Service Instance Health Checks
Contrail Networking enables you to use a service instance health check to determine the liveliness of a service provided by a virtual machine (VM).
Health Check Object
- Health Check Overview
- Health Check Object Configuration
- Creating a Health Check with the Contrail Web UI
- Using the Health Check
- Health Check Process
Health Check Overview
The service instance health check is used to determine the liveliness of a service provided by a VM, checking whether the service is operationally up or down. The vRouter agent uses ping and an HTTP URL to the link-local address to check the liveliness of the interface.
If the health check determines that a service is no longer operational, it removes the routes for the VM, thereby disabling packet forwarding to the VM.
The service instance health check is used with service template version 2.
Health Check Object Configuration
Table 1 shows the configurable properties of the health check object.
Field |
Description |
|---|---|
|
Indicates that health check is enabled. The default is |
|
Indicates the health check type: |
|
The protocol type to be used: |
|
The delay, in seconds, to repeat the health check. |
|
The number of seconds to wait for a response. |
|
The number of retries to attempt before declaring an instance health down. |
|
When the monitor protocol is HTTP, the type of HTTP method used, such as GET, PUT, POST, and so on. |
|
When the monitor protocol is HTTP, the URL to be used. For all other cases, such as ICMP, the destination IP address. |
|
When the monitor protocol is HTTP, the expected return code for HTTP operations. |
Health Check Modes
The following modes are supported for the service instance health check:
link-local—A local check for the service VM on the vRouter where the VM is running. In this case, the source IP of the packet is the service chain IP.end-to-end—A remote address or URL is provided for a service health check through a chain of services. The destination of the health check probe is allowed to be outside the service instance. However, the health check probe must be reachable through the interface of the service instance where the health check is attached. The end-to-end health check probe is transmitted all the way to the actual destination outside the service instance. The response to the health check probe is received and processed by the service health check to evaluate the status.Restrictions include:
This check is applicable for a chain where the services are not scaled out.
When this mode is configured, a new health check IP is allocated and used as the source IP of the packet.
The health check IP is allocated per
virtual-machine-interfaceof the service VM where the health check is attached.The agent relies on the
service-health-check-ipflag to use as the source IP.
Note:Contrail Networking supports a segment-based health check for transparent service chain.
Creating a Health Check with the Contrail Web UI
To create a health check with the Contrail Web UI:
Navigate to Configure > Services > Health Check Service, and click to open the Create screen. See Figure 1.
Figure 1: Create Health Check Screen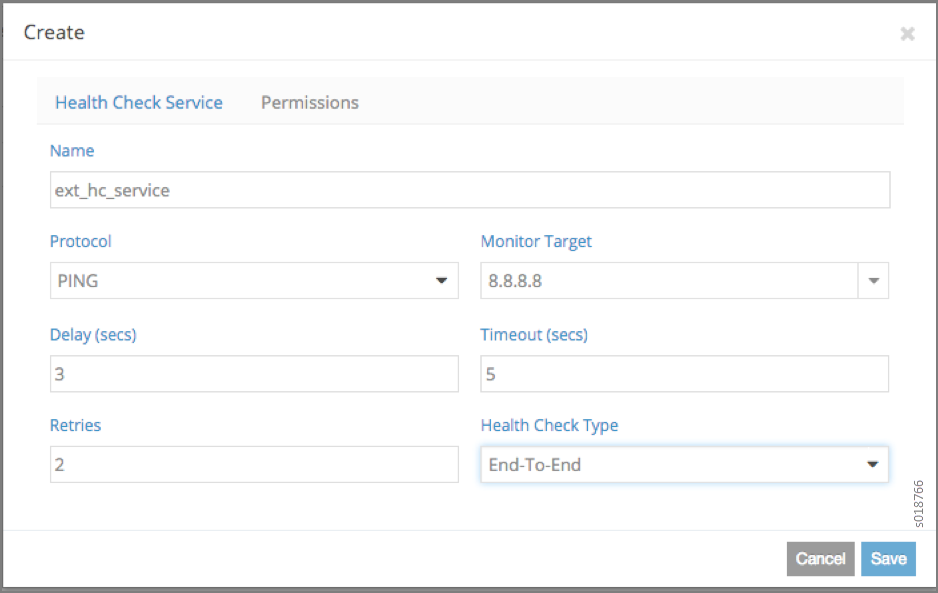
Complete the fields to define the permissions for the health check, see Table 2.
Table 2: Create Health Check Fields Field
Description
Name
Enter a name for the health check service you are creating.
Protocol
Select from the list the protocol to use for the health check, PING, HTTP, BFD, and so on.
Monitor Target
Select from the list the address of the target to be monitored by the health check.
Delay (secs)
The delay, in seconds, to repeat the health check.
Timeout (secs)
The number of seconds to wait for a response.
Retries
The number of retries to attempt before declaring an instance health down.
Health Check Type
Select from the list the type of health check—link-local, end-to-end, segment-based, bgp-as-a-service, and so on.
Using the Health Check
A REST API can be used to create a health check object and define its associated properties, then a link is added to the VM interface.
The health check object can be linked to multiple VM interfaces. Additionally, a VM interface can be associated with multiple health check objects. The following is an example:
HealthCheckObject 1 ---------------- VirtualMachineInterface 1 ---------------- HealthCheckObject 2
|
|
VirtualMachineInterface 2
Health Check Process
The Contrail vRouter agent is responsible for providing the health check service. The agent spawns a Python script to monitor the status of a service hosted on a VM on the same compute node, and the script updates the status to the vRouter agent.
The vRouter agent acts on the status provided by the script to withdraw or restore the exported interface routes. It is also responsible for providing a link-local metadata IP for allowing the script to communicate with the destination IP from the underlay network, using appropriate NAT translations. In a running system, this information is displayed in the vRouter agent introspect at:
http://<compute-node-ip>:8085/Snh_HealthCheckSandeshReq?uuid=
Running health check creates flow entries to perform translation from underlay to overlay. Consequently, in a heavily loaded environment with a full flow table, it is possible to observe false failures.
Bidirectional Forwarding and Detection Health Check over Virtual Machine Interfaces
Contrail Networking supports BFD-based health checks for VMIs.
Health check for VMIs is already supported as poll-based checks with ping and curl commands. When enabled, these health checks run periodically, once every few seconds. Consequently, failure detection times can be quite large, always in seconds.
Health checks based on the BFD protocol provide failure detection and recovery in sub-second intervals, because applications are notified immediately upon BFD session state changes.
If BFD-based health check is configured, whenever a BFD session
status is detected as Up or Down by the health-checker,
corresponding logs are generated.
Logging is enabled in the contrail-vrouter-agent.conf file with
the log severity level SYS_NOTICE.
You can view the log file in the location /var/log/contrail/contrail-vrouter-agent.log
Snippet of sample log message related to BFD session events
2019-02-26 Tue 14:38:49:417.479 SYS_NOTICE BFD session Down interface: test-bfd-hc-vmi.st2 vrf: default-domain:admin:VN.hc.st2:VN.hc.st2 2019-02-26 Tue 14:38:49:479.733 PST SYS_NOTICE BFD session Up interface: test-bfd-hc-vmi.st2 vrf: default-domain:admin:VN.hc.st2:VN.hc.st2
Bidirectional Forwarding and Detection Health Check for BGPaaS
Contrail Networking supports BFD-based health check for BGP as a Service (BGPaaS) sessions.
This health check should not be confused with the BFD-based health check over VMIs feature. The BFD-based health check for VMIs cannot be used for a BGPaaS session, because the session shares a tenant destination address over a set of VMIs, with only one virtual machine interface active at any given time.
When the BFD-based health check for BGP as a Service (BGPaaS) is configured, any time a BFD-for-BGP session is detected as down by the health-checker, corresponding logs and alarms are generated.
When the BFD-based health check is configured, whenever a BFD
session is detected as Up or Down by the health-checker,
corresponding logs are generated.
Logging for this scenario is enabled in the contrail-vrouter-agent.conf
file with the log level SYS_NOTICE.
To enable this health check, configure the ServiceHealthCheckType property and associate it with a bgp-as-a-service configuration
object. This can also be accomplished in the Contrail Web UI.
Health Check of Transparent Service Chain
Contrail Networking enhances service chain redundancy by implementing an end-to-end health check for the transparent service chain. The service health check monitors the status of the service chain and if there is a failure, the control node no longer considers the service chain as a valid next hop, triggering traffic failover.
A segment-based health check is used to verify the health of a single instance in a transparent service chain. The user creates a service-health-check object, with type segment-based, and attaches it to either the left or right interface of the service instance. The service health check packet is injected to the interface to which it is attached. When the packet comes out of the other interface, a reply packet is injected on that interface. If health check requests fail after 30-second retries, the service instance is considered unhealthy and the service VLAN routes of the left and right interfaces are removed. When the agent receives health check replies successfully, it adds the retracted routes back onto both interfaces, which triggers the control node to start reoriginating routes to other service instances on that service chain.
For more information, see https://github.com/tungstenfabric/tf-specs/blob/master/transparent_sc_health_check.md
Service Instance Fate Sharing
Contrail Networking supports service instance (SI) fate sharing that prevents a SI failure from causing a null route. In earlier releases, when an SI fails, the service chain continues to forward packets and routes reoriginate on both sides of the service chain. The packets are dropped in the SI or by the vRouter causing a null route.
As part of SI fate sharing in Contrail Networking, a gateway node automatically reroutes traffic to an alternate cluster and stops the service chain. If one or more than one SI in a service chain fails, routes on both sides of the service chain stops reoriginating and routes automatically converge to a backup service chain that is part of another Contrail cluster.
Contrail Networking uses segment-based health check to verify the health of a SI in a service chain. To identify a failure of an SI, segment-based health check is configured either on the egress or ingress interface of the SI. When SI health check fails, the vRouter agent drops an SI route or a connected route. A connected route is also dropped if the vRouter agent restarts due to a software failure, when a compute node reboots, or when long-lived graceful restart (LLGR) is not enabled. You can detect an SI failure by keeping track of corresponding connected routes of the service chain address.
When an SI is scaled out, the connected route for an SI interface goes down only when all associated VMs have failed.
The control node uses the service-chain-id in ServiceChainInfo to link all SIs in a service chain. When the
control node detects that any SI of the same service-chain-id is down,
it stops reoriginating routes in egress and ingress directions for
all SIs. The control node reoriginates routes only when the connected
routes of all the SIs are up.