EN ESTA PÁGINA
Ejemplo: configuración de una implementación de clúster activa/pasiva
En este ejemplo, se muestra cómo configurar clústeres básicos de chasis activo/pasivo en un dispositivo serie SRX de gama alta.
Requisitos
En este ejemplo se utilizan los siguientes componentes de hardware y software:
Dos puertas de enlace de servicios SRX5800 Juniper Networks con configuraciones de hardware idénticas que ejecuten Junos OS versión 9.6 o posterior.
Un enrutador de borde universal MX240 3D de Juniper Networks con Junos OS versión 9.6 o posterior.
Un conmutador Ethernet EX8208 de Juniper Networks con Junos OS versión 9.6 o posterior.
Este ejemplo de configuración se ha probado con la versión de software enumerada y se supone que funciona en todas las versiones posteriores.
Antes de empezar:
Conecte físicamente las dos puertas de enlace de servicios SRX. Este ejemplo se basa en conexiones back-to-back (conexión directa) tanto para la estructura como para los puertos de control.
Visión general
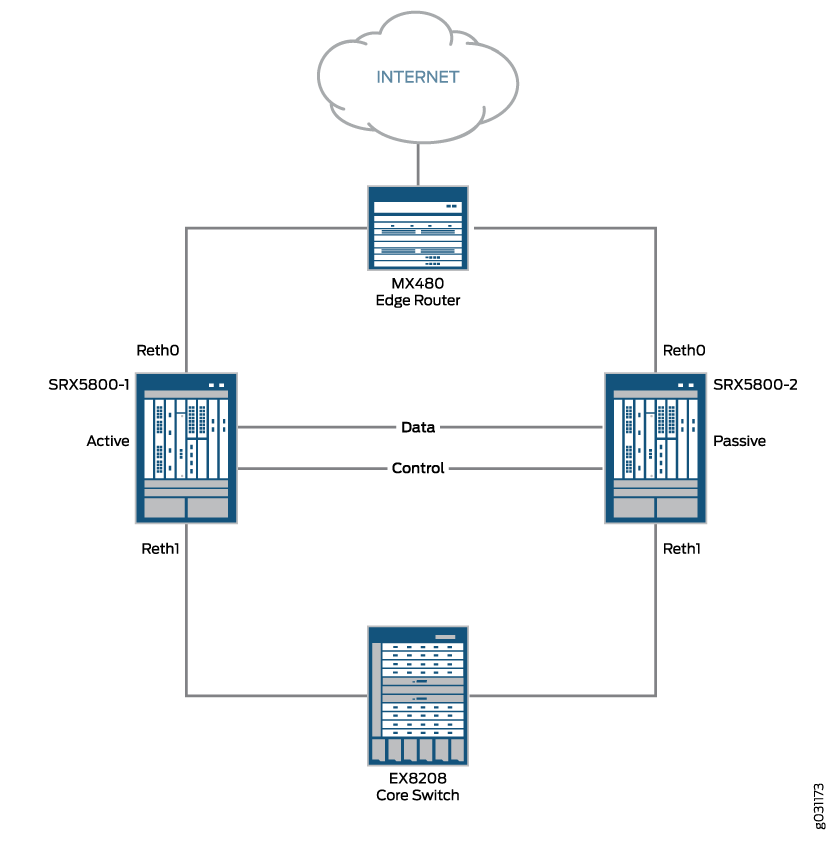
En este ejemplo, se muestra cómo configurar la agrupación en clústeres básicos de chasis activo/pasivo en un par de dispositivos de la serie SRX de gama alta. El ejemplo activo/pasivo básico es el tipo más común de clúster de chasis.
El clúster básico de chasis activo/pasivo consta de dos dispositivos:
Un dispositivo proporciona activamente servicios de enrutamiento, firewall, NAT, VPN y seguridad, además de mantener el control del clúster de chasis.
El otro dispositivo mantiene pasivamente su estado para las capacidades de conmutación por error del clúster en caso de que el dispositivo activo se vuelva inactivo.
La figura 1 muestra la topología utilizada en este ejemplo.
Configuración
En el ejemplo siguiente es necesario navegar por varios niveles en la jerarquía de configuración. Para obtener instrucciones sobre cómo hacerlo, consulte Uso del editor de CLI en modo de configuración.
Para configurar este ejemplo, realice los procedimientos siguientes:
- Configuración de los puertos de control
- Habilitación del modo de clúster
- Configuración del modo de clúster
- Configuración de zonas, enrutadores virtuales y rutas
- Configuración del EX8208
- Configuración del MX240
- Configuración de opciones varias
Configuración de los puertos de control
Procedimiento paso a paso
Seleccione FPC 1/13, porque el punto central (CP) siempre está en la SPC/SPU más baja del clúster (para este ejemplo, es la ranura 0). Para obtener la máxima confiabilidad, coloque los puertos de control en una SPC independiente del punto central (para este ejemplo, utilice la SPC en la ranura 1). Debe introducir los comandos del modo operativo en ambos dispositivos.
La configuración del puerto de control es necesaria para las puertas de enlace de servicios SRX5600 y SRX5800. No se necesita ninguna configuración de puerto de control para dispositivos SRX1400, SRX3400 o SRX3600.
Para configurar el puerto de control para cada dispositivo y confirmar la configuración:
Configure el puerto de control para SRX5800-1 (nodo 0) y confirme la configuración.
user@SRX5800-1# set chassis cluster control-ports fpc 1 port 0 user@SRX5800-1# set chassis cluster control-ports fpc 13 port 0 user@SRX5800-1# commit
Configure el puerto de control para SRX5800-2 (nodo 1) y confirme la configuración.
user@SRX5800-2# set chassis cluster control-ports fpc 1 port 0 user@SRX5800-2# set chassis cluster control-ports fpc 13 port 0 user@SRX5800-2# commit
Habilitación del modo de clúster
Procedimiento paso a paso
Antes de formar el clúster, debe configurar los puertos de control para cada dispositivo, así como asignar un ID de clúster y un ID de nodo a cada dispositivo.
Es necesario reiniciar para entrar en modo de clúster después de establecer el ID de clúster y el ID de nodo. Puede hacer que el sistema se inicie automáticamente incluyendo el reboot parámetro en la línea de comandos de la CLI. Debe introducir los comandos del modo operativo en ambos dispositivos. Cuando el sistema arranca, ambos nodos aparecen como un clúster.
Dado que solo hay un clúster en los segmentos, en el ejemplo se utiliza el identificador de clúster 1 con el dispositivo SRX5800-1 como nodo 0 y el dispositivo SRX5800-2 como nodo 1.
Para configurar los dos dispositivos en modo de clúster:
Active el modo de clúster en el SRX5800-1 (nodo 0).
user@SRX5800-1> set chassis cluster cluster-id 1 node 0 reboot
Active el modo de clúster en el SRX5800-2 (nodo 1).
user@SRX5800-2> set chassis cluster cluster-id 1 node 1 reboot
Práctica recomendada:Se recomienda colocar cada clúster SRX en su propio dominio de difusión (BD) con un ID de clúster único para cada clúster SRX. Esto se puede lograr con conexiones consecutivas o, si se usa un conmutador para conectar los dispositivos SRX, asignando una VLAN única a los puertos del conmutador utilizados por cada clúster.
Si dos o más clústeres SRX comparten un dominio de difusión, puede esperar que los errores de latidos del corazón aumenten en la salida de un
show chassis cluster information detailcomando. Este error es el resultado de un clúster que recibe tráfico de control destinado a un clúster diferente. El uso de conexiones consecutivas, o una VLAN por clúster, evita este problema al colocar cada clúster en su propio BD.El ID de clúster debe ser el mismo en ambos dispositivos que forman un clúster, pero el ID de nodo debe ser diferente porque un dispositivo es el nodo 0 y el otro dispositivo es el nodo 1. El intervalo para el identificador de clúster es de 0 a 255. Establecer un ID de clúster en 0 equivale a deshabilitar un clúster. Un ID de clúster mayor que 15 solo se puede establecer cuando la estructura y las interfaces de vínculo de control están conectadas de forma consecutiva o conectadas en VLAN independientes.
Ahora los dispositivos son un par. A partir de este momento, la configuración del clúster se sincroniza entre los miembros del nodo y los dos dispositivos independientes funcionan como un solo dispositivo.
Configuración del modo de clúster
Procedimiento paso a paso
En el modo de clúster, el clúster se sincroniza entre los nodos cuando se ejecuta un commit comando. Todos los comandos se aplican a ambos nodos, independientemente del dispositivo en el que esté configurado el comando.
Para configurar un clúster de chasis activo/pasivo en un par de dispositivos de la serie SRX de gama alta:
Configure los puertos de estructura (datos) del clúster que se utilizan para pasar objetos en tiempo real (RTO) en modo activo/pasivo. En este ejemplo se utiliza uno de los puertos Ethernet de 1 Gigabit. Defina dos interfaces de estructura, una en cada chasis, para conectarlas entre sí.
user@host# set interfaces fab0 fabric-options member-interfaces ge-11/3/0 user@host# set interfaces fab1 fabric-options member-interfaces ge-23/3/0
Dado que la configuración del clúster de chasis de la puerta de enlace de servicios SRX se encuentra dentro de una única configuración común, utilice el método de configuración específico del nodo de Junos OS denominado grupos para asignar algunos elementos de la configuración solo a un miembro específico.
El
set apply-groups ${node}comando utiliza la variable node para definir cómo se aplican los grupos a los nodos. Cada nodo reconoce su número y acepta la configuración en consecuencia. También debe configurar la administración fuera de banda en la interfaz fxp0 del SRX5800 utilizando direcciones IP independientes para los planos de control individuales del clúster.user@host# set groups node0 user@host# set groups node1 user@host# set groups node0 system host-name SRX5800-1 user@host# set groups node0 interfaces fxp0 unit 0 family inet address 10.3.5.1/24 user@host# set groups node0 system backup-router 10.3.5.254 destination 0.0.0.0/0 user@host# set groups node1 system host-name SRX5800-2 user@host# set groups node1 interfaces fxp0 unit 0 family inet address 10.3.5.2/24 user@host# set groups node1 system backup-router 10.3.5.254 destination 0.0.0.0/0 user@host# set apply-groups “${node}”Configure grupos de redundancia para clústeres de chasis.
Cada nodo tiene interfaces en un grupo de redundancia donde las interfaces están activas en grupos de redundancia activos (pueden existir varias interfaces activas en un grupo de redundancia). El grupo de redundancia 0 controla el plano de control y el grupo de redundancia 1+ controla el plano de datos e incluye los puertos del plano de datos. Para cualquier clúster de modo activo/pasivo, solo es necesario configurar el grupo de redundancia 0 y el grupo de redundancia 1. En este ejemplo se utilizan dos interfaces reth; Ambas interfaces RETH son miembros del grupo de redundancia 1. Además de los grupos de redundancia, también debe definir:
Recuento de interfaces Ethernet redundantes: configure cuántas interfaces Ethernet redundantes (reth) se pueden configurar para que el sistema pueda asignar los recursos adecuados para ello.
Prioridad para el plano de control y el plano de datos: defina qué dispositivo tiene prioridad (para el clúster de chasis, se prefiere prioridad alta) para el plano de control y qué dispositivo se prefiere que esté activo para el plano de datos.
Nota:En el modo activo/pasivo o activo/activo, el plano de control (grupo de redundancia 0) puede estar activo en un chasis diferente del chasis del plano de datos (grupo de redundancia 1+ y grupos). Sin embargo, para este ejemplo, recomendamos tener el plano de control y el plano de datos activos en el mismo miembro del chasis.
user@host# set chassis cluster reth-count 2 user@host# set chassis cluster redundancy-group 0 node 0 priority 129 user@host# set chassis cluster redundancy-group 0 node 1 priority 128 user@host# set chassis cluster redundancy-group 1 node 0 priority 129 user@host# set chassis cluster redundancy-group 1 node 1 priority 128
Configure las interfaces de datos en la plataforma para que, en caso de conmutación por error del plano de datos, el otro miembro del clúster de chasis pueda hacerse cargo de la conexión sin problemas.
La transición fluida a un nuevo nodo activo se produce con la conmutación por error del plano de datos. En caso de conmutación por error del plano de control, todos los demonios se reinician en el nuevo nodo. Esto promueve una transición sin problemas al nuevo nodo sin pérdida de paquetes.
Defina los siguientes elementos:
Información de pertenencia de las interfaces miembro a la interfaz reth.
user@host# set interfaces xe-6/0/0 gigether-options redundant-parent reth0 user@host# set interfaces xe-6/1/0 gigether-options redundant-parent reth1 user@host# set interfaces xe-18/0/0 gigether-options redundant-parent reth0 user@host# set interfaces xe-18/1/0 gigether-options redundant-parent reth1
A qué grupo de redundancia pertenece la interfaz reth. Para este ejemplo activo/pasivo, siempre es 1.
user@host# set interfaces reth0 redundant-ether-options redundancy-group 1 user@host# set interfaces reth1 redundant-ether-options redundancy-group 1
La información de la interfaz reth, como la dirección IP de la interfaz.
user@host# set interfaces reth0 unit 0 family inet address 1.1.1.1/24 user@host# set interfaces reth1 unit 0 family inet address 2.2.2.1/24
Configure el comportamiento del clúster de chasis en caso de que se produzca un error.
Cada interfaz está configurada con un valor de peso que se deduce del umbral del grupo de redundancia de 255 en caso de pérdida de vínculo. El umbral de conmutación por error está codificado de forma rígida en 255 y no se puede cambiar. Puede modificar los pesos de un vínculo de interfaz para determinar el impacto en la conmutación por error del chasis.
Cuando un umbral de grupo de redundancia alcanza 0, ese grupo de redundancia conmuta por error al nodo secundario.
Ingrese los siguientes comandos en el SRX5800-1:
user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-6/0/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-6/1/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-18/0/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-18/1/0 weight 255 user@SRX5800-1# set chassis cluster control-link-recovery
Este paso completa la parte de configuración del clúster de chasis del ejemplo de modo activo/pasivo para el SRX5800. El resto de este procedimiento describe cómo configurar la zona, el enrutador virtual, el enrutamiento, el EX8208 y el MX480 para completar el escenario de implementación.
Configuración de zonas, enrutadores virtuales y rutas
Procedimiento paso a paso
Configure y conecte las interfaces reth a las zonas y enrutadores virtuales adecuados. Para este ejemplo, deje las interfaces reth0 y reth1 en el enrutador virtual (predeterminado) y la tabla de enrutamiento (inet.0), que no requieren ninguna configuración adicional.
Para configurar zonas, enrutadores virtuales y rutas:
Configure las interfaces de reth para las zonas y enrutadores virtuales adecuados.
user@host# set security zones security-zone untrust interfaces reth0.0 user@host# set security zones security-zone untrust interfaces reth1.0
Configure rutas estáticas a los demás dispositivos de red.
user@host# set routing-options static route 0.0.0.0/0 next-hop 1.1.1.254 user@host# set routing-options static route 2.0.0.0/8 next-hop 2.2.2.254
Configuración del EX8208
Procedimiento paso a paso
Para el EX8208, los siguientes comandos proporcionan solo un esquema de la configuración aplicable en lo que respecta a este ejemplo de malla completa activa/pasiva para el SRX5800, especialmente las VLAN, el enrutamiento y la configuración de la interfaz.
Para configurar el EX8208:
Configure las interfaces.
user@host# set interfaces xe-1/0/0 unit 0 family ethernet-switching port-mode access vlan members SRX5800 user@host# set interfaces xe-2/0/0 unit 0 family ethernet-switching port-mode access vlan members SRX5800 user@host# set interfaces vlan unit 50 family inet address 2.2.2.254/24
Configure las VLAN.
user@host# set vlans SRX5800 vlan-id 50 user@host# set vlans SRX5800 l3-interface vlan.50
Configure una ruta estática.
user@host# set routing-options static route 0.0.0.0/0 next-hop 2.2.2..1/24
Configuración del MX240
Procedimiento paso a paso
Para el MX240, los siguientes comandos proporcionan solo un esquema de la configuración aplicable en lo que respecta a este ejemplo de modo activo/pasivo para el SRX5800; lo más notable es que debe usar una interfaz de enrutamiento y puente integrados (IRB) dentro de una instancia de conmutador virtual en el conmutador.
Para configurar el MX240:
Configure las interfaces.
user@host# set interfaces xe-1/0/0 encapsulation ethernet-bridge unit 0 family bridge user@host# set interfaces xe-2/0/0 encapsulation ethernet-bridge unit 0 family bridge user@host# set interfaces irb unit 0 family inet address 1.1.1.254/24
Configure las rutas estáticas.
user@host# set routing-options static route 2.0.0.0/8 next-hop 1.1.1.1 user@host# set routing-options static route 0.0.0.0/0 next-hop
Configure los dominios de puente.
user@host# set bridge-domains SRX5800 vlan-id X user@host# set bridge-domains SRX5800 domain-type bridge routing-interface irb.0 user@host# set bridge-domains SRX5800 domain-type bridge interface xe-1/0/0 user@host# set bridge-domains SRX5800-1 domain-type bridge interface xe-2/0/0
Configuración de opciones varias
Procedimiento paso a paso
Este ejemplo de modo activo/pasivo para el SRX5800 no describe en detalle diversas configuraciones, como la forma de configurar NAT, políticas de seguridad o VPN. Son esencialmente los mismos que serían para configuraciones independientes.
Sin embargo, si está realizando ARP de proxy en configuraciones de clúster de chasis, debe aplicar las configuraciones de ARP de proxy a las interfaces reth en lugar de a las interfaces miembro, ya que las interfaces RETH contienen las configuraciones lógicas.
También puede configurar configuraciones de interfaz lógica independientes mediante VLAN e interfaces troncalizadas en el SRX5800. Estas configuraciones son similares a las implementaciones independientes que utilizan VLAN e interfaces troncalizadas.
Verificación
Confirme que la configuración funciona correctamente.
- Verificación del estado del clúster de chasis
- Comprobación de interfaces de clúster de chasis
- Verificación de estadísticas de clúster de chasis
- Verificación de estadísticas del plano de control del clúster de chasis
- Comprobación de estadísticas de plano de datos del clúster de chasis
- Comprobación del estado del grupo de redundancia del clúster de chasis
- Solución de problemas con registros
Verificación del estado del clúster de chasis
Propósito
Compruebe el estado del clúster de chasis, el estado de conmutación por error y la información del grupo de redundancia.
Acción
Desde el modo operativo, ingrese el show chassis cluster status comando.
{primary:node0}
user@host>show chassis cluster status
Cluster ID: 1
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 1
node0 129 primary no no
node1 128 secondary no no
Redundancy group: 1 , Failover count: 1
node0 129 primary no no
node1 128 secondary no no
Significado
El resultado de ejemplo muestra el estado de los nodos primario y secundario y que no hay conmutaciones por error manuales.
Comprobación de interfaces de clúster de chasis
Propósito
Compruebe la información sobre las interfaces de clúster de chasis.
Acción
Desde el modo operativo, ingrese el show chassis cluster interfaces comando.
{primary:node0}
user@host> show chassis cluster interfaces
Control link name: fxp1
Redundant-ethernet Information:
Name Status Redundancy-group
reth0 Up 1
reth1 Up 1
Interface Monitoring:
Interface Weight Status Redundancy-group
xe-6/0/0 255 Up 1
xe-6/1/0 255 Up 1
xe-18/0/0 255 Up 1
xe-18/1/0 255 Up 1
Significado
El resultado de ejemplo muestra el estado de cada interfaz, el valor de peso y el grupo de redundancia al que pertenece esa interfaz.
Verificación de estadísticas de clúster de chasis
Propósito
Compruebe la información sobre los servicios de clúster de chasis y las estadísticas de vínculos de control (latidos enviados y recibidos), las estadísticas de vínculos de estructura (sondeos enviados y recibidos) y el número de objetos en tiempo real (RTO) enviados y recibidos para los servicios.
Acción
Desde el modo operativo, ingrese el show chassis cluster statistics comando.
{primary:node0}
user@host> show chassis cluster statistics
Control link statistics:
Control link 0:
Heartbeat packets sent: 258689
Heartbeat packets received: 258684
Heartbeat packets errors: 0
Fabric link statistics:
Child link 0
Probes sent: 258681
Probes received: 258681
Services Synchronized:
Service name RTOs sent RTOs received
Translation context 0 0
Incoming NAT 0 0
Resource manager 6 0
Session create 161 0
Session close 148 0
Session change 0 0
Gate create 0 0
Session ageout refresh requests 0 0
Session ageout refresh replies 0 0
IPSec VPN 0 0
Firewall user authentication 0 0
MGCP ALG 0 0
H323 ALG 0 0
SIP ALG 0 0
SCCP ALG 0 0
PPTP ALG 0 0
RPC ALG 0 0
RTSP ALG 0 0
RAS ALG 0 0
MAC address learning 0 0
GPRS GTP 0 0
Significado
Utilice el resultado de ejemplo para:
Compruebe que el Heartbeat packets sent se está incrementando.
Compruebe que el Heartbeat packets received es un número cercano al número de Heartbeats packets sent.
Compruebe que el Heartbeats packets errors es cero.
Esto verifica que los paquetes de latidos se transmiten y reciben sin errores.
Verificación de estadísticas del plano de control del clúster de chasis
Propósito
Verifique la información sobre las estadísticas del plano de control del clúster del chasis (latidos enviados y recibidos) y las estadísticas del vínculo de estructura (sondeos enviados y recibidos).
Acción
Desde el modo operativo, ingrese el show chassis cluster control-plane statistics comando.
{primary:node0}
user@host> show chassis cluster control-plane statistics
Control link statistics:
Control link 0:
Heartbeat packets sent: 258689
Heartbeat packets received: 258684
Heartbeat packets errors: 0
Fabric link statistics:
Child link 0
Probes sent: 258681
Probes received: 258681
Significado
Utilice el resultado de ejemplo para:
Compruebe que el Heartbeat packets sent se está incrementando.
Compruebe que el Heartbeat packets received es un número cercano al número de Heartbeats packets sent.
Compruebe que el Heartbeats packets errors es cero.
Esto verifica que los paquetes de latidos se transmiten y reciben sin errores.
Comprobación de estadísticas de plano de datos del clúster de chasis
Propósito
Compruebe la información sobre el número de objetos en tiempo real (RTO) enviados y recibidos para los servicios.
Acción
Desde el modo operativo, ingrese el show chassis cluster data-plane statistics comando.
{primary:node0}
user@host> show chassis cluster data-plane statistics
Services Synchronized:
Service name RTOs sent RTOs received
Translation context 0 0
Incoming NAT 0 0
Resource manager 6 0
Session create 161 0
Session close 148 0
Session change 0 0
Gate create 0 0
Session ageout refresh requests 0 0
Session ageout refresh replies 0 0
IPSec VPN 0 0
Firewall user authentication 0 0
MGCP ALG 0 0
H323 ALG 0 0
SIP ALG 0 0
SCCP ALG 0 0
PPTP ALG 0 0
RPC ALG 0 0
RTSP ALG 0 0
RAS ALG 0 0
MAC address learning 0 0
GPRS GTP 0 0
Significado
El resultado de ejemplo muestra el número de RTO enviados y recibidos para varios servicios.
Comprobación del estado del grupo de redundancia del clúster de chasis
Propósito
Compruebe el estado y la prioridad de ambos nodos en un clúster e información acerca de si el nodo principal ha tenido preferencia o si ha habido una conmutación por error manual.
Acción
Desde el modo operativo, ingrese el show chassis cluster status redundancy-group comando.
{primary:node0}
user@host> show chassis cluster status redundancy-group 1
Cluster ID: 1
Node Priority Status Preempt Manual failover
Redundancy-Group: 1, Failover count: 1
node0 100 primary no no
node1 50 secondary no no
Significado
El resultado de ejemplo muestra el estado de los nodos primario y secundario y que no hay conmutaciones por error manuales.
Solución de problemas con registros
Propósito
Consulte los archivos de registro del sistema para identificar cualquier problema con el clúster del chasis. Debe consultar los archivos de registro del sistema en ambos nodos.
Acción
Desde el modo operativo, ingrese estos show log comandos.
user@host> show log jsrpd user@host> show log chassisd user@host> show log messages user@host> show log dcd user@host> show traceoptions
Resultados
Desde el modo operativo, ingrese el comando para confirmar la show configuration configuración. Si el resultado no muestra la configuración deseada, repita las instrucciones user@host de este ejemplo para corregir la configuración.
version x.xx.x
groups {
node0 {
system {
host-name SRX5800-1;
backup-router 10.3.5.254 destination 0.0.0.0/16;
}
interfaces {
fxp0 {
unit 0 {
family inet {
address 10.3.5.1/24;
}
}
}
}
}
node1 {
system {
host-name SRX5800-2;
backup-router 10.3.5.254 destination 0.0.0.0/16;
}
interfaces {
fxp0 {
unit 0 {
family inet {
address 10.3.5.2/24;
}
}
}
}
}
}
apply-groups "${node}";
system {
root-authentication {
encrypted-password "$1$zTMjraKG$qU8rjxoHzC6Y/WDmYpR9r.";
}
name-server {
4.2.2.2;
}
services {
ssh {
root-login allow;
}
netconf {
ssh;
}
web-management {
http {
interface fxp0.0;
}
}
}
}
chassis {
cluster {
control-link-recovery;
reth-count 2;
control-ports {
fpc 1 port 0;
fpc 13 port 0;
}
redundancy-group 0 {
node 0 priority 129;
node 1 priority 128;
}
redundancy-group 1 {
node 0 priority 129;
node 1 priority 128;
interface-monitor {
xe-6/0/0 weight 255;
xe-6/1/0 weight 255;
xe-18/0/0 weight 255;
xe-18/1/0 weight 255;
}
}
}
}
interfaces {
xe-6/0/0 {
gigether-options {
redundant-parent reth0;
}
}
xe-6/1/0 {
gigether-options {
redundant-parent reth1;
}
}
xe-18/0/0 {
gigether-options {
redundant-parent reth0;
}
}
xe-18/1/0 {
gigether-options {
redundant-parent reth1;
}
}
fab0 {
fabric-options {
member-interfaces {
ge-11/3/0;
}
}
}
fab1 {
fabric-options {
member-interfaces {
ge-23/3/0;
}
}
}
reth0 {
redundant-ether-options {
redundancy-group 1;
}
unit 0 {
family inet {
address 1.1.1.1/24;
}
}
}
reth1 {
redundant-ether-options {
redundancy-group 1;
}
unit 0 {
family inet {
address 2.2.2.1/24;
}
}
}
}
routing-options {
static {
route 0.0.0.0/0 {
next-hop 1.1.1.254;
}
route 2.0.0.0/8 {
next-hop 2.2.2.254;
}
}
}
security {
zones {
security-zone trust {
host-inbound-traffic {
system-services {
all;
}
}
interfaces {
reth0.0;
}
}
security-zone untrust {
interfaces {
reth1.0;
}
}
}
policies {
from-zone trust to-zone untrust {
policy 1 {
match {
source-address any;
destination-address any;
application any;
}
then {
permit;
}
}
}
default-policy {
deny-all;
}
}
}
Si ha terminado de configurar el dispositivo, ingrese commit desde el modo de configuración.