明を表示します。
例:
|
|
|
デバイスマネージャParagon emsポッドを表示します。 |
|
|
ジョブ マネージャー Paragon EMS ポッドを表示します。 |
|
|
すべてのParagon EMSポッドを表示します。 |
|
|
すべてのParagon EMSサービスを表示します。 |
|
|
Paragon EMSデバイスマネージャーポッドのログを表示します。
|
|
|
paragon emsジョブマネージャーポッドのログを表示します。 |
|
|
Paragonで使用可能なすべての名前空間を表示します。 |
|
|
クラスタ内のすべてのノードのリストを表示します。 |
|
|
kubeletにディスク負荷があるかどうかを検証します。
例: |
|
|
kubelet に十分なメモリがあるかどうかを検証します。
例: |
|
|
calicoとネットワークに問題がないか確認します。
例: |
|
|
クラスタ内で準備ができていないすべてのノードのリストを表示します。 |
|
|
kubeletに使用可能な十分なPIDがあるかどうかを検証します。
例: |
|
|
クラスター内で準備ができているすべてのノードの一覧を表示します。 |
|
|
ノード上のすべての汚染のリストを表示します。 |
|
|
正常な Paragonポッドをすべて表示します。 |
|
|
異常な Paragon ポッドをすべて表示します。 |
|
|
公開されているすべてのParagonサービスを表示します。 |
|
|
Paragon InsightsアラートポッドのCLIにログインします。 |
|
|
BYOIプラグインのCLIにログインします。
|
|
|
Paragon InsightsコンフィグサーバーポッドのCLIにログインします。 |
|
|
Paragon Insightsgrafana ポッドのCLIにログインします。 |
|
|
Paragon InsightsinfluxdbポッドのCLIにログインします。
例: |
|
|
Paragon Insights mgd ポッドの CLI にログインします。 |
|
|
Paragon Insights alerta ポッドについて説明します。 |
|
|
Paragon Insights REST API ポッドについて説明します。 |
|
|
Paragon Insightsコンフィグサーバーポッドについて説明します。 |
|
|
Paragon Insightsグラファナポッドについて説明します。 |
|
|
Paragon Insightsinfluxdbポッドについて説明します。 ノード IP を指定するには、 例: |
|
|
Paragon Insights mgd ポッドについて説明します。 |
|
|
は、Paragon Insightsアラートポッドを示しています。 |
|
|
は、Paragon Insights REST API ポッドを示しています。 |
|
|
は、Paragon Insightsコンフィグサーバーポッドを示しています。 |
|
|
すべてのParagon Insightsデバイスグループを表示します。 デフォルトのユーザー名は 前提条件として、 |
|
|
すべてのParagon Insightsデバイスを表示します。 デフォルトのユーザー名は 前提条件として、 |
|
|
は、Paragon Insightsグラファナポッドを示しています。 |
|
|
は、Paragon Insightsのinfluxdbポッドを示しています。 |
|
|
は、Paragon Insightsネットワークテレメトリインジェストポッドを示しています。 |
|
|
は、Paragon Insightsの管理ポッドを示しています。 |
|
|
すべてのParagon Insightsプレイブックを表示します。 デフォルトのユーザー名は 前提条件として、 |
|
|
すべてのParagon Insightsポッドを表示します。 |
|
|
すべてのParagon Insightsサービスを表示します。 |
|
|
Paragon Insightsアラートポッドのログを表示します。 |
|
|
Paragon InsightsのREST APIポッドのログを表示します。 |
|
|
Paragon Insights BYOIプラグインのログを表示します。
|
|
|
Paragon Insightsコンフィグサーバーポッドのログを表示します。 |
|
|
サービス分析エンジンのParagon Insightsデバイスグループのログを表示します。
例: この例では、 controller はデバイスグループ名で、 0 はサブグループです。 |
|
|
サービスitsdbのParagon Insightsデバイスグループのログを表示します。
例: この例では、 controller はデバイスグループ名で、 0 はサブグループです。 |
|
|
サービスjtimonのParagon Insightsデバイスグループのログを表示します。
例: この例では、 controller はデバイスグループ名で、 0 はサブグループです。 |
|
|
サービスjtiネイティブのParagon Insightsデバイスグループのログを表示します。
例: この例では、 controller はデバイスグループ名で、 0 はサブグループです。 |
|
|
サービスsyslogのParagon Insightsデバイスグループのログを表示します。
例: この例では、 controller はデバイスグループ名で、 0 はサブグループです。 |
|
|
Paragon Insights Grafana ポッドのログを表示します。 |
|
|
Paragon Insightsinfluxdbポッドのログを表示します。 ノード IP を指定するには、 例: |
|
|
Paragon Insightsmgdポッドのログを表示します。 |
|
|
Paragon Pathfinder BMPコンテナのCLIにログインします。 |
|
|
Paragon Pathfinder ns-configserver コンテナの CLI にログインします。 |
|
|
Paragon Pathfinder cRPDコンテナのCLIにログインします。 |
|
|
Paragon Pathfinder debugutils コンテナの CLI にログインします。 |
|
|
Paragon Pathfinder netconfコンテナのCLIにログインします。 |
|
|
Paragon Pathfinder ns-pceserver container(PCEP)サービスの CLI にログインします。 |
|
|
Paragon Pathfinder ns-pcserver(PCS)コンテナのCLIにログインします。 |
|
|
Paragon Pathfinder ns-pcsviewer(Paragon Planner Desktop Application)コンテナのCLIにログインします。 |
|
|
Paragon PathfinderスケジューラコンテナのCLIに入ります。 |
|
|
Paragon Pathfinder ns-toposerver(トポロジーサービス)コンテナのCLIにログインします。 |
|
|
Paragon Pathfinder ns-web コンテナの CLI にログインします。 |
|
|
BGP-LSに関連するParagon Pathfinder cRPDルーティングオプションの設定をデバッグします。 |
|
|
BGP-LSに関連するParagon Pathfinder cRPDルートをデバッグします。 |
|
|
Paragon Pathfinder debugutils genjvisiondataヘルプを表示します。 |
|
|
show paragon Pathfinder debugutils genjvisiondata params. |
|
|
デバッグのため、Paragon Pathfinder PCEP CLI にログインします。 |
|
|
Kubernetes クラスターの Postgres ステータスを表示します。 |
|
|
ウサギmqctl クラスターの状況を表示します。 |
|
|
Paragon Pathfinder debugutils ポッドを実行して、AMQP 間でやりとりされるデータのスヌープとデコードを実行します。 |
|
|
は、Paragon Pathfinder debugutils snoop helpを示しています。 |
|
|
Paragon Pathfinder debugutils ポッドを実行して、Postgres間でやりとりされたデータのスヌープとデコードを行います。 |
|
|
Paragon Pathfinder debugutils ポッドを実行して、Redisリンク間でやりとりされるデータをスヌープおよびデコードします。 |
|
|
Paragon Pathfinder debugutils ポッドを実行して、Redis lsp 間で交換されるデータのスヌープとデコードを行います。 |
|
|
Paragon Pathfinder debugutils ポッドを実行して、redisノード間で交換されるデータをスヌープおよびデコードします。 |
|
|
Paragon Pathfinder debugutils topo_utilヘルプを表示します。 |
|
|
セーフモードを無効にするParagon Pathfinder debugutils topo_utilツールを示しています。 |
|
|
Paragon Pathfinder debugutils topo_utilツールを実行して、現在のトポロジーを更新します。 |
|
|
Paragon Pathfinder debugutils topo_util ツールを実行して、現在のトポロジーのスナップショットを保存します。 |
|
|
cRPDコンテナとBMPコンテナを含むParagon Pathfinderポッドについて説明します。 |
|
|
設定サーバーコンテナを含むParagon Pathfinderポッドについて説明します。 |
|
|
debugutilsコンテナを含むParagon Pathfinderポッドについて説明します。 |
|
|
ns-netconfdコンテナを含むParagon Pathfinderポッドについて説明します。 |
|
|
ns-pceserver コンテナ(PCEP サービス)を含む Paragon Pathfinder ポッドについて説明します。 |
|
|
ns-pcserver コンテナ(PCS)を含む Paragon Pathfinder ポッドについて説明します。 |
|
|
ns-pcsviewerコンテナ(Paragon Plannerデスクトップアプリケーション)を含むParagon Pathfinderポッドについて説明します。 |
|
|
スケジューラコンテナを含むParagon Pathfinderポッドについて説明します。 |
|
|
ns-toposerver(トポロジーサービス)コンテナを含むParagon Pathfinderポッドについて説明します。 |
|
|
Web コンテナを含む Paragon Pathfinder ポッドについて説明します。 |
|
|
は、cRPDコンテナとBMPコンテナを含むParagon Pathfinderポッドを示しています。 |
|
|
は、ns-configserverコンテナとsyslogコンテナを含むParagon Pathfinderポッドを示しています。 |
|
|
は、debugutilsコンテナを含むParagon Pathfinderポッドを示しています。 |
|
|
は、netconfプロセスに関連付けられたParagon Pathfinderポッドを示しています。 |
|
|
は、ns-pceserver コンテナ(PCEP サービス)を含む Paragon Pathfinder ポッドを示しています。 |
|
|
は、ns-pcserver コンテナ(PCS)を含む Paragon Pathfinder ポッドを示しています。 |
|
|
は、ns-pcsviewerコンテナ(Paragon Plannerデスクトップアプリケーション)を含むParagon Pathfinderポッドを示しています。 |
|
|
すべてのParagon Pathfinderポッドを表示します。 |
|
|
は、スケジューラプロセスに関連付けられたParagon Pathfinderポッドを示しています。 |
|
|
すべてのParagon Pathfinderサービスを表示します。 |
|
|
は、ns-toposerverコンテナ(トポロジーサービス)を含むParagon Pathfinderポッドを示しています。 |
|
|
は、ns-web プロセスに関連付けられた Paragon Pathfinder ポッドを示しています。 |
|
|
Paragon Pathfinder bmp pods bmp コンテナのログを表示します。 |
|
|
Paragon Pathfinder bmp pods cRPD コンテナのログを表示します。 |
|
|
Paragon Pathfinder bmp pods syslog コンテナのログを表示します。 |
|
|
Paragon Pathfinder コンフィグサーバー ポッド ns-configserver コンテナのログを表示します。 |
|
|
Paragon Pathfinder コンフィグサーバーポッドの syslog コンテナのログを表示します。 |
|
|
Paragon Pathfinder netconf pods ns-netconfd コンテナのログを表示します。 |
|
|
Paragon Pathfinder netconf pods syslog コンテナのログを表示します。 |
|
|
Paragon Pathfinder pceserver pods ns-pceserver container のログを表示します。 |
|
|
Paragon Pathfinder pceserver pods syslog コンテナのログを表示します。 |
|
|
タイムスタンプ、レベル、メッセージのみを取得するParagon Pathfinder pceserver ポッドsyslogコンテナの処理済みログを表示します。 |
|
|
Paragon Pathfinder pcserver pods ns-pcserver container のログを表示します。 |
|
|
Paragon Pathfinder pcserver pods syslog コンテナのログを表示します。 |
|
|
Paragon Pathfinder pceserver ポッドのsyslogコンテナのフェッチ処理済みログを、タイムスタンプ、レベル、メッセージのみで表示します。 |
|
|
Paragon Pathfinder pcviewer pods ns-pcviewer containerのログを表示します。 |
|
|
Paragon Pathfinder pcviewerポッドsyslogコンテナのログを表示します。 |
|
|
Paragon Pathfinderトポロジーサーバーポッドns-topo-dbinitコンテナのログを表示します。 |
|
|
Paragon Pathfinderトポサーバーポッドns-topo-dbinit-cacheコンテナのログを表示します。 |
|
|
Paragon Pathfinderトポサーバーポッドns-toposerverコンテナのログを表示します。 |
|
|
Paragon Pathfinderトポサーバーポッドのsyslogコンテナのログを表示します。 |
|
|
Paragon Pathfinderトポサーバーポッドsyslogコンテナのフェッチ処理済みログを、タイムスタンプ、レベル、メッセージのみで表示します。 |
|
|
Paragon Pathfinder ウェブポッド ns-web コンテナのログを表示します。 |
|
|
Paragon Pathfinder Web ポッド ns-web-dbinit コンテナのログを表示します。 |
|
|
Paragon Pathfinder ウェブポッドの syslog コンテナのログを表示します。 |
|
|
フェデレーションの状態を表示します (rabbitmq-0 インスタンスから)。GeoHa ステータスは、デュアル クラスター設定でのみ使用できます。 |
|
|
RookとCeph OSDファイルシステムのディスク容量の使用状況を報告します。 |
|
|
ルークとCephのOSDプールの統計情報を表示します。 |
|
|
ルークとセフのOSDステータスを表示します。 |
|
|
ルークとセフのOSDツリーを示しています。 |
|
|
は、RookとCephのOSDの使用率を示しています。 |
|
|
ルークとセフのページステータスを表示します。 |
|
|
ルークとセフのステータスを表示します。 |
|
|
ルークおよびCephツールボックスポッドのCLIにログインします。 |
|
|
ルークポッドとセフポッドを示しています。 |
|
|
ルークとセフのサービスを表示します。 |
|
|
これは、期間情報を取得するRADOSゲートウェイユーザー管理ユーティリティです。 |
|
|
これは、メタデータの同期ステータスを取得するRADOSゲートウェイユーザー管理ユーティリティです。 |
|
|
REST 呼び出し認証用の Paragon (UI ホスト) パスワードを設定します。 この必須のワンタイムパスワード設定コマンドを使用して、 例: |
|
|
Restコール認証用のParagon (UIホスト)ユーザー名を設定します。デフォルトのユーザー名は 別のユーザー名を設定するには、 例: |
CephとRookのトラブルシューティング
Cephには、比較的新しいカーネルバージョンが必要です。Linuxカーネルが非常に古い場合は、新しいカーネルのアップグレードまたは再インストールを検討してください。
このセクションを使用して、CephとRookに関する問題のトラブルシューティングを行います。
ディスク容量の不足
インストールが失敗する一般的な理由は、オブジェクトストレージデーモン(OSD)が作成されないことです。OSDは、クラスタノード上のストレージを設定します。OSDは、リソースが不足しているか、ディスク領域が正しくパーティション化されていないという形で、ディスクリソースが利用できないために作成されない可能性があります。ノードに十分な空きディスク・スペースがあることを確認します。
ディスクを再フォーマットする
「rook-ceph-osd-prepare-hostname-*」ジョブのログを調べます。ログは説明的です。ディスクまたはパーティションを再フォーマットしてRookを再起動する必要がある場合は、次の手順を実行します。
- 次のいずれかの方法を使用して、既存のディスクまたはパーティションを再フォーマットします。
- Cephに使用するはずだったブロックストレージデバイスがあるが、使用できない状態であったために使用されなかった場合は、ディスクを完全に再フォーマットできます。
$ sgdisk -zap /dev/disk $ dd if=/dev/zero of=/dev/disk bs=1M count=100
- Cephに使用するはずのディスクパーティションがある場合は、パーティション上のデータを完全にクリアできます。
$ wipefs -a -f /dev/partition $ dd if=/dev/zero of=/dev/partition bs=1M count=100
手記:これらのコマンドは、使用しているディスクまたはパーティションを完全に再フォーマットし、それらの上のすべてのデータが失われます。
- Cephに使用するはずだったブロックストレージデバイスがあるが、使用できない状態であったために使用されなかった場合は、ディスクを完全に再フォーマットできます。
- Rookを再起動して変更を保存し、OSDの作成プロセスを再試行します。
$ kubectl rollout restart deploy -n rook-ceph rook-ceph-operator
ポッドのステータスの表示
rook-ceph名前空間にインストールされているRookポッドとCephポッドのステータスを確認するには、# kubectl get po -n rook-cephコマンドを使用します。次のポッドはrunning状態である必要があります。
rook-ceph-mon-*- 通常、3 つのモニター ポッドが作成されます。rook-ceph-mgr-*- マネージャーポッド 1 台rook-ceph-osd-*- 3 つ以上の OSD ポッドrook-ceph-mds-cephfs-*—メタデータサーバーrook-ceph-rgw-object-store-*- オブジェクトストア・ゲートウェイrook-ceph-tools*- 追加のデバッグ オプション。ツールボックスに接続するには、次のコマンドを使用します。
$ kubectl exec -ti -n rook-ceph $(kubectl get po -n rook-ceph -l app=rook-ceph-tools \ -o jsonpath={..metadata.name}) -- bashツールボックスで使用できる一般的なコマンドには、次のようなものがあります。
# ceph status # ceph osd status, # ceph osd df, # ceph osd utilization, # ceph osd pool stats, # ceph osd tree, and # ceph pg stat
Ceph OSDの障害のトラブルシューティング
rook-ceph名前空間にインストールされているポッドの状態を確認します。
# kubectl get po -n rook-ceph
rook-ceph-osd-*ポッドがErrorまたはCrashLoopBackoff状態の場合は、ディスクを修復する必要があります。
-
rook-ceph-operatorを停止します。# kubectl scale deploy -n rook-ceph rook-ceph-operator --replicas=0 -
問題のあるOSDプロセスを削除します。
# kubectl delete deploy -n rook-ceph rook-ceph-osd-number -
ツールボックスに接続します。
$ kubectl exec -ti -n rook-ceph $(kubectl get po -n rook-ceph -l app=rook-ceph-tools -o jsonpath={..metadata.name}) -- bash -
問題のあるOSDを特定します。
# ceph osd status -
障害が発生したOSDをマークアウトします。
[root@rook-ceph-tools-/]# ceph osd out 5 marked out osd.5. [root@rook-ceph-tools-/]# ceph osd status ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE 0 10.xx.xx.210 4856M 75.2G 0 0 0 0 exists,up 1 10.xx.xx.215 2986M 77.0G 0 0 1 89 exists,up 2 10.xx.xx.98 3243M 76.8G 0 0 1 15 exists,up 3 10.xx.xx.195 4945M 75.1G 0 0 0 0 exists,up 4 10.xx.xx.170 5053M 75.0G 0 0 0 0 exists,up 5 10.xx.xx.197 0 0 0 0 0 0 exists
-
障害が発生したOSDを取り外します。
# ceph osd purge number --yes-i-really-mean-it - 障害が発生したOSDをホストしていたノードに接続し、次のいずれかを実行します。
- ハードウェア障害が発生した場合にハードディスクを交換してください。
- ディスクを完全に再フォーマットします。
$ sgdisk -zap /dev/disk $ dd if=/dev/zero of=/dev/disk bs=1M count=100
- パーティションを完全に再フォーマットします。
$ wipefs -a -f /dev/partition $ dd if=/dev/zero of=/dev/partition bs=1M count=100
-
rook-ceph-operatorを再起動します。# kubectl scale deploy -n rook-ceph rook-ceph-operator --replicas=1 -
OSDポッドを監視します。
# kubectl get po -n rook-cephOSDが回復しない場合は、同じ手順でOSDを取り外し、ディスクを取り外すかパーティションを削除してから再起動
rook-ceph-operator。
エアギャップ設置失敗のトラブルシューティング
エアギャップのインストールと kube-apiserver は、既存の /etc/resolv.conf ファイルがないため、次のエラーで失敗します。
TASK [kubernetes/master : Activate etcd backup cronjob] ******************************************************************** fatal: [192.xx.xx.2]: FAILED! => changed=true cmd: - kubectl - apply - -f - /etc/kubernetes/etcd-backup.yaml delta: '0:00:00.197012' end: '2022-09-13 13:46:31.220256' msg: non-zero return code rc: 1 start: '2022-09-13 13:46:31.023244' stderr: The connection to the server 192.xx.xx.2:6443 was refused - did you specify the right host or port? stderr_lines: <omitted> stdout: '' stdout_lines: <omitted>
新しいファイルを作成するには、ルートユーザーとして #touch /etc/resolv.conf コマンドを実行し、Paragon Automation クラスターを再デプロイする必要があります。
RabbitMQ クラスターの障害から復旧する
この状態を確認するには、 kubectl get po -n northstar -l app=rabbitmq コマンドを実行します。このコマンドでは、状態が Running の 3 つのポッドが表示されます。例えば:
$ kubectl get po -n northstar -l app=rabbitmq NAME READY STATUS RESTARTS AGE rabbitmq-0 1/1 Running 0 10m rabbitmq-1 1/1 Running 0 10m rabbitmq-2 1/1 Running 0 9m37s
ただし、1 つ以上のポッドの状態が Error の場合は、次の回復手順を使用します。
-
RabbitMQを削除します。
kubectl delete po -n northstar -l app=rabbitmq -
ポッドの状態を確認します。
kubectl get po -n northstar -l app=rabbitmq.すべてのポッドの状態が
Runningになるまで、kubectl delete po -n northstar -l app=rabbitmqを繰り返します。 -
Paragon Pathfinderアプリケーションを再起動します。
kubectl rollout restart deploy -n northstar
OSD作成中にudevdデーモンを無効にする
udevd デーモンは、ディスク、ネットワーク・カード、CD などの新しいハードウェアを管理するために使用します。OSDの作成中に、
udevdデーモンはOSDを検出し、完全に初期化される前にOSDをロックできます。Paragon Automationインストーラは、インストール中に
systemd-udevdを無効にし、RookがOSDを初期化した後に有効にします。
ノードを追加または交換し、障害が発生したノードを修復する場合は、OSDの作成が失敗しないように、 udevd デーモンを手動で無効にする必要があります。OSDの作成後にデーモンを再度有効にすることができます。
これらのコマンドを使用して、 udevdを手動で無効または有効にします。
- 追加または修復するノードにログインします。
udevdデーモンを使用不可にします。- udevdが実行されているかどうかを確認してください。
# systemctl is-active systemd-udevd udevdがアクティブな場合は、無効にします。# systemctl mask system-udevd --now
- udevdが実行されているかどうかを確認してください。
-
ノードを修復または交換しても、Ceph分散ファイルシステムは自動的に更新されません。修復プロセスの一環としてデータ・ディスクが破壊された場合は、それらのデータ・ディスクでホストされているオブジェクト・ストレージ・デーモン(OSD)をリカバリする必要があります。
-
Cephツールボックスに接続し、OSDのステータスを表示します。
ceph-toolsスクリプトは、プライマリ ノードにインストールされます。プライマリノードにログインし、kubectl インターフェイスを使用してceph-toolsにアクセスできます。1 次ノード以外のノードを使用するには、 admin.conf ファイル (制御ホストの config-dir ディレクトリーにある) をコピーしてkubeconfig環境変数を設定するか、またはexport KUBECONFIG=config-dir/admin.confコマンドを使用する必要があります。$ ceph-tools# ceph osd status -
すべてのOSDが
exists,upとして表示されていることを確認します。OSDが破損している場合は、 CephとRookのトラブルシューティングで説明されているトラブルシューティング手順に従ってください。
-
- すべてのOSDが作成されたことを確認した後、追加または修復したノードにログインします。
-
ノードで
udevdを再度有効にします。systemctl unmask system-udevd
disable_udevd: true を設定し、
./run -c config-dir deployコマンドを実行することもできます。
udevd デーモンを無効にするためだけにクラスターを再デプロイすることはお勧めしません。
共通ユーティリティコマンドのラッパースクリプト
| コマンド | の説明 |
|---|---|
paragon-db [arguments] |
データベース サーバーに接続し、スーパーユーザー アカウントを使用して Postgres SQL シェルを起動します。オプションの引数が Postgres SQL コマンドに渡されます。 |
pf-cmgd [arguments] |
Paragon Pathfinder CMGD ポッドで CLI を起動します。オプションの引数は CLI によって実行されます。 |
pf-crpd [arguments] |
Paragon Pathfinder cRPD ポッドで CLI を起動します。オプションの引数は CLI によって実行されます。 |
pf-redis [arguments] |
Paragon Pathfinder Redis ポッドで(認証された)redis-cli を起動します。省略可能な引数は、Redis ポッドによって実行されます。 |
pf-debugutils [arguments] |
Paragon Pathfinder debugutils ポッドでシェルを起動します。オプションの引数はシェルによって実行されます。Pathfinder debugutils ユーティリティは、config.yml ファイルでinstall_northstar_debugutils: trueが構成されている場合にインストールされます。 |
ceph-tools [arguments] |
シェルを起動してCephツールボックスに移動します。オプションの引数はシェルによって実行されます。 |
制御ホストのバックアップ
または、次のコマンドを使用してクラスターから情報をダウンロードして、 インベントリ ファイルと config.yml ファイルを再構築することもできます。
# kubectl get cm -n common metadata -o jsonpath={..inventory} > inventory
# kubectl get cm -n common metadata -o jsonpath={..config_yml} > config.yml
SSH キーを回復することはできません。失敗したキーを新しいキーに置き換える必要があります。
デバッグ用のユーザー サービス アカウント
Paragon Pathfinder、テレメトリマネージャー、ベースプラットフォームアプリケーションは、テレメトリ収集にParagon Insightsを内部的に使用します。これらのアプリケーションに関連する設定の問題をデバッグするために、Paragon Automationのインストール中に、デフォルトで3つのユーザーサービスアカウントが作成されます。これらのサービス アカウントのスコープは、対応するアプリケーションのデバッグのみに限定されます。サービス アカウントの詳細を次の表に示します。
| アプリケーション名とスコープ | アカウントユーザー名 | アカウントのデフォルトパスワード |
|---|---|---|
| パラゴンパスファインダー(北極星) | HB-ノーススター-管理者 | 管理者123! |
| テレメトリ マネージャー (tm) | hb-tm-admin | |
| ベースプラットフォーム(ems-dmon) | HB-EMS-DMON |
これらのアカウントは、デバッグ目的でのみ使用する必要があります。これらのアカウントは、日常的な操作や構成の変更には使用しないでください。セキュリティ上の理由から、ログイン資格情報を変更することをお勧めします。