Resiliency and High Availability
The Contrail SD-WAN solution is resilient and highly available at all layers. As a result, the network works seamlessly across failures with as little downtime as possible. The following sections discuss high availability at each layer.
Network Control Plane
The control plane itself is a distributed entity in the Contrail SD-WAN solution. The control plane is enabled using vRRs, which peer with the on-premise devices and set up routing dynamically based on information from the Routing Manager and Policy/SLA Manager microservices.
Route reflectors are deployed in a hierarchical structure. The on-premise devices peer with their closest regional route reflector, which itself peers with the other route reflectors.
Headless Forwarding
If on-premise devices lose connectivity to the route reflector in the SD-WAN controller, the devices are still able to continue forwarding traffic. This is referred to as headless operation. This situation will be sub-optimal as the controller cannot monitor and suggest new routes, but the paths still continue to exist and traffic will be forwarded in a best effort manner.
In headless mode, no new configuration or policy changes are made to the device, and no new data is reported from the device. Once connectivity is restored, the device checks in with the controller to ensure it has the latest routing and configuration information.
Data Plane
CSO Release 3.3 and later support on-premise device redundancy. A site can include a cluster of two nodes, acting as primary and secondary, to protect against device and link failures. If the primary node fails, or the links to it are down, traffic will flow through the secondary node.
Spoke Redundancy
Spoke sites can include redundancy by interconnecting two CPE devices to create a single, logical, secure router. NFX Series or SRX Series Firewalls can be used.
Using NFX Series Devices
Figure 1 shows a spoke redundancy setup using NFX Series devices, each with a vSRX Virtual Firewall Virtual Firewall installed. The two CPE devices are interconnected by creating an SRX chassis cluster to form a single logical node. The cluster uses a redundant Ethernet (reth) interface to connect to the Junos Control Plane (JCP) component, which acts as a switch to provide connectivity in and out of the devices.
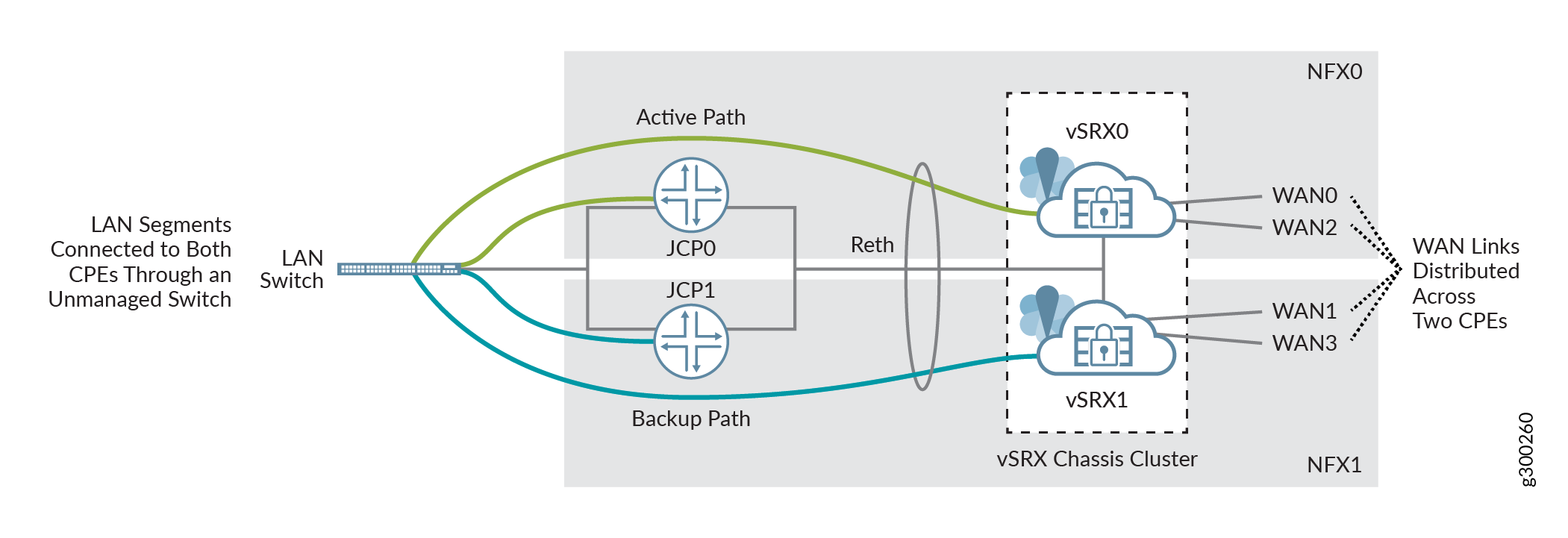
Using SRX Series Firewalls
Figure 2 shows a spoke redundancy setup using SRX Series Firewalls. The two CPE devices are interconnected using chassis clustering to form a single logical node.
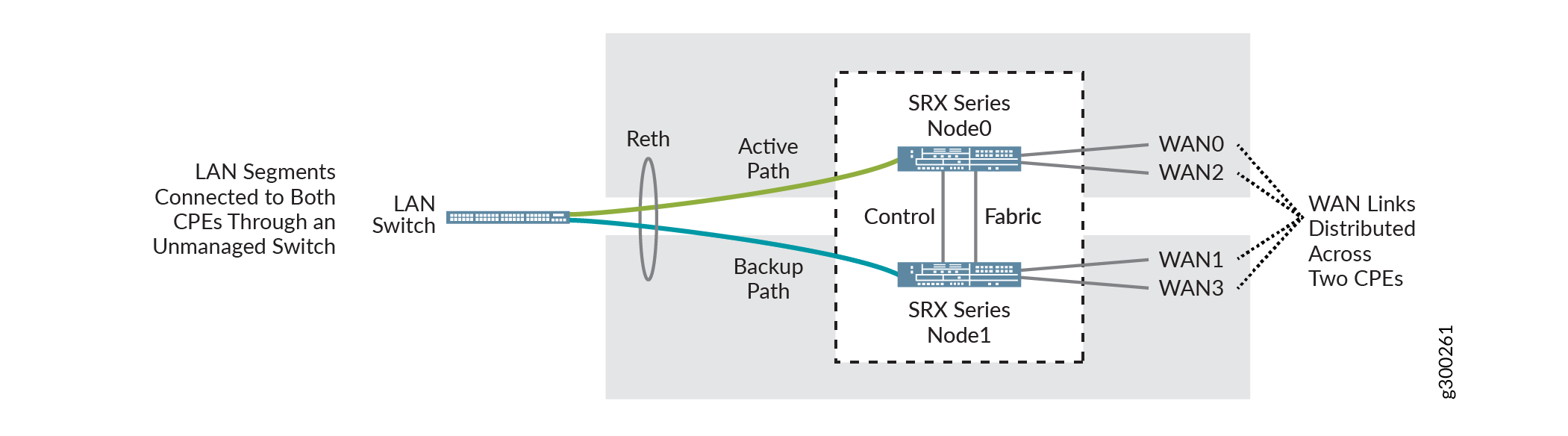
Again, multiple connections on both sides of the devices provide link redundancy, The LAN side uses active/backup links, which are bundled as a reth interface on the SRX cluster. The WAN side uses all four active WAN links, distributed across the two devices.
Failover Scenarios
Table x describes how a spoke redundancy setup will react to various failure scenarios.
Scenario |
NFX Behavior |
SRX Behavior |
|---|---|---|
Device failure |
Node failover of vSRX Virtual Firewall cluster |
Node failover of SRX chassis cluster |
GWR vSRX Virtual Firewall VM failure |
Node failover of vSRX Virtual Firewall cluster |
N/A |
LAN-side link failure |
JCP - LAG based protection for individual link failures vSRX Virtual Firewall - Reth failover to the other cluster node if all LAN links to a node fail |
LAG based protection for individual link failures Reth failover to the other cluster node if all LAN links to a node fail |
WAN-side link failure |
Same as single-CPE - ECMP across remaining links until SLA enforcement from SD-WAN controller |
|
Interconnect physical link failure |
JCP - LAG based protection |
None built in; can add LAG based protection using two interconnected switches between the nodes |
Usage Notes
You must use the same device model of NFX Series or SRX Series Firewall and the devices (primary and secondary) must have the same version of Junos OS installed.
The following SD-WAN features are not supported when using spoke redundancy:
LTE WAN backup link
Service chain support
For more information on spoke redundancy, see Device Redundancy Support Overview in the CSO User Guide.
Hub Redundancy (CPE Multihoming)
For hub-and-spoke topologies, redundancy can also be provided on the hub side by deploying two hub devices in an active/backup setup. If the primary hub goes down, or all overlay tunnels to the primary hub fail, traffic switches over to the secondary hub. When the primary hub comes up again and tunnels are established, traffic moves back to the primary hub.
Dual hub mode can also be used in primary/secondary mode. For example, a hub may be primary for half of the spokes, and secondary for the other half. This way the load is distributed in an active/active manner across all pairs of hub devices. Note that this mode requires meshing the hub devices to maintain flow symmetry across the network.
Design Options
There are several ways to implement redundancy between hub and spoke devices, depending on design requirements:
Single Spoke Device Multihomed to Dual Hub Devices; Single Access
Figure 3 shows how a single spoke device could be multihomed to dual hub devices with single access.
Figure 3: One Spoke Device, One Tunnel to Each Hub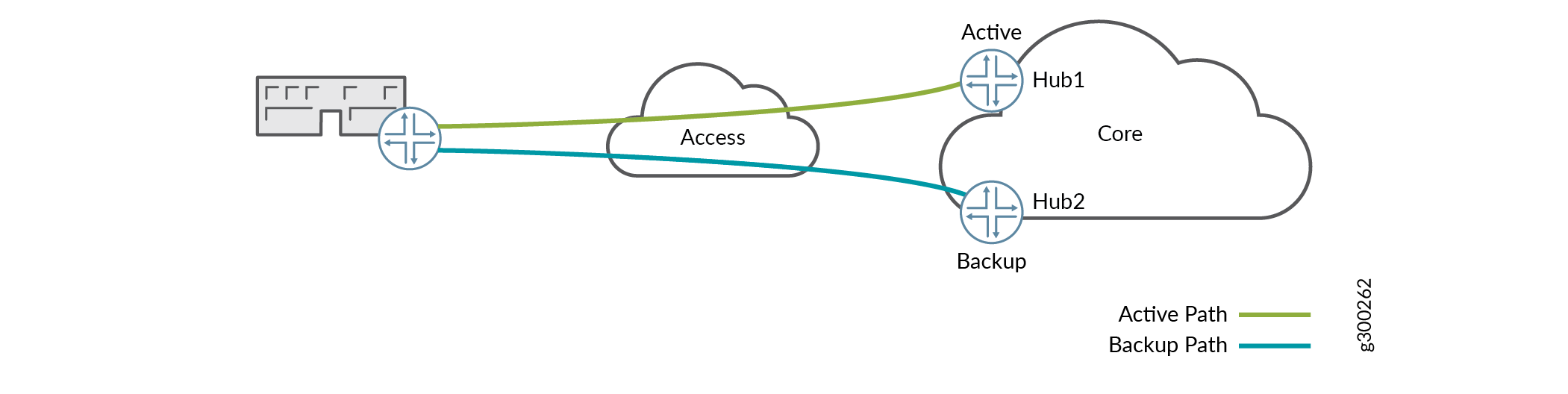
In this scenario, the hub devices are in an active/backup configuration, and spoke site prefixes are routed to the active hub.
Single Spoke Device Multihomed to Dual Hub Devices; Multiple Access
Figure 4 shows how a single spoke device could be multihomed to dual hub devices with multiple access.
Figure 4: One Spoke Device, Two Tunnels to Each Hub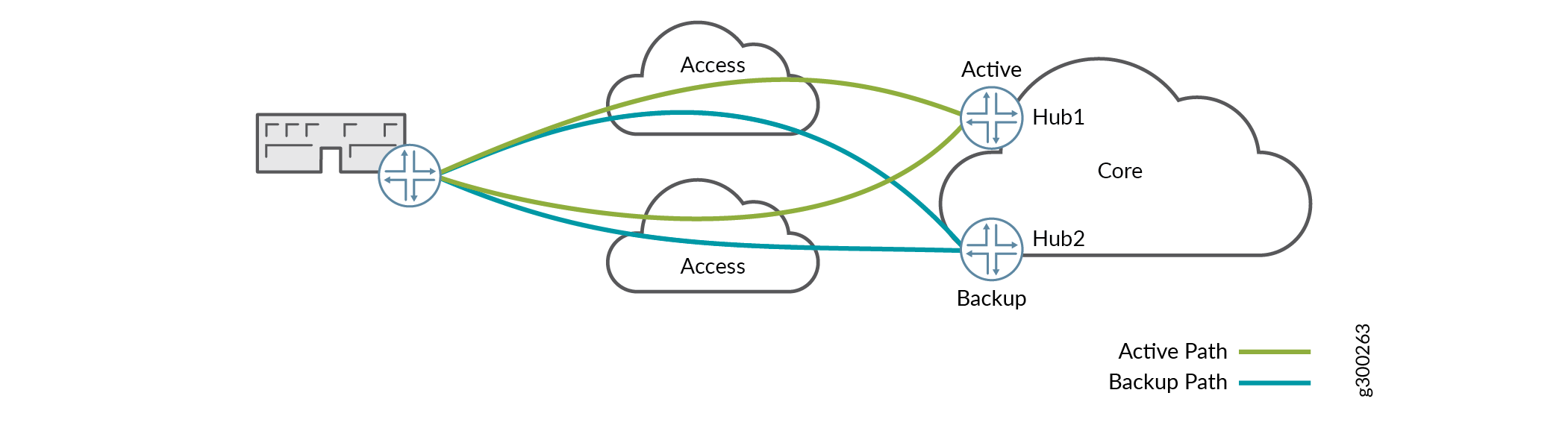
As in the previous scenario, the hub devices are in an active/backup configuration, and spoke site prefixes are routed to the active hub. In addition, the spoke site has overlay links to each hub through each access network. APBR routes traffic from CPE device to active hub over all possible overlays.
Clustered Spoke Devices Multihomed to Dual Hub Devices; Multiple Access
Figure 5 shows how dual CPE devices could be multihomed to dual hub devices with multiple access from each CPE device.
Figure 5: Spoke Cluster, One Tunnel to Each Hub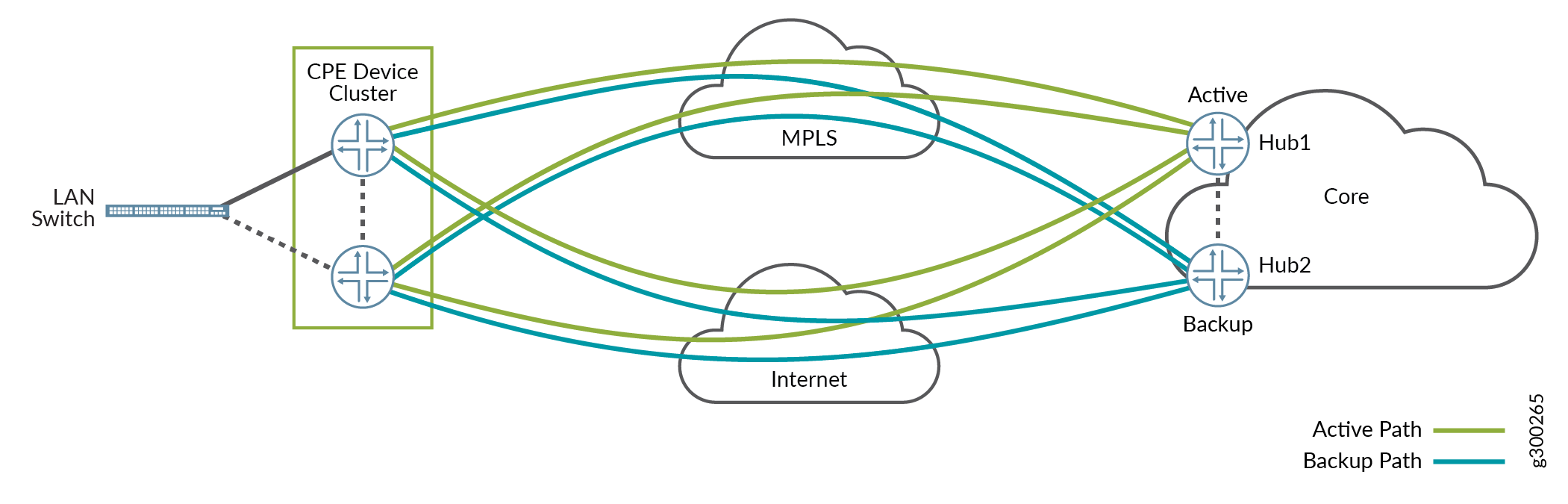
As in the previous scenario, the hub devices are in an active/backup configuration, spoke site prefixes are routed to the active hub, and APBR routes traffic from active CPE device to active hub over all possible overlays. In this scenario, the CPE devices are also in an active/passive configuration.
The spoke site has eight overlay tunnels:
Active CPE to active hub - two active links
Active CPE to backup hub - two backup links
Backup CPE to active hub - two active links
Backup CPE to backup hub - two backup links
Note:Both hubs to which a CPE device is multihomed must be the same type of device.
Note:If using NAT, a hub switchover due to a primary hub failure may cause site-to-Internet and site to cloud application sessions to flap, as the NAT behavior adjusts to the change. Site-to-site sessions will continue to work through the switchover.