로드 밸런싱 개요
어그리게이션 이더넷 인터페이스의 로드 밸런싱 및 MAC 주소를 기반으로 로드 밸런싱을 구성하는 방법에 대해 알아보십시오. 여러 인터페이스 간에 트래픽을 분할하여 네트워크 혼잡을 줄입니다.
레이어 2의 로드 밸런싱은 멤버 링크 전반에 트래픽을 분산합니다. 이 접근 방식은 중복을 유지하면서 혼잡을 방지합니다. 다음 주제에서는 로드 밸런싱의 기본 사항과 MAC 주소를 기반으로 구성하는 방법, LAG 링크에서 일관성을 위해 탄력적인 해싱을 사용하는 방법을 다룹니다.
로드 밸런싱 및 이더넷 링크 어그리게이션 개요
이더넷 포트 그룹에 대한 LAG를 생성할 수 있습니다. L2 브리징 트래픽은 이 그룹의 멤버 링크 간에 로드 밸런싱이 이루어지므로, 혼잡 우려와 중복 측면에서도 매력적인 구성이 가능합니다. 각 LAG 번들은 최대 16개의 링크를 포함합니다. 플랫폼 지원은 설치한 Junos OS 릴리스에 따라 다릅니다.
LAG 번들의 경우, 해싱 알고리즘은 LAG 번들로 들어오는 트래픽이 번들의 멤버 링크에 배치되는 방식을 결정합니다. 해싱 알고리즘은 번들의 멤버 링크에서 들어오는 모든 트래픽을 균등하게 로드 밸런싱하여 대역폭을 관리하려고 합니다. 해싱 알고리즘의 해시 모드는 기본적으로 L2 페이로드로 설정됩니다. 해시 모드가 L2 페이로드로 설정되면 해싱 알고리즘은 해싱에 IPv4 및 IPv6 페이로드 필드를 사용합니다. 또한 명령문을 사용하여 L3 및 레이어 4 헤더의 필드를 사용하도록 L2 트래픽에 대한 로드 밸런싱 해시 키를 구성할 수도 있습니다 payload . 그러나 로드 밸런싱 동작은 플랫폼에 따라 다르며 적절한 해시 키 구성을 기반으로 합니다.
자세한 정보는 LAG 링크에서 로드 밸런싱 구성을 참조하십시오. L2 스위치에서 한 링크는 과도하게 활용되고 다른 링크는 충분히 활용되지 않습니다.
MAC 주소를 기반으로 로드 밸런싱 구성
로드 밸런싱을 위한 해시 키 메커니즘은 프레임 소스 및 대상 주소와 같은 L2 MAC 정보를 사용합니다. L2 MAC 정보를 기반으로 트래픽을 로드 밸런싱하려면 또는 [edit chassis fpc slot number pic PIC number hash-key] 계층 수준에서 [edit forwarding-options hash-key] 문을 포함 multiservice 합니다.
multiservice {
source-mac;
destination-mac;
payload {
ip {
layer3-only;
layer-3 (source-ip-only | destination-ip-only);
layer-4;
inner-vlan-id;
outer-vlan-id;
}
}
}
기능 탐색기를 사용하여 특정 기능에 대한 플랫폼 및 릴리스 지원을 확인하십시오.
플랫폼과 관련된 참고 사항은 플랫폼별 MAC 주소 기반 로드 밸런싱 동작 섹션을 검토합니다.
해시 키에 대상 주소 MAC 정보를 포함하려면, 옵션을 destination-mac 포함합니다. 해시 키에 소스 주소 MAC 정보를 포함하려면, 옵션을 source-mac 포함합니다.
-
소스 및 대상 주소가 동일한 패킷은 동일한 경로를 통해 전송됩니다.
-
패킷당 로드 밸런싱을 구성하여 여러 경로에서 EVPN 트래픽 흐름을 최적화할 수 있습니다.
-
어그리게이션 이더넷 멤버 링크는 이제 물리적 MAC 주소를 802.3ah OAM 패킷의 소스 MAC 주소로 사용합니다.
플랫폼별 MAC 주소 기반 로드 밸런싱 동작
| 플랫폼 |
다름 |
|---|---|
| ACX 시리즈 |
|
또한보십시오
LAG 링크에서 로드 밸런싱 구성
L2 트래픽에 대한 로드 밸런싱 해시 키를 구성하여 문을 사용하여 payload 로드 밸런싱을 위해 프레임 페이로드 내부의 L3 및 레이어 4 헤더의 필드를 사용할 수 있습니다. 레이어 3 및 source-ip-only 또는 destination-ip-only 패킷 헤더 필드를 보도록 문을 구성할 수 있습니다. 레이어 4 필드도 살펴볼 수 있습니다. 이 명령문은 계층 수준에서 구성합니다.[edit forwarding-options hash-key family multiservice]
L3 또는 레이어 4 옵션 또는 둘 다를 구성할 수 있습니다. source-ip-only 또는 destination-ip-only 옵션은 상호 배타적입니다. 이 layer-3-only 문은 MX 시리즈 라우터에서는 사용할 수 없습니다.
기본적으로 802.3ad의 Junos 구현은 패킷에 전달되는 L3 정보를 기반으로 어그리게이션 이더넷 번들 내의 멤버 링크 전체에서 트래픽 균형을 유지합니다.
LAG 구성에 대한 자세한 내용은 라우팅 디바이스용 Junos OS 네트워크 인터페이스 라이브러리를 참조하십시오.
본보기:
이 예에서는 소스 L3 IP 주소 옵션 및 레이어 4 헤더 필드를 사용하도록 로드 밸런싱 해시 키를 구성합니다. 이 예에는 LAG 링크에서 로드 밸런싱을 위한 소스 및 대상 MAC 주소도 포함되어 있습니다.
[edit]
forwarding-options {
hash-key {
family multiservice {
source-mac;
destination-mac;
payload {
ip {
layer-3 {
source-ip-only;
}
layer-4;
}
}
}
}
}
해시 키 구성을 변경하면 변경 사항을 적용하려면 FPC를 재부팅해야 합니다.
예: LAG 링크에서 로드 밸런싱 구성
이 예에서는 소스 레이어 3 IP 주소 옵션 및 레이어 4 헤더 필드와 링크 어그리게이션 그룹(LAG) 링크의 로드 로드 밸런싱을 위한 소스 및 대상 MAC 주소를 사용하도록 로드 밸런싱 해시 키를 구성합니다.
[edit]
forwarding-options {
hash-key {
family multiservice {
source-mac;
destination-mac;
payload {
ip {
layer-3 {
source-ip-only;
}
layer-4;
}
}
}
}
}
해시 키 구성을 변경하면 변경 사항을 적용하려면 FPC를 재부팅해야 합니다.
EX8200 스위치에서 라우팅된 멀티캐스트 트래픽에 대한 어그리게이션 10기가비트 링크의 멀티캐스트 로드 밸런싱 이해
스트리밍 비디오는 1997년에 도입된 이후 많은 발전을 이루었습니다. 처음에는 주로 가끔 프레젠테이션에 사용되었습니다. 그러나 인기가 높아짐에 따라 모든 사용자에게 별도의 스트림을 전송하는 것은 빠르게 네트워크에 과부하가 발생했습니다.
이를 해결하기 위해 멀티캐스트 프로토콜이 개발되었습니다. 멀티캐스트를 사용하면 서버가 개별 스트림을 각 수신자 그룹에 보내는 대신 단일 데이터 스트림을 전체 수신자 그룹에 한 번에 보낼 수 있습니다. 전체 수신자 그룹에 단일 데이터 스트림을 한 번에 전송하면 데이터 중복과 네트워크 혼잡이 크게 줄어들어 영화, 뉴스 및 기타 비디오를 모든 장치로 지속적으로 전송할 수 있습니다.
멀티캐스팅을 사용하더라도 방대한 양의 비디오 데이터는 여전히 네트워크 하드웨어와 대역폭에 부담을 줍니다. 이로 인해 전송 중에 성가신 번거림과 끊김 현상이 발생하는 경우가 많았습니다.
이를 해결하기 위해 네트워크 엔지니어들은 여러 물리적 링크를 하나의 더 큰 논리적 채널로 결합하기 시작했습니다. 이러한 가상 연결을 멀티캐스트 인터페이스 또는 LAG라고 합니다.
멀티캐스트 로드 밸런싱은 LAG의 각 개별 링크가 효율적으로 사용되도록 보장합니다. 해싱 알고리즘을 사용하여 데이터 스트림을 지속적으로 평가하고 링크 전체에 배포되는 방식을 조정합니다. 이렇게 하면 단일 링크가 과부하되거나 충분히 사용되지 않는 것을 방지할 수 있습니다. 주니퍼 네트웍스 EX8200 이더넷 스위치에서는 기본적으로 멀티캐스트 로드 밸런싱이 활성화되어 있습니다.
이 주제에는 다음이 포함됩니다.
- 멀티캐스팅을 위한 LAG를 10기가비트 단위로 생성합니다
- 멀티캐스트 로드 밸런싱은 언제 사용해야 합니까?
- 멀티캐스트 로드 밸런싱은 어떻게 작동합니까?
- EX8200 스위치에서 멀티캐스트 로드 밸런싱을 구현하려면 어떻게 해야 합니까?
멀티캐스팅을 위한 LAG를 10기가비트 단위로 생성합니다
EX8200 스위치의 최대 링크 크기는 10기가비트입니다. EX8200 스위치에서 더 큰 링크가 필요한 경우, 최대 12개의 10기가비트 링크를 결합할 수 있습니다. 그림 1에 표시된 샘플 토폴로지에서는 4개의 10기가비트 링크가 어그리게이션되어 각 40기가비트 링크를 형성합니다.
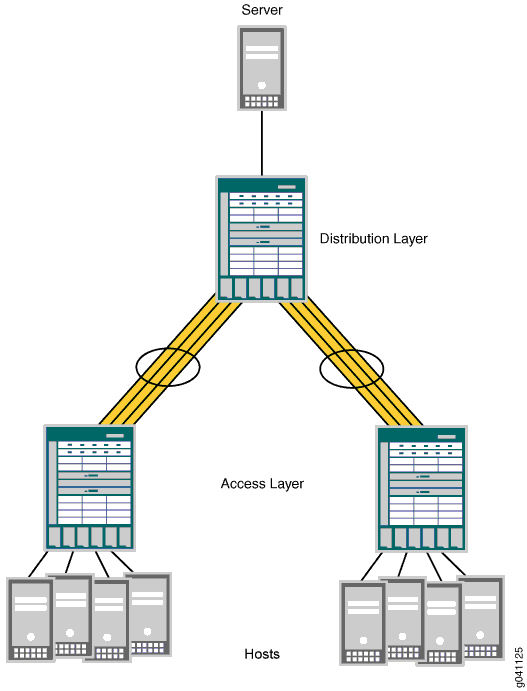
멀티캐스트 로드 밸런싱은 언제 사용해야 합니까?
10기가비트보다 큰 다운스트림 링크가 필요한 경우 멀티캐스트 로드 밸런싱과 함께 LAG를 사용합니다. 이러한 필요성은 서비스 프로바이더 역할을 하거나 많은 청중에게 비디오를 멀티캐스트할 때 자주 발생합니다.
멀티캐스트 로드 밸런싱을 사용하려면 다음이 필요합니다.
-
EX8200 스위치 - 독립형 스위치는 멀티캐스트 로드 밸런싱을 지원하지만 Virtual Chassis 는 지원하지 않습니다.
-
L3 라우팅 멀티캐스트 설정 - 멀티캐스팅 구성에 대한 자세한 내용은 Junos OS 라우팅 프로토콜 구성 가이드를 참조하십시오.
-
LAG의 어그리게이션 10기가비트 링크 - 멀티캐스트 로드 밸런싱으로 LAG를 구성하는 방법에 대한 정보는 EX8200 스위치에서 어그리게이션 10기가비트 이더넷 링크와 함께 사용하기 위한 멀티캐스트 로드 밸런싱 구성(CLI 절차)을 참조하십시오.
멀티캐스트 로드 밸런싱은 어떻게 작동합니까?
트래픽이 여러 멤버 링크를 사용할 수 있는 경우, 동일한 스트림의 일부인 트래픽은 항상 동일한 링크에 있어야 합니다.
멀티캐스트 로드 밸런싱은 7가지 해싱 알고리즘 중 하나를 사용하여 사용 가능한 모든 어그리게이션 링크에 데이터 스트림을 효율적으로 배포합니다. 또한 트래픽의 균형을 맞추기 위해 대기열 섞이라는 기술을 사용합니다.
특정 알고리즘을 선택하거나 crc-sgip인 기본값을 사용할 수 있습니다. 이 기본 알고리즘은 멀티캐스트 패킷의 그룹 IP 주소에 대한 순환 중복 검사(CRC)를 사용합니다. 기본값부터 시작하여 L3 트래픽이 균등하게 분산되지 않는 경우에만 다른 옵션을 시도하는 것이 좋습니다.
해싱 알고리즘 이해하기
7개의 알고리즘 중 6개는 IP 주소의 해시된 값을 기반으로 하며 항상 동일한 데이터 스트림에 대해 동일한 결과를 생성합니다. 그러나 균형 모드 옵션은 스트림이 추가되는 순서에 따라 결과가 변경될 수 있기 때문에 고유합니다.
자세한 정보는 표 1 을 참조하십시오.
| 해싱 알고리즘 |
총 |
최고의 사용 |
|---|---|---|
| CRC-SGIP |
멀티캐스트 패킷의 소스 및 그룹 IP 주소에 대한 순환 중복 검사 |
기본값 - 10기가비트 이더넷 네트워크에서 IP 트래픽의 고성능 관리. 매번 동일한 링크에 대한 할당 예측 가능. 이 모드는 복잡하지만 좋은 분산 해시를 생성합니다. |
| CRC-GIP |
멀티캐스트 패킷의 그룹 IP 주소에 대한 순환 중복 검사 |
매번 동일한 링크에 대한 할당 예측 가능. crc-sgip가 L3 라우팅 멀티캐스트 트래픽을 균등하게 분산하지 않고 그룹 IP 주소가 다를 때 이 모드를 시도하십시오. |
| CRC-SIP |
멀티캐스트 패킷의 소스 IP 주소에 대한 CRC |
매번 동일한 링크에 대한 할당 예측 가능. crc-sgip가 L3 라우팅 멀티캐스트 트래픽을 균등하게 분산하지 않고 스트림 소스가 다를 때 이 모드를 시도하십시오. |
| 단순-sgip |
멀티캐스트 패킷의 소스 및 그룹 IP 주소의 XOR 계산 |
매번 동일한 링크에 대한 할당 예측 가능. 이것은 crc-sgip 산출만큼 균등한 분포를 산출하지 못할 수 있는 간단한 해싱 방법입니다. crc-sgip가 L3 라우팅 멀티캐스트 트래픽을 균등하게 분산하지 않을 때 이 모드를 시도하십시오. |
| 단순 gip |
멀티캐스트 패킷의 그룹 IP 주소에 대한 XOR 계산 |
매번 동일한 링크에 대한 할당 예측 가능. 이것은 crc-gip만큼 균등한 분포를 산출하지 못할 수 있는 간단한 해싱 방법입니다. crc-gip가 L3 라우팅 멀티캐스트 트래픽을 균등하게 분산하지 않고 그룹 IP 주소가 다를 때 이 방법을 시도하십시오. |
| 심플 SIP |
멀티캐스트 패킷의 소스 IP 주소에 대한 XOR 계산 |
매번 동일한 링크에 대한 할당 예측 가능. 이것은 간단한 해싱 방법으로, crc-sip의 산출만큼 균등한 분포를 산출하지 못할 수도 있습니다. crc-sip이 L3 라우팅 멀티캐스트 트래픽을 균등하게 분산하지 않고 스트림 소스가 다를 때 이 모드를 시도하십시오. |
| 균형 잡힌 |
트래픽 양이 가장 적은 멀티캐스트 링크를 식별하는 데 사용되는 라운드 로빈 계산 방법 |
최상의 균형이 달성되지만 스트림이 온라인으로 전환되는 순서에 따라 달라지므로 어떤 링크가 일관되게 사용될지 예측할 수 없습니다. 재부팅할 때마다 일관된 할당이 필요하지 않을 때 사용합니다. |
EX8200 스위치에서 멀티캐스트 로드 밸런싱을 구현하려면 어떻게 해야 합니까?
EX8200 스위치에서 최적화된 처리량 수준으로 멀티캐스트 로드 밸런싱을 구현하려면 다음 권장 사항을 따르십시오.
-
멀티캐스트 인터페이스 공유로 인한 링크 변경으로 인한 동적 불균형을 수용하기 위해 어그리게이션 링크에서 25%의 미사용 대역폭을 허용합니다.
-
다운스트림 링크의 경우 가능하면 동일한 크기의 멀티캐스트 인터페이스를 사용합니다. 또한 다운스트림 어그리게이션 링크의 경우 어그리게이션 링크의 구성원이 동일한 디바이스에 속할 때 처리량이 최적화됩니다.
-
업스트림 어그리게이션 링크의 경우, 가능하면 L3 링크를 사용합니다. 또한 업스트림 어그리게이션 링크의 경우 어그리게이션 링크의 구성원이 서로 다른 디바이스에 속할 때 처리량이 최적화됩니다.
또한보십시오
예: EX8200 스위치에서 어그리게이션 10기가비트 이더넷 인터페이스와 함께 사용하기 위한 멀티캐스트 로드 밸런싱 구성
EX8200 스위치는 LAG에서 멀티캐스트 로드 밸런싱을 지원합니다. 멀티캐스트 로드 밸런싱은 LAG를 통해 L3 라우팅 멀티캐스트 트래픽을 균등하게 분산합니다. 최대 12개의 10기가비트 이더넷 링크를 어그리게이션하여 120기가비트 가상 링크 또는 LAG를 형성할 수 있습니다. MAC 클라이언트는 이 가상 링크를 단일 링크인 것처럼 처리하여 대역폭을 늘리고, 링크 장애가 발생할 때 Graceful Degradation을 제공하며, 가용성을 높일 수 있습니다. EX8200 스위치에서는 기본적으로 멀티캐스트 로드 밸런싱이 활성화되어 있습니다. 그러나 명시적으로 비활성화된 경우 다시 활성화할 수 있습니다.
이미 구성된 IP 주소를 가진 인터페이스는 LAG의 일부를 형성할 수 없습니다.
10기가비트 링크가 있는 EX8200 독립형 스위치만 멀티캐스트 로드 밸런싱을 지원합니다. Virtual Chassis는 멀티캐스트 로드 밸런싱을 지원하지 않습니다.
이 예는 LAG를 구성하고 멀티캐스트 로드 밸런싱을 다시 활성화하는 방법을 보여줍니다.
요구 사항
이 예에서 사용되는 하드웨어 및 소프트웨어 구성 요소는 다음과 같습니다.
EX8200 스위치 두 개(액세스 스위치로 사용하는 한 개와 분산 스위치로 사용되는 한 개)
EX 시리즈 스위치용 Junos OS 릴리스 12.2 이상
시작하기 전에:
EX8200 분산 스위치에서 4개의 10기가비트 인터페이스(xe-0/1/0, xe-1/1/0, xe-2/1/0, xe-3/1/0)를 구성합니다. 기가비트 이더넷 인터페이스 구성(CLI 절차)을 참조하십시오.
개요 및 토폴로지
멀티캐스트 로드 밸런싱은 7개의 해싱 알고리즘 중 하나를 사용하여 LAG의 개별 10기가비트 링크 간에 트래픽을 분산합니다. 해싱 알고리즘에 대한 설명은 멀티캐스트 로드 밸런싱을 참조하십시오. 기본 해싱 알고리즘은 crc-sgip입니다. L3 라우팅된 멀티캐스트 트래픽의 균형을 가장 잘 맞추는 알고리즘을 결정할 때까지 다양한 해싱 알고리즘을 실험할 수 있습니다.
EX8200 스위치에서 10기가비트보다 큰 링크가 필요한 경우, 최대 12개의 10기가비트 링크를 결합하여 더 많은 대역폭을 생성할 수 있습니다. 이 예에서는 링크 어그리게이션 기능을 사용하여 배포 스위치에서 4개의 10기가비트 링크를 40기가비트 링크로 결합합니다. 또한 멀티캐스트 로드 밸런싱을 통해 40기가비트 링크에서 레이어 3 라우팅된 멀티캐스트 트래픽을 균등하게 분산할 수 있습니다. 그림 2에 표시된 샘플 토폴로지에서 배포 레이어의 EX8200 스위치는 액세스 레이어의 EX8200 스위치에 연결됩니다.
링크 속도는 구성된 LAG의 크기에 따라 자동으로 결정됩니다. 예를 들어, LAG가 4개의 10기가비트 링크로 구성된 경우, 링크 속도는 40Gbps입니다.
기본 해싱 알고리즘인 crc-sgip는 멀티캐스트 패킷 소스 및 그룹 IP 주소 모두에 대한 순환 중복 검사(CRC)를 포함합니다.
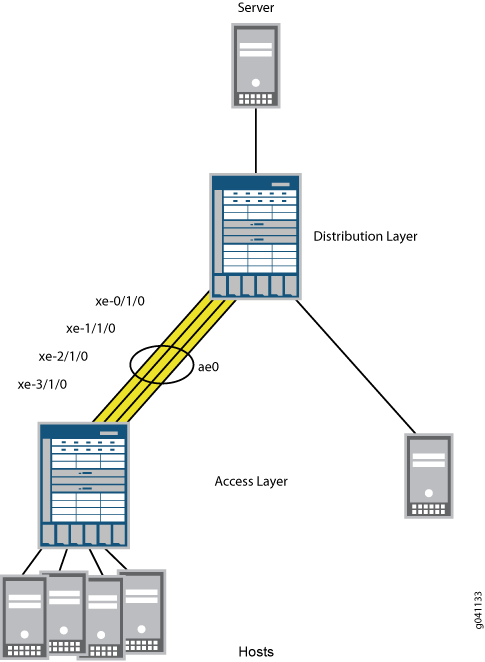
각 스위치에서 LAG를 구성하고 멀티캐스트 로드 밸런싱을 다시 활성화합니다. 다시 활성화되면 멀티캐스트 로드 밸런싱이 LAG에 자동으로 적용되며 속도는 LAG의 각 링크에 대해 10Gbps로 설정됩니다. 40기가비트 LAG의 링크 속도는 자동으로 40Gbps로 설정됩니다.
구성
절차
CLI 빠른 구성
set chassis aggregated-devices ethernet device-count 1 set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces xe-0/1/0 ether-options 802.3ad ae0 set interfaces xe-1/1/0 ether-options 802.3ad ae0 set interfaces xe-2/1/0 ether-options 802.3ad ae0 set interfaces xe-3/1/0 ether-options 802.3ad ae0 set chassis multicast-loadbalance hash-mode crc-gip
단계별 절차
LAG를 구성하고 멀티캐스트 로드 밸런싱을 다시 활성화하려면:
생성할 어그리게이션 이더넷 인터페이스(aex)의 수를 지정합니다.
[edit chassis] user@switch#
set aggregated-devices ethernet device-count 1레이블을 지정할 aex, 즉 LAG의 최소 링크 수를 지정합니다.
up기본적으로 LAG에 레이블을 지정
up하려면 하나의 링크만 실행되어야 합니다.[edit interfaces] user@switch#
set ae0 aggregated-ether-options minimum-links 1LAG에 포함할 4개의 멤버를 지정합니다.
[edit interfaces] user@switch#
set xe-0/1/0 ether-options 802.3ad ae0user@switch#set xe-1/1/0 ether-options 802.3ad ae0user@switch#set xe-2/1/0 ether-options 802.3ad ae0user@switch#set xe-3/1/0 ether-options 802.3ad ae0멀티캐스트 로드 밸런싱 재활성화:
[edit chassis] user@switch# set multicast-loadbalance멀티캐스트 로드 밸런싱을 사용하지 않는 LAG와 같은 방식으로 링크 속도를 설정할 필요가 없습니다. 링크 속도는 40기가비트 LAG에서 40Gbps로 자동으로 설정됩니다.
선택적으로 멀티캐스트-loadbalance 명령문에서 옵션 값을
hash-mode변경하여 L3 라우팅된 멀티캐스트 트래픽을 가장 잘 분산하는 알고리즘을 찾을 때까지 다른 알고리즘을 시도할 수 있습니다.멀티캐스트 로드 밸런싱이 비활성화되었을 때 해싱 알고리즘을 변경하면 멀티캐스트 로드 밸런싱을 다시 활성화한 후 새 알고리즘이 적용됩니다.
결과
구성 결과를 확인합니다.
user@switch> show configuration
chassis
aggregated-devices {
ethernet {
device-count 1;
}
}
multicast-loadbalance {
hash-mode crc-gip;
}
interfaces
xe-0/1/0 {
ether-options {
802.3ad ae0;
}
}
xe-1/1/0 {
ether-options {
802.3ad ae0;
}
}
xe-2/1/0 {
ether-options {
802.3ad ae0;
}
}
xe-3/1/0 {
ether-options {
802.3ad ae0;
}
}
ae0 {
aggregated-ether-options {
minimum-links 1;
}
}
}
확인
구성이 제대로 작동하는지 확인하려면 다음 작업을 수행하십시오.
LAG 인터페이스의 상태 확인
목적
스위치에 LAG(ae0)가 생성되었는지 확인합니다.
행동
ae0 LAG가 생성되었는지 확인합니다.
user@switch> show interfaces ae0 terse
Interface Admin Link Proto Local Remote ae0 up up ae0.0 up up inet 10.10.10.2/24
의미
인터페이스 이름 aex 는 LAG를 나타냅니다. A 는 어그리게이션, E 는 이더넷을 나타냅니다. 숫자는 다양한 LAG를 구별합니다.
멀티캐스트 로드 밸런싱 확인
목적
트래픽이 경로 전반에서 균등하게 로드 밸런싱되는지 확인합니다.
행동
4개의 인터페이스에서 로드 밸런싱을 확인합니다.
user@switch> monitor interface traffic
Bytes=b, Clear=c, Delta=d, Packets=p, Quit=q or ESC, Rate=r, Up=^U, Down=^D ibmoem02-re1 Seconds: 3 Time: 16:06:14 Interface Link Input packets (pps) Output packets (pps) xe-0/1/0 Up 2058834 (10) 7345862 (19) xe-1/1/0 Up 2509289 (9) 6740592 (21) xe-2/1/0 Up 8625688 (90) 10558315 (20) xe-3/1/0 Up 2374154 (23) 71494375 (9)
의미
인터페이스는 거의 동일한 양의 트래픽을 전달해야 합니다.
변경 내역 표
기능 지원은 사용 중인 플랫폼과 릴리스에 따라 결정됩니다. 기능 탐색기를 사용하여 플랫폼에서 기능이 지원되는지 확인합니다.
payload 사용하여 레이어 3 및 레이어 4 헤더의 필드를 사용할 수도 있습니다.