ON THIS PAGE
eBPF Kernel Data Plane (Tech Preview)
SUMMARY Juniper Cloud-Native Contrail Networking (CN2) release 23.3 supports an extended Berkeley Packet Filter (eBPF) data plane for the Linux kernel. An eBPF-based data plane enables programs to be loaded into the kernel for high-performance applications.
Linux Kernel Overview
The Linux kernel memory is broadly divided into the following two areas:
-
Kernel space: The core of the OS operates in kernel space. The OS has unrestricted access to all host resources including: memory, storage, and CPU. Kernel space is strictly reserved for running a privileged OS kernel, kernel extensions, and the majority of the host's device drivers. Kernel space is protected and only runs trusted code.
-
User-space library: Non-kernel processes, such as regular applications, operate within user-space. The code running in user-space has limited access to hardware resources and typically relies on kernel space for performing privileged operations such as disk or network I/O. User-space applications request a service from the kernel through APIs, or system calls. System calls provide an interface between a process and the OS to allow user-space processes to request services of the OS.
In some cases, a developer might require more kernel performance than is allocated through the system call interface. Custom system calls, support for new hardware, and new file sytems all might require additional kernel flexibility. Cases like this require enhancements to the kernel without adding to its source code. A Linux Kernel Module (LKM) extends the base kernel without adding or altering its source code. LKMs, unlike system calls, are directly loaded into the kernel at runtime. This means that the kernel does not need to be recompiled and rebooted each time a new LKM is required. Although LKMs extend the kernel, when it comes to use cases like high performance packet processing, LKMs are still constrained by the overhead and networking limitations of the kernel itself. Additionally, LKMs often have kernel version compatibility issues that need resolution, and non-upstreamed LKMs can have trust issues.
For additional information, see Juniper CN2 Technology Previews (Tech Previews) or contact Juniper Support.
eBPF Overview
The Berkeley Packet Filter (BPF) provides a way to filter packets efficiently, avoiding useless packet copies from kernel to user-space. eBPF is a mechanism for writing code that is executed in kernel space. Developers write eBPF programs in a restricted C language. This code, known as bytecode, is compiled and produced by compiler toolchains like Clang/LLVM.
One security advantage of BPF is the requirement that BPF programs must be verified before becoming active in the kernel. BPF programs run in a virtual machine (VM) in the kernel. The verification process ensures that BPF programs run to completion without looping, within the VM. The verification process also includes checks for valid register state, the size of the program, and out-of-bound-jumps. After the verification process, the program becomes active in the kernel.
eBPF Kernel Data Plane
The eBPF kernel data plane enables you to extend and customize the kernel's behavior more safely and efficiently than is possible with traditional LKMs. Like LKMs, the kernel is not reloaded and the kernel's code is not altered. eBPF in the kernel data plane means that user-space applications can process data as it flows through the kernel. In other words, applications that take advantage of eBPF are written and processed within the kernel, drastically reducing the networking layer overhead of typical kernel processes. Tasks like high-performance packet processing, packet filtering, tracing, and security monitoring all benefit from the additional kernel performance eBPF provides.
Understanding eBPF Programs
Events and Hooking
eBPF programs execute in an event-driven environment. Events are specific situations or conditions that are monitored, traced, or analyzed. For example, network packets arriving at an interface is an event. An eBPF program is attached to this event and can analyze ingress network packets or trace a packet's path.
Hooking refers to the process of attaching an eBPF program to specific execution points within the kernel flow. When a hook triggers, the eBPF program is executed. The eBPF program can modify event behavior or record data related to the event. For example, a system call might act as a hook. When the system call is initiated, a hook triggers, enabling the eBPF program to monitor system processes.
Other examples of hooks include:
Helper Functions
eBPF programs call helper functions, effectively making eBPF programs feature-rich. Helper functions perform the following:
- Search, update and delete key-value pairs
- Generate a pseudo-random number
- Get and set tunnel metadata
- Chain eBPF programs together (tail calls)
- Perform tasks with sockets such as binding, retrieving cookies, and redirecting packets
The kernel defines helper functions, meaning that the kernel whitelists the range of calls that eBPF programs make.
eBPF Maps
Maps are the main data structures used by eBPF programs. Maps allow the communication of data between the kernel and user space. A map is a key-value store where values are treated as binary blobs of arbitrary data. When the map is no longer needed, it is removed by closing the associated file descriptor.
Each map has the following four attributes: its type, the maximum quantity of elements it can contain, the size of its values in bytes, and the size of its keys in bytes. Various map types are available, each offering distinct behaviors and trade-offs. All maps can be accessed and manipulated from both eBPF programs and user space programs through the utilization of bpf_map_lookup_elem() and bpf_map_update_elem() functions.
Executing an eBPF Program
The kernel expects all eBPF programs to be loaded as bytecode. As a result, eBPF programs must be compiled into bytecode using toolchains. Once compiled, eBPF programs undergo verification within the kernel prior to their deployment at the designated hook point. eBPF supports modern architecture, meaning it is upgraded to be 64-bit encoded with 11 total registers. This closely maps eBPF to hardware for x86_64, ARM, and arm64 architecture, among others.
Most importantly, eBPF unlocks access to kernel-level events, avoiding the typical constraints associated with directly altering kernel code. In summary, eBPF works by:
-
Compiling eBPF programs into bytecode
-
Verifying programs execute safely in a VM loading at the hook point
-
Attaching programs to hook points within the kernel that are triggered by specified events
-
Compiling into native bytecode at runtime for greater portability
-
Calling helper functions to manipulate data when a program runs
-
Using maps (key-value pairs) to share data between the user space and kernel space and for maintaining state
Figure 1: eBPF Program Execution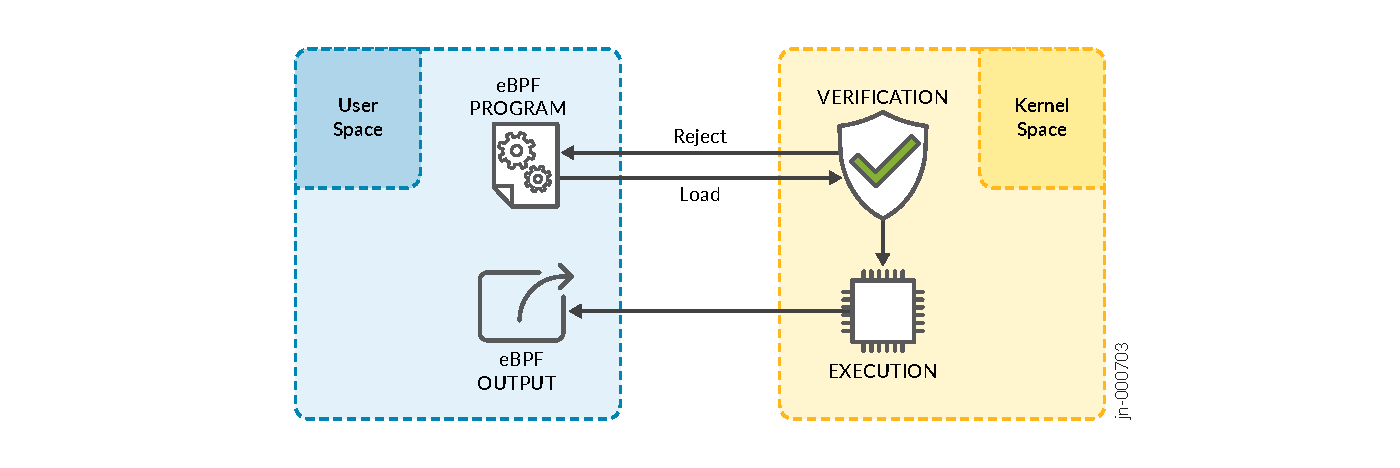
XDP Overview
eXpress Data Path (XDP) is a newer programmable layer in the kernel network stack. XDP is one of the newer hook points where eBPF bytecode is attached and executed from. XDP object files are loaded on multiple kernels and architectures without the need for recompiling required by traditional eBPF programs. Although XDP programs narrow the performance gap in comparison to kernel-bypass solutions, the programs do not bypass the kernel. The following are some key characteristics that define XDP:
-
Not intended to be faster than kernel-bypass
-
Operates directly on packet buffers
-
Decreases number of instructions executed per packet
The kernel network stack is designed for socket-delivery use cases. As a result, it always converts all the incoming packets to socket buffers (SKBs). XDP enables the processing of packets before they are converted to SKBs. XDP operates in conjunctions with the existing kernel stack, all without necessitating kernel modifications. This makes XDP an in-kernel alternative that offers greater flexibility.
XDP and Traffic Control Hooks
All eBPF bytecode loading, map creation, updating, and reading is processed through the BPF syscall. It's important to note that the XDP driver hooks are only available on the ingress. If egress packets must be processed, an alternative hook, such as TC (Traffic Control), might need to be employed. At a broader level, there are several differences between XDP BPF programs and TC BPF programs:
-
XDP hooks occur earlier, resulting in faster performance.
-
TC hooks occur later. As a result, they have access to the socket buffer (
sk_buff) structure and fields. This is a significant contributor to the performance difference between the XDP and TC hooks because thesk_buffdata structure contains metadata and information that enables the kernel's network stack to process and route packets efficiently. Accessing thesk_buffstructure and its attributes incurs a certain overhead, because the kernel stack must allocate, extract metadata, and manage the packet until it reaches the TC hook.
-
-
TC hooks enable better packet mangling.
-
XDP is better for complete packet rewrites.
-
The
sk_buffuse case contains extensive protocol-specific details, such as state information related to GSO (Generic Segmentation Offload). This makes it challenging to switch protocols solely by rewriting the packet data. As a result, further conversion is necessary, accomplished through BPF helper functions. These helper functions ensure that the internal components of thesk_buffare properly converted.In contrast, the
xdp_buffuse case doesn't encounter these issues. It operates at an early stage in packet processing, even before the kernel allocates ansk_buff. As a result, making any type of packet rewrite in this scenario is straightforward.
-
-
TC eBPF and XDP as complementary programs.
-
In instances where the use case requires both packet rewrite and intricate mangling of data, then the limitations of each program type can be overcome by operating complementary programs of both types. For example, an XDP program at the ingress point can perform a complete packet rewrite and transmit custom metadata from XDP BPF to TC BPF. The TC BPF program can then leverage the XDP metadata and
sk_bufffields to perform complex packet processing.
-
-
TC BPF does not require hardware driver changes. XDP uses native driver mode for best performance.
Figure 2: XDP and TC Hooks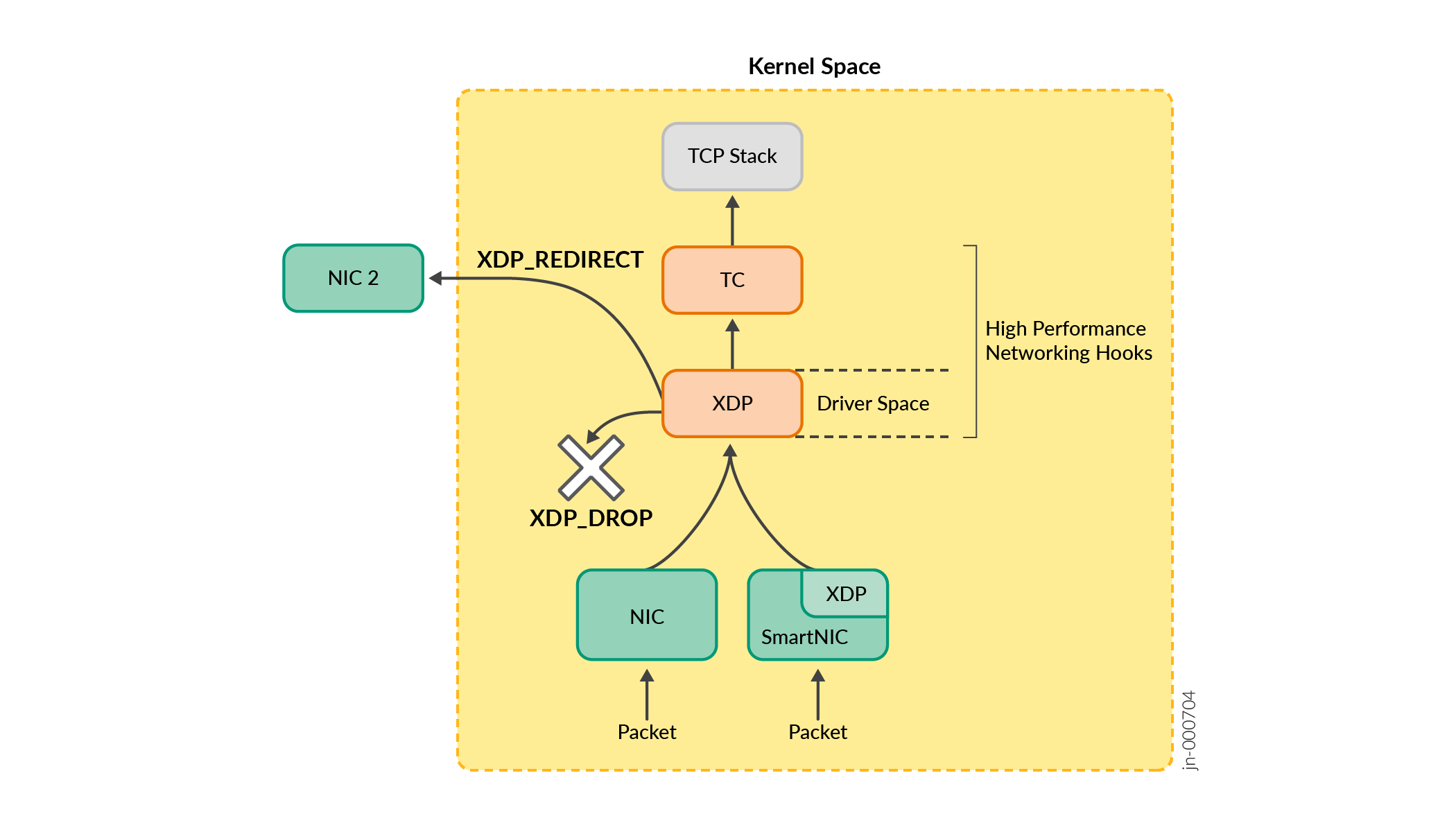
XDP Control and Data Plane
With XDP, the data plane resides within the kernel, dividing it into two components: the kernel core and the in-kernel eBPF program. The control plane resides in user space, operating in conjunction with the kernel space to perform essential tasks such as loading BPF programs into the kernel and managing program behavior through the use of maps.
XDP Action and Behavior
An eBPF program running at an XDP hook point returns the following actions based on how the program processes the packet:
- Redirects ingress packets to other interfaces or to user space.
-
Sends the received packet back out the same interface it arrived on.
-
Sends the packet to the kernel stack for processing.
-
Drops the packet.
XDP and eBPF
XDP serves as a software offload layer for the kernel's networking stack. An ideal use case is in conjunction with the Linux kernel's network stack to enhance performance. For example, in an IP routing use case, the kernel handles route table management and neighbor lookups, while XDP accelerates packet processing by efficiently accessing these routing tables with helper functions. After the lookup is complete and the next hop is identified, packet headers are modified accordingly. If no modification is needed, the packet is forwarded to the kernel as-is.
It is important to note that XDP imposes the following restrictions on the RX memory model:
- Does not currently support jumbo frames for all popular drivers, although i40e, Veth, and virtio support jumbo frames.
-
Multicast support exists in the kernel space
Utilizing an eBPF XDP driver mode-based approach offers benefits over a proprietary kernel module like the vRouter kernel module. Some of the benefits include improved Lifecycle Management (LCM), safety, and performance. When compared to a kernel module integrated into the Linux upstream tree, maintaining an alternative eBPF XDP kernel program is more efficient across kernel versions. This is because kernel dependencies are limited to a small set of eBPF helper functions.
It is important to note that in the event of a controller/library crash, the XDP or TC program still forwards traffic. The re-attachment or replacement of an XDP or TC program does not disrupt network traffic.
Kernel to User Space Communication
AF_XDP sockets are used to facilitate communication between the kernel-space program operating at the XDP hook and the user space library. AF_XDP was introduced in Linux 4.1.8. AF_XDP is a new socket type for fast raw packet delivery to user space applications. AF_XDP leverages Linux kernel drivers for high performance and scalability. Notably, it also provides features such as support for zero-copy data transfer, minimal reliance on interrupts, and optimization for networking drivers similar to what Data Plane Development Kit (DPDK) and Vector Packet Processing (VPP) provide.
The path of a packet flowing through an AF_XDP socket is as follows:
The NIC-specific driver accesses incoming packets at the NIC. The driver intercepts and processes them through the eBPF program running at the XDP hook, which is bound to the corresponding interface. The XDP program processes each packet individually, and upon completion, it generates an action, as detailed in the XDP Action and Cooperation section. By utilizing XDP_REDIRECT, the packet is directed to user space via an AF_XDP socket associated with that interface. This makes it possible to receive raw packets straight from the NIC. By bypassing kernel space, kernel overhead is avoided and the packet accesses user space libraries directly.
Supported eBPF Features
Supported features in CN2 release 23.2
-
Default pod network
-
Pod to pod connectivity
- ClusterIP service
-
Supported features in CN2 release 23.3
Enable eBPF Data Plane
You can enable the eBPF data plane feature by specifying agentModeType:
xdp in the vRouter's spec. Since not all XDP drivers currently support jumbo
frames, the CN2 deployer sets the Maximum Transmission Unit (MTU) values of the fabric,
loopback, and veth interfaces.
The following example is a vRouter resource with XDP-eBPF enabled.
apiVersion: dataplane.juniper.net/v1
kind: Vrouter
metadata:
name: contrail-vrouter-masters
namespace: contrail
spec:
agent:
default:
collectors:
- localhost:6700
xmppAuthEnable: true
sandesh:
introspectSslEnable: true
sandeshSslEnable: true
agentModeType: xdp
common:
containers:
- name: contrail-vrouter-agent
image: contrail-vrouter-agent
- name: contrail-watcher
image: contrail-init
- name: contrail-vrouter-telemetry-exporter
image: contrail-vrouter-telemetry-exporter
initContainers:
- name: contrail-init
image: contrail-init
- name: contrail-cni-init
image: contrail-cni-initNote the name: contrail-vrouter-masters field. Since this vRouter is
designated as a master node, all available master nodes are set to agentModeType:
xdp when the deployer is applied. This logic also applies to worker nodes; if you
specify "xdp" for the worker node resource in the deployer, all worker nodes are configured
for XDP-eBPF.
XDP Supported Drivers
The following table lists the CN2-validated XDP drivers with eBPF-XDP datapath.
| Driver name | Underlying platform |
|---|---|
| ENA | AWS |
| veth | Pod connectivity |
| virtio | CN2-On-CN2 |
| i40e | Bare Metal |
If your cluster uses AWS ENA underlying drivers for NIC interfaces, the deployer sets the queue config of 4 receiving (RX) and 4 transmission (TX) for physical interfaces. This change occurs because the default RX and TX queue count of ENA drivers is not supported for XDP.
eBPF Data Plane Design and CN2 Implementation
The eBPF kernel data plane consists of two core components: the in-kernel XDP program and a complementary user space library. This eBPF-powered data plane is the third data plane option for vRouter, along with the kernel module-based vRouter and DPDK. The subsequent sections explain the design and implementation specifics of the various data plane features provided by this technology.
eBPF Data Plane Components
As previously mentioned, the eBPF data plane is based in XDP. For features that require packets to originate from the default namespace, there might also be a necessity for an egress TC hook. This is due to the absence of the XDP hook on the egress path. The TC program also introduces new parsing functions, given that TC hooks operate with SKBs.
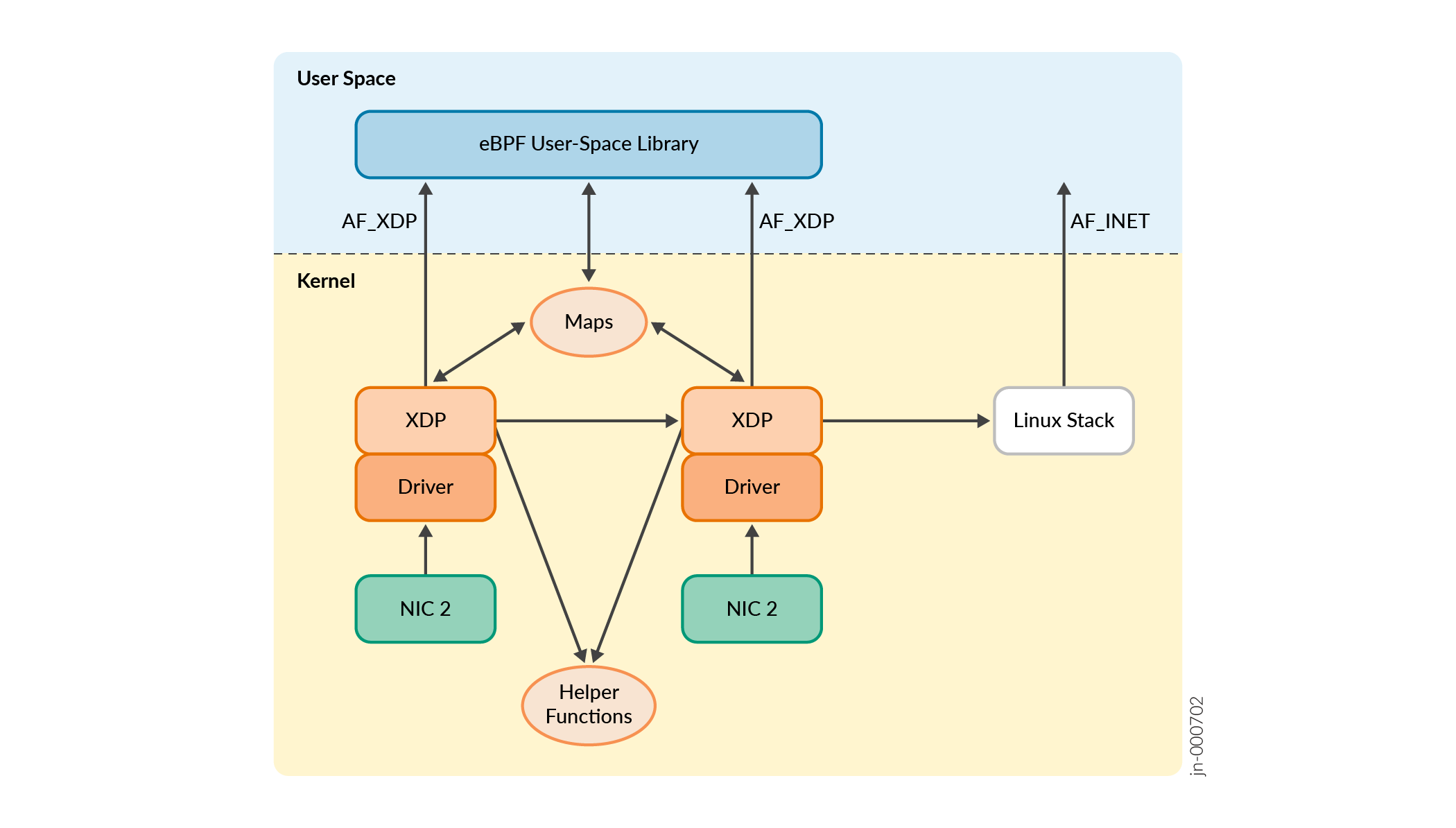
The eBPF data plane is not intended as a separate daemon; instead, it will be integrated as a library within the controller (vRouter agent in the case of CN2). This implementation is divided into two components:
-
User space library: The user space library acts as an interface between the kernel eBPF program and a controller running in user space (vRouter agent). It exposes APIs that the vRouter agent utilizes to program the data path. This component performs the following functions:
-
Loads and unloads eBPF program into the kernel
-
Binds eBPF programs to interfaces
-
Configures and reads map entries
-
Forwards, modifies, and filters packets within the user space data path
-
-
Kernel space program: These eBPF programs constitute the main data path that runs in the kernel core. This program is loaded onto the XDP-hook of interfaces and processes all incoming packets for those interfaces. TC is also used on the loopback interface's egress. As mentioned earlier, the user space eBPF library is responsible for loading the eBPF program into the kernel core. The kernel space program does the following:
-
Forwards, modifies, and filters packets in the kernel
-
Uses helper functions to interact with rest of kernel
-
Creates, updates, and reads maps (maps are data structures shared between the user space library and the kernel space program)
-
The vRouter agent interacts with the eBPF data plane via the user space library in several ways:
-
The controller (vRouter agent) calls APIs exposed by the user space eBPF library directly.
-
The public APIs exposed by the library replaces the functionality provided by the ksync/Sandesh layer used for othe datapaths
-
The agent registers callbacks with the user space library for flow misses and to receive packets of interest
-
- The library also listens on netlink socket events; the user-space library can listen on routes, and arp and address updates from the kernel
- The library also queries the kernel for other information