RMON을 사용하여 네트워크 서비스 품질 모니터링
서비스 품질 모니터링을 위한 RMON
상태 및 성능 모니터링은 각 라우터에서 실행되는 로컬 SNMP 에이전트에 의한 SNMP 변수의 원격 모니터링을 통해 이점을 얻을 수 있습니다. SNMP 에이전트는 관리 정보 베이스(MIB) 값을 사전 정의된 임계값과 비교하여 중앙 SNMP 관리 플랫폼에서 폴링할 필요 없이 예외 알람을 생성합니다. 이는 임계값에 기준선이 올바르게 결정되고 설정된 한 사전 예방적 관리를 위한 효과적인 메커니즘입니다. 자세한 내용은 RFC 2819, 원격 네트워크 모니터링 관리 정보 베이스(MIB)를 참조하십시오.
이 주제는 다음 섹션을 포함합니다.
임계값 설정
모니터링되는 변수에 대해 상승 및 하강 임계값을 설정하면 변수 값이 허용 가능한 작동 범위를 벗어날 때마다 경고를 받을 수 있습니다. (그림 1을(를) 참조하십시오.)
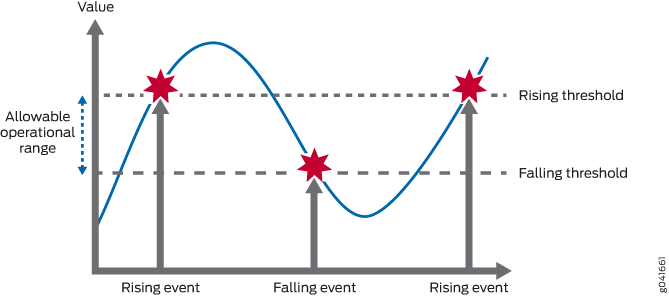
이벤트는 각 샘플 기간 이후가 아니라 임계 값이 한 방향으로 처음 교차 될 때만 생성됩니다. 예를 들어, 상승 임계값 교차 이벤트가 발생하면 해당 하강 이벤트가 발생할 때까지 더 이상 임계값 교차 이벤트가 발생하지 않습니다. 이렇게 하면 시스템에서 생성되는 경보의 양이 상당히 줄어들어 경보가 발생할 때 운영 직원이 더 쉽게 대응할 수 있습니다.
원격 모니터링을 구성하려면 다음 정보를 지정합니다.
모니터링할 변수(SNMP 개체 식별자 기준)
각 검사 사이의 시간
상승하는 문턱
떨어지는 문턱
떠오르는 사건
떨어지는 사건
원격 모니터링을 성공적으로 구성하려면 먼저 모니터링해야 하는 변수와 허용 가능한 작동 범위를 식별해야 합니다. 이를 위해서는 허용 가능한 작동 범위를 결정하기 위해 일정 기간의 기준선 설정이 필요합니다. 운영 범위를 처음 식별하고 임계값을 정의할 때 최소 3개월의 초기 기준 기간은 드문 일이 아니지만 기준 모니터링은 모니터링되는 각 변수의 수명 동안 계속되어야 합니다.
RMON 명령줄 인터페이스
Junos OS는 라우터에서 원격 모니터링 에이전트를 제어하는 데 사용할 수 있는 두 가지 메커니즘을 제공합니다. 명령줄 인터페이스(CLI) 및 SNMP. CLI를 사용하여 RMON 항목을 구성하려면 계층 수준에서 다음 문을 [edit snmp] 포함합니다.
rmon {
alarm index {
description;
falling-event-index;
falling-threshold;
intervals;
rising-event-index;
rising-threshold;
sample-type (absolute-value | delta-value);
startup-alarm (falling | rising | rising-or-falling);
variable;
}
event index {
community;
description;
type (log | trap | log-and-trap | none);
}
}
CLI 액세스 권한이 없는 경우 SNMP 액세스 권한이 부여되었다고 가정하고 SNMP 관리자 또는 관리 애플리케이션을 사용하여 원격 모니터링을 구성할 수 있습니다. (참조 표 1.) SNMP를 사용하여 RMON을 구성하려면 RMON 이벤트 및 알람 테이블에 대한 SNMP Set 요청을 수행합니다.
RMON 이벤트 테이블
생성하려는 각 유형에 대한 이벤트를 설정합니다. 예를 들어, 상승 및 하강이라는 두 개의 일반 이벤트 또는 모니터링 중인 각 변수에 대해 서로 다른 여러 이벤트(예: 온도 상승 이벤트, 온도 낙하 이벤트, 방화벽 히트 이벤트, 인터페이스 사용률 이벤트 등)가 있을 수 있습니다. 이벤트가 구성되면 업데이트할 필요가 없습니다.
필드 |
설명 |
|---|---|
|
이 이벤트에 대한 텍스트 설명 |
|
이벤트 유형(예: |
|
이 이벤트를 전송할 트랩 그룹(Junos OS 구성에 정의된 대로, 커뮤니티와 동일하지 않음) |
|
이 이벤트를 만든 엔터티(예: |
|
이 행의 상태(예: |
RMON 알람 테이블
RMON 알람 테이블은 모니터링 중인 변수의 SNMP 개체 식별자(인스턴스 포함)를 상승 및 하강 임계값 및 해당 이벤트 인덱스와 함께 저장합니다. RMON 요청을 만들려면 에 표 2표시된 필드를 지정합니다.
필드 |
설명 |
|---|---|
|
이 행의 상태(예: |
|
모니터링되는 변수의 샘플링 기간(초) |
|
모니터링할 변수의 OID(및 인스턴스) |
|
샘플링된 변수의 실제 값 |
|
샘플 유형( |
|
초기 알람( |
|
값을 비교할 상승 임계값 |
|
값을 비교할 떨어지는 임계값 |
|
이벤트 테이블에 있는 상승 이벤트의 인덱스(행) |
|
이벤트 테이블에 있는 떨어지는 이벤트의 인덱스(행) |
및 필드는 모두 RFC 2579, SMIv2에 대한 텍스트 규칙에 정의된 대로 기본 형식입니다.entryStatuseventStatusalarmStatus
RMON 문제 해결
RFC 2819alarmTable에 나열된 표 3 확장을 제공하는 주니퍼 네트웍스 엔터프라이즈 RMON 관리 정보 베이스(MIBjnxRmon)의 내용을 검사하여 라우터에서 실행되는 RMON 에이전트 rmopd의 문제를 해결합니다.
필드 |
설명 |
|---|---|
|
변수에 대한 내부 |
|
마지막 실패가 발생한 경우의 |
|
요청이 실패한 이유 |
|
변수가 실패 상태에서 벗어난 경우의 |
|
이 경보 항목의 상태 |
이 표의 확장을 모니터링하면 원격 경보가 예상대로 작동하지 않을 수 있는 이유에 대한 단서를 얻을 수 있습니다.
측정 지점, 핵심성과지표(KPI) 및 기준값 이해
이 장 항목에서는 IP 네트워크의 서비스 품질을 모니터링하기 위한 지침을 제공합니다. 서비스 프로바이더와 네트워크 관리자가 주니퍼 네트웍스 라우터가 제공하는 정보를 사용하여 네트워크 성능과 용량을 모니터링하는 방법을 설명합니다. Junos OS에서 지원하는 SNMP 및 관련 관리 정보 베이스(MIB)를 완전히 이해해야 합니다.
IP 네트워크 모니터링 프로세스에 대한 자세한 내용은 RFC 2330, IP 성능 메트릭 프레임워크를 참조하십시오.
이러한 주제에는 다음 섹션이 포함됩니다.
측정 지점
메트릭이 측정되는 측정 지점을 정의하는 것은 메트릭 자체를 정의하는 것만큼 중요합니다. 이 섹션에서는 이 장의 컨텍스트 내에서 측정 지점을 설명하고 서비스 프로바이더 네트워크에서 측정을 수행할 수 있는 위치를 식별하는 데 도움이 됩니다. 측정 지점이 어디에 있는지 정확히 이해하는 것이 중요합니다. 측정 지점은 실제 측정이 의미하는 바를 이해하는 데 매우 중요합니다.
IP 네트워크는 모두 인터넷 프로토콜을 실행하는 물리적 링크로 연결된 라우터 모음으로 구성됩니다. 네트워크를 수신(진입) 지점과 송신(종료) 지점이 있는 라우터 모음으로 볼 수 있습니다. 그림 2을(를) 참조하세요.
네트워크 중심 측정은 네트워크 자체의 수신 및 송신 지점과 가장 근접하게 매핑되는 측정 지점에서 수행됩니다. 예를 들어, 사이트 A에서 사이트 B로의 프로바이더 네트워크 전반의 지연을 측정하려면 측정 지점이 사이트 A의 프로바이더 네트워크에 대한 수신 지점이고 사이트 B의 송신 지점이어야 합니다.
라우터 중심 측정은 라우터 자체에서 직접 수행되지만 올바른 라우터 하위 구성 요소가 미리 식별되었는지 확인해야 합니다.
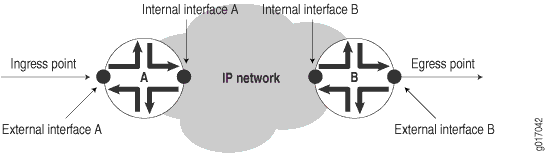
그림 2 은(는) 고객 구내의 클라이언트 네트워크를 표시하지 않지만 수신 및 송신 지점의 양쪽에 위치합니다. 이 장에서는 이러한 클라이언트 네트워크가 인식하는 네트워크 서비스를 측정하는 방법에 대해 설명하지 않지만 서비스 프로바이더 네트워크에 대해 수행된 측정값을 이러한 계산의 입력으로 사용할 수 있습니다.
기본핵심성과지표(KPI)
예를 들어 서비스 프로바이더 네트워크에서 다음과 같은 세 가지 기본 KPI(Key Performance Indicator)를 모니터링할 수 있습니다.
네트워크 레이어의 다른 측정 지점에서 한 측정 지점의 "도달 가능성"을 측정합니다(예: ICMP ping 사용). 공급자 네트워크의 기본 라우팅 및 전송 인프라는 가용성 측정을 지원하며, 장애는 사용 불가로 강조 표시됩니다.
는 프로바이더 네트워크에서 발생하는 오류의 수와 유형을 측정하며, 하드웨어 오류 또는 패킷 손실과 같은 라우터 중심 및 네트워크 중심 측정으로 구성될 수 있습니다.
의 프로바이더 네트워크는 IP 서비스를 얼마나 잘 지원할 수 있는지를 측정합니다(예: 지연 또는 활용도 측면에서).
기준선 설정
프로바이더 네트워크의 성능은 어느 정도입니까? 네트워크의 정상적인 작동 매개 변수를 식별하기 위해 처음 3개월의 모니터링 기간을 권장합니다. 이 정보를 사용하여 예외를 인식하고 비정상적인 동작을 식별할 수 있습니다. 측정된 각 메트릭의 수명 동안 기준 모니터링을 계속해야 합니다. 시간이 지남에 따라 성능 추세와 성장 패턴을 인식할 수 있어야 합니다.
이 장의 맥락에서 식별된 많은 메트릭에는 허용 가능한 작동 범위가 연결되어 있지 않습니다. 대부분의 경우 특정 네트워크에서 실제 변수에 대한 기준선을 결정하기 전까지는 허용 가능한 작동 범위를 식별할 수 없습니다.
네트워크 가용성 정의 및 측정
이 주제는 다음 섹션을 포함합니다.
네트워크 가용성 정의
서비스 프로바이더의 IP 네트워크 가용성은 에 표시된 그림 3대로 지역 POP(Points of Presence) 간의 도달 가능성으로 간주할 수 있습니다.
위의 예에서 모든 POP가 다른 모든 POP에 대한 가용성을 측정하는 측정 지점의 풀 메시를 사용하는 경우 서비스 제공업체 네트워크의 총 가용성을 계산할 수 있습니다. 이 KPI는 네트워크의 서비스 수준을 모니터링하는 데에도 사용할 수 있으며, 서비스 프로바이더와 고객이 SLA(서비스 수준 계약) 조건 내에서 운영되고 있는지 확인하는 데 사용할 수 있습니다.
POP가 여러 라우터로 구성될 수 있는 경우, 에 표시된 그림 4대로 각 라우터에 대해 측정을 수행합니다.
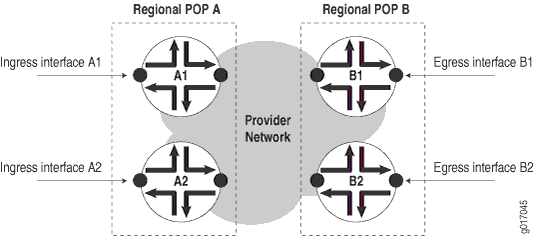
측정에는 다음이 포함됩니다.
경로 가용성 - 수신 인터페이스 A1에서 볼 수 있는 송신 인터페이스 B1의 가용성.
라우터 가용성 - 라우터에서 종료되는 측정된 모든 경로의 경로 가용성 비율입니다.
POP availability(POP 가용성) - 두 지역 POP(A와 B) 간의 라우터 가용성 비율입니다.
네트워크 가용성 - 서비스 제공업체의 네트워크에 있는 모든 지역 POP에 대한 POP 가용성의 백분율입니다.
에서 그림 4POP A에서 POP B로의 POP 가용성을 측정하려면 다음 네 가지 경로를 측정해야 합니다.
Path A1 => B1 Path A1 => B2 Path A2 => B1 Path A2 => B2
POP B에서 POP A로의 가용성을 측정하려면 추가로 4번의 측정이 필요합니다.
가용성 측정의 풀 메시는 상당한 관리 트래픽을 생성할 수 있습니다. 위의 샘플 다이어그램에서:
각 POP에는 총 18개의 PE 라우터와 36개의 STM1 인터페이스를 위해 각각 2개의 STM1 인터페이스가 있는 2개의 공동 배치된 PE(Provider Edge) 라우터가 있습니다.
6개의 코어 프로바이더(P) 라우터가 있으며, 각각 2xSTM4 및 3xSTM1 인터페이스가 있는 4개, 각각 3xSTM4 및 3xSTM1 인터페이스가 있는 2개가 있습니다.
이렇게 하면 총 68개의 인터페이스가 됩니다. 모든 인터페이스 간의 풀 메시 경로는 다음과 같습니다.
[n x (n-l)] / 2 제공68 [ x (68-1)] / 2=2278 경로
서비스 프로바이더의 네트워크에서 관리 트래픽을 줄이려면 인터페이스 가용성 테스트의 풀 메시를 생성하는 대신(예: 각 인터페이스에서 다른 모든 인터페이스로) 각 라우터의 루프백 주소에서 측정할 수 있습니다. 이렇게 하면 각 라우터에 대해 필요한 가용성 측정 수가 총 1개로 줄어듭니다.
n[ x (n-1)] / 2 제공24 [ x (24-1)] / 2=276 측정
이는 각 라우터에서 다른 모든 라우터로의 가용성을 측정합니다.
SLA 및 필요한 대역폭 모니터링
서비스 프로바이더와 고객 간의 일반적인 SLA에는 다음과 같은 내용이 포함될 수 있습니다.
A Point of Presence is the connection of two back-to-back provider edge routers to separate core provider routers using different links for resilience. The system is considered to be unavailable when either an entire POP becomes unavailable or for the duration of a Priority 1 fault.
프로바이더 네트워크의 SLA 가용성 수치가 99.999%라면 연간 약 5분의 다운타임이 예상됩니다. 따라서 이를 사전에 측정하려면 5분마다 1개 미만의 세분성으로 가용성을 측정해야 합니다. ICMP 핑 요청당 64바이트의 표준 크기로, 분당 한 번의 ping 테스트는 ping 응답을 포함하여 대상당 시간당 7680바이트의 트래픽을 생성합니다. 276개 대상에 대한 ping 테스트의 풀 메시는 시간당 2,119,680바이트를 생성하며, 이는 다음을 나타냅니다.
155.52Mbps의 OC3/STM1 링크에서 1.362%의 사용률
622.08Mbps의 OC12/STM4 링크에서 0.340%의 사용률
ICMP 핑 요청당 크기가 1500바이트인 경우 분당 한 번의 ping 테스트는 ping 응답을 포함하여 대상당 시간당 180,000바이트를 생성합니다. 276개 대상에 대한 ping 테스트의 풀 메시는 시간당 49,680,000바이트를 생성하며, 이는 다음을 나타냅니다.
OC3/STM1 링크에서 31.94%의 사용률
OC12/STM4 링크에서 7.986%의 사용률
각 라우터는 테스트된 모든 대상에 대한 결과를 기록할 수 있습니다. 각 대상에 대해 분당 한 번의 테스트를 통해 각 라우터에서 하루에 총 1 x 60 x 24 x 276 = 397,440개의 테스트를 수행하고 기록합니다. 모든 ping 결과는 (RFC 2925 참조)에 pingProbeHistoryTable 저장되며 사후 처리를 위해 SNMP 성능 보고 애플리케이션(예: InfoVista, Inc. 또는 Concord Communications, Inc.의 서비스 성능 관리 소프트웨어)에서 검색할 수 있습니다. 이 테이블의 최대 크기는 4,294,967,295행으로 충분합니다.
가용성 측정
가용성을 측정하는 데 사용할 수 있는 두 가지 방법이 있습니다.
사전 예방적 - 운영 지원 시스템에 의해 가능한 한 자주 가용성이 자동으로 측정됩니다.
사후 대응 - 사용자 또는 장애 모니터링 시스템에서 장애를 처음 보고할 때 지원 센터에서 가용성을 기록합니다.
이 섹션에서는 사전 모니터링 솔루션으로서의 실시간 성능 모니터링에 대해 설명합니다.
실시간 성능 모니터링
주니퍼 네트웍스는 실시간 네트워크 성능을 모니터링하는 실시간 성능 모니터링(RPM) 서비스를 제공합니다. J-Web 빠른 구성 기능을 사용하여 실시간 성능 모니터링 테스트에 사용되는 실시간 성능 모니터링 매개 변수를 구성합니다. (J-Web Quick Configuration은 주니퍼 네트웍스 라우터에서 실행되는 브라우저 기반 GUI입니다. 자세한 내용은 J-Web Interface 사용자 가이드를 참조하십시오.)
실시간 성능 모니터링 구성
실시간 성능 모니터링 테스트를 위해 구성할 수 있는 가장 일반적인 옵션 중 일부는 에 표 4나와 있습니다.
필드 |
설명 |
|---|---|
| 요청 정보 | |
|
테스트의 일부로 보낼 프로브 유형입니다. 프로브 유형은 다음과 같습니다.
|
|
각 프로브 전송 간의 대기 시간(초). 범위는 1초에서 255초 사이입니다. |
|
테스트 간의 대기 시간(초)입니다. 범위는 0초에서 86400초 사이입니다. |
|
각 테스트에 대해 전송된 총 프로브 수입니다. 프로브 범위는 1개에서 15개입니다. |
|
프로브를 보낼 TCP 또는 UDP 포트입니다. 번호 7(표준 TCP 또는 UDP 포트 번호)을 사용하거나 49152에서 65535 사이의 포트 번호를 선택합니다. |
|
DSCP(Differentiated Services Code Point) 비트. 이 값은 유효한 6비트 패턴이어야 합니다. 기본값은 000000입니다. |
|
ICMP 프로브 데이터 부분의 크기(바이트)입니다. 범위는 0바이트에서 65507바이트입니다. |
|
ICMP 프로브의 데이터 부분의 내용. 내용은 16진수 값이어야 합니다. 범위는 1에서 800h입니다. |
| 최대 프로브 임계값 | |
|
프로브 오류를 트리거하고 시스템 로그 메시지를 생성하기 위해 연속적으로 손실되어야 하는 총 프로브 수입니다. 프로브 범위는 0에서 15까지입니다. |
|
프로브 오류를 트리거하고 시스템 로그 메시지를 생성하기 위해 손실되어야 하는 총 프로브 수입니다. 프로브 범위는 0에서 15까지입니다. |
|
서비스 라우터에서 원격 서버까지의 총 왕복 시간(마이크로초)으로, 초과할 경우 프로브 실패를 트리거하고 시스템 로그 메시지를 생성합니다. 범위는 0에서 60,000,000 마이크로초입니다. |
|
테스트의 총 지터 (마이크로초)로, 초과할 경우 프로브 오류를 트리거하고 시스템 로그 메시지를 생성합니다. 범위는 0에서 60,000,000 마이크로초입니다. |
|
테스트에 허용되는 최대 표준 편차(마이크로초)로, 이 편차를 초과하면 프로브 오류가 트리거되고 시스템 로그 메시지가 생성됩니다. 범위는 0에서 60,000,000 마이크로초입니다. |
|
라우터에서 원격 서버까지의 총 단방향 시간(마이크로초)으로, 초과할 경우 프로브 오류를 트리거하고 시스템 로그 메시지를 생성합니다. 범위는 0에서 60,000,000 마이크로초입니다. |
|
원격 서버에서 라우터까지의 총 단방향 시간(마이크로초)으로, 초과할 경우 프로브 오류를 트리거하고 시스템 로그 메시지를 생성합니다. 범위는 0에서 60,000,000 마이크로초입니다. |
|
테스트에 대한 총 아웃바운드 시간 지터(마이크로초)로, 초과할 경우 프로브 오류를 트리거하고 시스템 로그 메시지를 생성합니다. 범위는 0에서 60,000,000 마이크로초입니다. |
|
테스트에 대한 총 인바운드 시간 지터(마이크로초)로, 초과할 경우 프로브 오류를 트리거하고 시스템 로그 메시지를 생성합니다. 범위는 0에서 60,000,000 마이크로초입니다. |
|
테스트에 대해 허용되는 아웃바운드 시간(마이크로초)의 최대 표준 편차로, 초과할 경우 프로브 오류를 트리거하고 시스템 로그 메시지를 생성합니다. 범위는 0에서 60,000,000 마이크로초입니다. |
|
테스트에 대해 허용되는 인바운드 시간(마이크로초)의 최대 표준 편차이며, 이 편차를 초과하면 프로브 오류가 트리거되고 시스템 로그 메시지가 생성됩니다. 범위는 0에서 60,000,000 마이크로초입니다. |
실시간 성능 모니터링 정보 표시
라우터에 구성된 각 실시간 성능 모니터링 테스트의 모니터링 정보에는 왕복 시간, 지터 및 표준 편차가 포함됩니다. 이 정보를 보려면 J-Web 인터페이스에서 을(를) 선택하거나 Monitor > RPM 명령줄 인터페이스(CLI) 명령을 입력합니다 show services rpm .
가장 최근의 실시간 성능 모니터링 프로브의 결과를 표시하려면 CLI 명령을 입력합니다 show services rpm probe-results .
user@host> show services rpm probe-results
Owner: p1, Test: t1
Target address: 10.8.4.1, Source address: 10.8.4.2, Probe type: icmp-ping
Destination interface name: lt-0/0/0.0
Test size: 10 probes
Probe results:
Response received, Sun Jul 10 19:07:34 2005
Rtt: 50302 usec
Results over current test:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
Results over all tests:
Probes sent: 2, Probes received: 1, Loss percentage: 50
Measurement: Round trip time
Minimum: 50302 usec, Maximum: 50302 usec, Average: 50302 usec,
Jitter: 0 usec, Stddev: 0 usec
상태 측정
SMARTS InCharge, Micromuse Netcool Omnibus 또는 Concord Live Exceptions와 같은 결함 관리 소프트웨어를 사용하여 상태 메트릭을 사후 대응적으로 모니터링할 수 있습니다. 에 표 5표시된 상태 지표를 모니터링하는 것이 좋습니다.
메트릭 |
설명 |
매개 변수 |
|
|---|---|---|---|
이름 |
가치 |
||
의 오류 |
오류가 포함되어 전달되지 않는 인바운드 패킷 수 |
관리 정보 베이스(MIB) 이름 | IF-관리 정보 베이스(RFC 2233) |
| 변수 이름 | ifInErrors |
||
| 가변 OID | .1.3.6.1.31.2.2.1.14 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 논리적 인터페이스 |
||
오류 아웃 |
오류를 포함하여 전송을 방해하는 아웃바운드 패킷 수 |
관리 정보 베이스(MIB) 이름 | IF-관리 정보 베이스(RFC 2233) |
| 변수 이름 | ifOut오류 |
||
| 가변 OID | .1.3.6.1.31.2.2.1.20 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 논리적 인터페이스 |
||
폐기 |
오류가 감지되지 않더라도 폐기된 인바운드 패킷 수 |
관리 정보 베이스(MIB) 이름 | IF-관리 정보 베이스(RFC 2233) |
| 변수 이름 | ifInDiscards |
||
| 가변 OID | .1.3.6.1.31.2.2.1.13 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 논리적 인터페이스 |
||
알 수 없는 프로토콜 |
알 수 없는 프로토콜이기 때문에 폐기된 인바운드 패킷 수 |
관리 정보 베이스(MIB) 이름 | IF-관리 정보 베이스(RFC 2233) |
| 변수 이름 | ifInUnknownProtos |
||
| 가변 OID | .1.3.6.1.31.2.2.1.15 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 논리적 인터페이스 |
||
인터페이스 작동 상태 |
인터페이스의 작동 상태 |
관리 정보 베이스(MIB) 이름 | IF-관리 정보 베이스(RFC 2233) |
| 변수 이름 | ifOperStatus |
||
| 가변 OID | .1.3.6.1.31.2.2.1.8 |
||
| 빈도(분) | 15 |
||
| 허용 범위 | 1(위쪽) |
||
| 관리되는 개체 | 논리적 인터페이스 |
||
LSP(Label Switched Path) 상태 |
MPLS 레이블 스위칭 경로의 작동 상태 |
관리 정보 베이스(MIB) 이름 | MPLS-관리 정보 베이스(MIB) |
| 변수 이름 | mplsLsp상태 |
||
| 가변 OID | mplsLspEntry.2 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 2(위로) |
||
| 관리되는 개체 | 네트워크의 모든 레이블 전환 경로 |
||
구성 요소 작동 상태 |
라우터 하드웨어 구성 요소의 작동 상태 |
관리 정보 베이스(MIB) 이름 | 주니퍼-MIB |
| 변수 이름 | jnxOperatingState |
||
| 가변 OID | .1.3.6.1.4.1.2636.1.13.1.6 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 2(실행 중) 또는 3(준비) |
||
| 관리되는 개체 | 각 주니퍼 네트웍스 라우터의 모든 구성 요소 |
||
구성 요소 작동 온도 |
하드웨어 구성 요소의 작동 온도(섭씨) |
관리 정보 베이스(MIB) 이름 | 주니퍼-MIB |
| 변수 이름 | jnxOperatingTemp |
||
| 가변 OID | .1.3.6.1.4.1.2636.1.13.1.7 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 섀시의 모든 구성 요소 |
||
시스템 가동 시간 |
시스템이 작동한 시간(밀리초)입니다. |
관리 정보 베이스(MIB) 이름 | 관리 정보 베이스(MIB)-2(RFC 1213) |
| 변수 이름 | 시스템 가동 시간 |
||
| 가변 OID | .1.3.6.1.1.3 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 증가만(감소는 다시 시작을 나타냄) |
||
| 관리되는 개체 | 모든 라우터 |
||
IP 경로 오류 없음 |
대상에 대한 IP 경로가 없어 전달할 수 없는 패킷 수입니다. |
관리 정보 베이스(MIB) 이름 | 관리 정보 베이스(MIB)-2(RFC 1213) |
| 변수 이름 | ipOutNo경로 |
||
| 가변 OID | ip.12 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 각 라우터 |
||
잘못된 SNMP 커뮤니티 이름 |
수신된 잘못된 SNMP 커뮤니티 이름 수 |
관리 정보 베이스(MIB) 이름 | 관리 정보 베이스(MIB)-2(RFC 1213) |
| 변수 이름 | snmpInBadCommunity이름 |
||
| 가변 OID | snmp.4 |
||
| 빈도(분) | 24개 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 각 라우터 |
||
SNMP 커뮤니티 위반 |
잘못된 작업을 시도하는 데 사용된 유효한 SNMP 커뮤니티 수(예: SNMP Set 요청 수행 시도) |
관리 정보 베이스(MIB) 이름 | 관리 정보 베이스(MIB)-2(RFC 1213) |
| 변수 이름 | snmpInBadCommunity용도 |
||
| 가변 OID | snmp.5 |
||
| 빈도(분) | 24개 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 각 라우터 |
||
이중화 전환 |
이 엔터티에서 보고한 총 중복 전환 횟수 |
관리 정보 베이스(MIB) 이름 | 주니퍼-MIB |
| 변수 이름 | jnxRedundancySwitchoverCount |
||
| 가변 OID | jnx이중화엔트리.8 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 중복 라우팅 엔진을 장착한 모든 주니퍼 네트웍스 라우터 |
||
FRU 상태 |
각 현장 교체 장치(FRU)의 작동 상태 |
관리 정보 베이스(MIB) 이름 | 주니퍼-MIB |
| 변수 이름 | jnxFruState |
||
| 가변 OID | jnxFru엔트리.8 |
||
| 빈도(분) | 15 |
||
| 허용 범위 | 준비/온라인 상태의 경우 2에서 6까지. FRU 실패 시 jnxFruOfflineReason을 참조하십시오. |
||
| 관리되는 개체 | 모든 주니퍼 네트웍스 라우터의 모든 FRU |
||
테일 드롭 패킷 비율 |
출력 대기열당, 포워딩 클래스당, 인터페이스당 테일 드롭 패킷 비율. |
관리 정보 베이스(MIB) 이름 | 주니퍼-COS-MIB |
| 변수 이름 | jnxCosIfqTailDropPktRate |
||
| 가변 OID | jnxCosIfqStatsEntry.12 |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | CoS가 활성화된 경우 프로바이더 네트워크의 인터페이스당 각 포워딩 클래스에 대해. |
||
인터페이스 활용: 수신된 옥텟 |
프레이밍 문자를 포함하여 인터페이스에서 수신된 총 옥텟 수. |
관리 정보 베이스(MIB) 이름 | IF-관리 정보 베이스(MIB) |
| 변수 이름 | ifIn옥텟 |
||
| 가변 OID | .1.3.6.1.2.1.2.2.1.10.x |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 네트워크의 모든 운영 인터페이스 |
||
인터페이스 활용: 전송된 옥텟 |
프레이밍 문자를 포함하여 인터페이스에서 전송된 총 옥텟 수입니다. |
관리 정보 베이스(MIB) 이름 | IF-관리 정보 베이스(MIB) |
| 변수 이름 | ifOut옥텟 |
||
| 가변 OID | .1.3.6.1.2.1.2.2.1.16.x |
||
| 빈도(분) | 60 |
||
| 허용 범위 | 기준선 설정 |
||
| 관리되는 개체 | 네트워크의 모든 운영 인터페이스 |
||
바이트 수는 인터페이스 유형, 사용된 캡슐화 및 지원되는 PIC에 따라 다릅니다. 예를 들어, 4xFE, GE 또는 GE 1Q PIC에서 vlan-ccc 캡슐화를 사용하면 바이트 수에 프레이밍 및 제어 워드 오버헤드가 포함됩니다. (표 6을(를) 참조하십시오.)
PIC 유형 |
캡슐화 |
input(단위 레벨) |
출력(단위 수준) |
SNMP |
|---|---|---|---|---|
4xFE |
VLAN-CCC |
프레임(프레임 검사 시퀀스[FCS]) 없음 |
프레임(FCS 및 제어어 포함) |
ifInOctets, ifOutOctets |
GE |
VLAN-CCC |
프레임(FCS 없음) |
프레임(FCS 및 제어어 포함) |
ifInOctets, ifOutOctets |
GE IQ |
VLAN-CCC |
프레임(FCS 없음) |
프레임(FCS 및 제어어 포함) |
ifInOctets, ifOutOctets |
SNMP 트랩은 상태 관리에 사용할 수 있는 좋은 메커니즘이기도 합니다. 자세한 내용은 "Junos OS에서 지원하는 SNMP 트랩" 및 "Junos OS에서 지원하는 엔터프라이즈별 SNMP 트랩"을 참조하십시오.
성능 측정
서비스 프로바이더 네트워크의 성능은 일반적으로 서비스를 얼마나 잘 지원할 수 있는지로 정의되며 지연 및 사용률과 같은 지표로 측정됩니다. InfoVista Service Performance Management 또는 Concord Network Health와 같은 응용 프로그램을 사용하여 다음 성능 메트릭을 모니터링하는 것이 좋습니다( 표 7참조).
| 메트릭: | 평균 지연 |
설명 |
두 측정 지점 사이의 평균 왕복 시간(밀리초). |
관리 정보 베이스(MIB) 이름 |
DISMAN-PING-MIB(RFC 2925) |
변수 이름 |
|
가변 OID |
pingResultsEntry.6 |
빈도(분) |
15(또는 핑 테스트 빈도에 따라 다름) |
허용 범위 |
기준선 설정 |
관리되는 개체 |
네트워크에서 측정된 각 경로 |
| 메트릭: | 인터페이스 활용 |
설명 |
논리적 연결의 사용률입니다. |
관리 정보 베이스(MIB) 이름 |
IF-관리 정보 베이스(MIB) |
변수 이름 |
|
가변 OID |
ifTable 항목 |
빈도(분) |
60 |
허용 범위 |
기준선 설정 |
관리되는 개체 |
네트워크의 모든 운영 인터페이스 |
| 메트릭: | 디스크 사용률 |
설명 |
주니퍼 네트웍스 라우터 내 디스크 공간 활용 |
관리 정보 베이스(MIB) 이름 |
호스트 리소스 관리 정보 베이스(RFC 2790) |
변수 이름 |
hrStorageSize – hrStorageUsed |
가변 OID |
hrStorageEntry.5 – hrStorageEntry.6 |
빈도(분) |
1440 |
허용 범위 |
기준선 설정 |
관리되는 개체 |
모든 라우팅 엔진 하드 디스크 |
| 메트릭: | 메모리 사용률 |
설명 |
라우팅 엔진 및 FPC의 메모리 활용. |
관리 정보 베이스(MIB) 이름 |
JUNIPER-MIB(주니퍼 네트웍스 엔터프라이즈 섀시 MIB) |
변수 이름 |
jnxOperatingHeap |
가변 OID |
각 구성 요소에 대한 표 |
빈도(분) |
60 |
허용 범위 |
기준선 설정 |
관리되는 개체 |
모든 주니퍼 네트웍스 라우터 |
| 메트릭: | CPU 부하 |
설명 |
CPU의 지난 1분 동안의 평균 사용률입니다. |
관리 정보 베이스(MIB) 이름 |
JUNIPER-MIB(주니퍼 네트웍스 엔터프라이즈 섀시 MIB) |
변수 이름 |
jnxOperatingCPU |
가변 OID |
각 구성 요소에 대한 표 |
빈도(분) |
60 |
허용 범위 |
기준선 설정 |
관리되는 개체 |
모든 주니퍼 네트웍스 라우터 |
| 메트릭: | LSP 사용률 |
설명 |
MPLS 레이블 스위칭 경로의 활용. |
관리 정보 베이스(MIB) 이름 |
MPLS-관리 정보 베이스(MIB) |
변수 이름 |
mplsPathBandwidth / (mplsLspOctets * 8) |
가변 OID |
mplsLspEntry.21 및 mplsLspEntry.3 |
빈도(분) |
60 |
허용 범위 |
기준선 설정 |
관리되는 개체 |
네트워크의 모든 레이블 전환 경로 |
| 메트릭: | 출력 큐 크기 |
설명 |
인터페이스당 포워딩 클래스당 각 출력 대기열의 크기(패킷 단위). |
관리 정보 베이스(MIB) 이름 |
주니퍼-COS-MIB |
변수 이름 |
jnxCosIfqQedPkts |
가변 OID |
jnxCosIfqStatsEntry.3 |
빈도(분) |
60 |
허용 범위 |
기준선 설정 |
관리되는 개체 |
네트워크의 인터페이스당 각 포워딩 클래스에 대해 CoS가 활성화되면. |
이 섹션은 다음 주제를 포함합니다.
서비스 등급 측정
CoS(class-of-service) 메커니즘을 사용하여 혼잡이 최고조에 달하는 시간 동안 네트워크 내에서 특정 등급의 패킷이 처리되는 방식을 규제할 수 있습니다. 일반적으로 CoS 메커니즘을 구현할 때 다음 단계를 수행해야 합니다.
이 클래스에 적용되는 패킷 유형을 식별합니다. 예를 들어, 특정 수신 에지 인터페이스의 모든 고객 트래픽을 하나의 클래스에 포함하거나 VoIP(Voice over IP)와 같은 특정 프로토콜의 모든 패킷을 포함합니다.
각 클래스에 필요한 결정적 동작을 식별합니다. 예를 들어 VoIP가 중요한 경우 네트워크 정체 시간 동안 VoIP 트래픽에 가장 높은 우선 순위를 부여합니다. 반대로, 혼잡 기간 동안 웹 트래픽의 중요성을 다운그레이드할 수 있습니다. 이는 고객에게 큰 영향을 미치지 않을 수 있기 때문입니다.
이 정보를 통해 네트워크 수신 시 트래픽 클래스를 모니터링, 표시 및 감시하는 메커니즘을 구성할 수 있습니다. 표시된 트래픽은 송신 인터페이스에서 보다 결정적인 방식으로 처리될 수 있으며, 일반적으로 네트워크 혼잡 시간 동안 각 클래스에 대해 서로 다른 대기열 메커니즘을 적용합니다. 네트워크에서 정보를 수집하여 혼잡 시간 동안 네트워크가 어떻게 작동하는지 보여주는 보고서를 고객에게 제공할 수 있습니다. (그림 5을(를) 참조하십시오.)
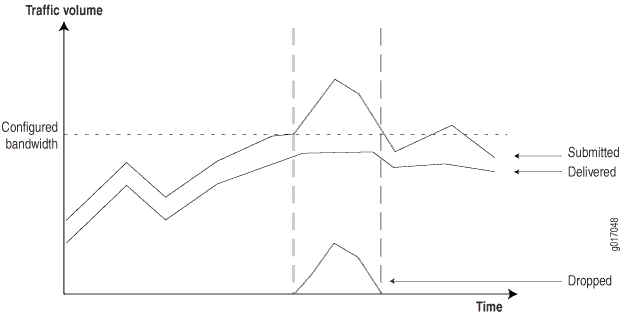
이러한 보고서를 생성하려면 라우터가 다음 정보를 제공해야 합니다.
Submitted traffic(제출된 트래픽) - 클래스당 수신된 트래픽의 양입니다.
Delivered traffic(전달된 트래픽) - 클래스당 전송된 트래픽의 양입니다.
손실된 트래픽 - CoS 제한으로 인해 손실된 트래픽의 양입니다.
다음 섹션에서는 주니퍼 네트웍스 라우터에서 이 정보를 제공하는 방법에 대해 설명합니다.
클래스별 인바운드 방화벽 필터 카운터
방화벽 필터 카운터는 인터페이스별로 클래스별로 인바운드 트래픽을 일치시키고 계산하는 데 사용할 수 있는 매우 유연한 메커니즘입니다. 몇 가지 예를 들면 다음과 같습니다.
firewall {
filter f1 {
term t1 {
from {
dscp af11;
}
then {
# Assured forwarding class 1 drop profile 1 count inbound-af11;
accept;
}
}
}
}
예를 들어 은(는) 표 8 다른 클래스를 일치시키는 데 사용되는 추가 필터를 표시합니다.
DSCP 값 |
방화벽 일치 조건 |
설명 |
|---|---|---|
10 |
af11 |
보장된 포워딩 클래스 1 드롭 프로파일 1 |
12 |
af12 |
보장된 포워딩 클래스 1 드롭 프로파일 2 |
18 |
af21 |
최선형 클래스 2 드롭 프로파일 1 |
20 |
af22 |
최선형 클래스 2 낙하 프로파일 2 |
26 |
af31 |
최선형 클래스 3 낙하 프로파일 1 |
RFC 2474를 준수하는 CoS DSCP(DiffServ Code Point)가 있는 모든 패킷은 이러한 방식으로 계산될 수 있습니다. 주니퍼 네트웍스 엔터프라이즈별 방화벽 필터 관리 정보 베이스(MIB)는 에 표 9표시된 변수에 카운터 정보를 표시합니다.
표시기 이름 |
인바운드 카운터 |
|---|---|
관리 정보 베이스(MIB) |
|
테이블 |
|
색인 |
|
변수 |
|
설명 |
지정된 방화벽 필터 카운터와 관련하여 계산되는 바이트 수 |
SNMP 버전 |
SNMPv2입니다 |
이 정보는 SNMPv2를 지원하는 모든 SNMP 관리 애플리케이션에서 수집할 수 있습니다. Concord Communications, Inc. 및 InfoVista, Inc.와 같은 공급업체의 제품은 기본 주니퍼 네트웍스 장치 드라이버를 사용하여 주니퍼 네트웍스 방화벽 관리 정보 베이스(MIB)를 지원합니다.
대기열당 출력 바이트 모니터링
주니퍼 네트웍스 엔터프라이즈 ATM CoS 관리 정보 베이스(MIB)를 사용하여 인터페이스별로 가상 서킷 포워딩 클래스별로 아웃바운드 트래픽을 모니터링할 수 있습니다. (표 10을(를) 참조하십시오.)
표시기 이름 |
아웃바운드 카운터 |
|---|---|
관리 정보 베이스(MIB) |
|
변수 |
|
색인 |
|
설명 |
지정된 가상 서킷에서 전송된 지정된 포워딩 클래스에 속하는 바이트 수입니다. |
SNMP 버전 |
SNMPv2입니다 |
비 ATM 인터페이스 카운터는 주니퍼 네트웍스 엔터프라이즈별 CoS 관리 정보 베이스(MIB)에 의해 제공되며, 에 표시된 표 11정보를 제공합니다.
표시기 이름 |
아웃바운드 카운터 |
|---|---|
관리 정보 베이스(MIB) |
|
테이블 |
|
색인 |
|
변수 |
|
설명 |
포워딩 클래스당 인터페이스당 전송된 바이트 또는 패킷 수 |
SNMP 버전 |
SNMPv2입니다 |
손실된 트래픽 계산
들어오는 트래픽에서 아웃바운드 트래픽을 빼서 손실된 트래픽의 양을 계산할 수 있습니다.
Dropped = Inbound Counter – Outbound Counter
에 표 12표시된 대로 CoS 관리 정보 베이스(MIB)에서 카운터를 선택할 수도 있습니다.
표시기 이름 |
손실된 트래픽 |
|---|---|
관리 정보 베이스(MIB) |
|
테이블 |
|
색인 |
|
변수 |
|
설명 |
포워딩 클래스당 인터페이스당 tail-dropped 또는 RED-dropped 패킷 수 |
SNMP 버전 |
SNMPv2입니다 |