예: SRX 시리즈 서비스 게이트웨이를 풀 메시 섀시 클러스터로 구성
이 예시는 고급 SRX 시리즈 디바이스에서 기본 액티브/패시브 풀 메시 섀시 클러스터링을 설정하는 방법을 보여줍니다.
요구 사항
이 예에서 사용되는 하드웨어 및 소프트웨어 구성 요소는 다음과 같습니다.
-
Junos OS 릴리스 9.6 이상을 실행하는 동일한 하드웨어 구성을 가진 두 개의 주니퍼 네트웍스 SRX5800 서비스 게이트웨이.
-
Junos OS 릴리스 9.6 이상을 실행하는 주니퍼 네트웍스 MX480 3D 유니버설 에지 라우터 2개.
-
Junos OS 릴리스 9.6 이상을 실행하는 주니퍼 네트웍스 EX9214 이더넷 스위치 2개.
이 구성 예는 나열된 소프트웨어 릴리스를 사용하여 테스트되었으며 이후의 모든 릴리스에서 작동하는 것으로 가정합니다.
시작하기 전에:
-
2개의 SRX 서비스 게이트웨이를 물리적으로 연결합니다(패브릭 및 제어 포트에 대해 백투백).
개요
이 예시는 한 쌍의 고급 SRX 시리즈 디바이스에서 기본 액티브/패시브 풀 메시 섀시 클러스터링을 설정하는 방법을 보여줍니다. 풀 메시 액티브/패시브 클러스터링을 사용하면 SRX 시리즈 디바이스뿐만 아니라 주변 네트워크 디바이스에도 단일 장애 지점이 없는 환경을 설정할 수 있습니다. 이 예에서 설명한 풀 메시 구축과 액티브/패시브 섀시 클러스터 구축 구성 에서 설명한 기본 액티브/패시브 구축의 주요 차이점은 가능한 장애 시나리오의 복구를 수용하기 위해 추가 설계 요소를 고려해야 한다는 것입니다.
풀 메시 섀시 클러스터링을 사용하려면 각 노드에 대한 RETH 인터페이스를 구성하고 하나 이상의 스위치로 함께 연결되도록 해야 합니다. 그림 1에 나와 있는 이 시나리오에는 4개의 reth 인터페이스(reth0, reth1, reth2, reth3)가 있습니다. reth 인터페이스는 두 개의 물리적 인터페이스(각 노드에서 하나씩)를 함께 번들로 묶습니다. reth 인터페이스는 중복 그룹의 일부입니다. 중복 그룹의 기본 노드(활성)에 있는 멤버만 활성화됩니다. 보조(패시브) 노드의 멤버는 완전히 비활성 상태입니다. 즉, 트래픽을 보내거나 받지 않습니다.
각 reth 인터페이스에는 하나 이상의 논리적 또는 하위 인터페이스(예: reth 0.0, reth0.1 등)가 있을 수 있습니다. 각각 다른 VLAN 태그를 사용해야 합니다.
풀 메시 액티브/패시브 섀시 클러스터는 두 개의 디바이스로 구성됩니다.
-
하나의 디바이스로 라우팅, 방화벽, 네트워크 주소 변환(NAT), VPN 및 보안 서비스를 능동적으로 제공할 뿐만 아니라 섀시 클러스터에 대한 제어를 유지할 수 있습니다.
-
다른 장치는 활성 장치가 비활성 상태가 될 경우 클러스터 장애 조치 기능을 위해 상태를 수동적으로 유지합니다.
그림 1 은 이 예에서 사용되는 토폴로지입니다.
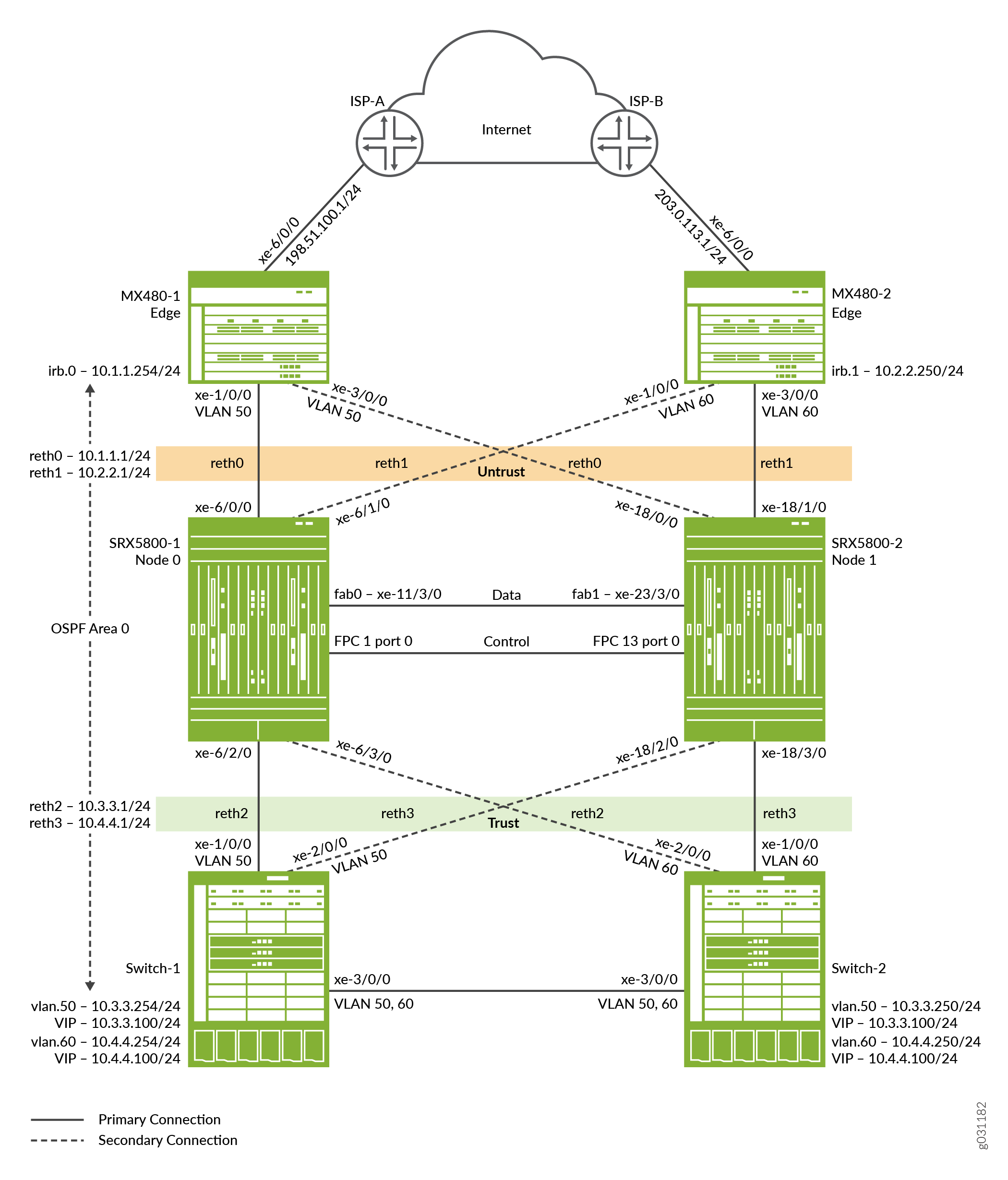
구성
이 예를 구성하려면 다음 절차를 수행합니다.
- 제어 포트 구성
- 클러스터 모드 활성화
- 클러스터 모드 구성
- 영역, 보안 정책 및 프로토콜 구성
- EX9214-1 구성
- EX9214-2 구성
- MX480-1 구성
- MX480-2 구성
- 기타 설정 구성
제어 포트 구성
단계별 절차
중앙 지점(CP)은 항상 클러스터에서 가장 낮은 SPC/SPU에 있으므로 FPC 1/13을 선택합니다(이 예에서는 슬롯 0). 신뢰성을 극대화하려면 제어 포트를 중앙 지점과 별도의 SPC에 배치하십시오(이 예에서는 슬롯 1에서 SPC 사용). 두 디바이스 모두에서 작동 모드 명령을 입력해야 합니다.
SRX5600 및 SRX5800 디바이스에 제어 포트 구성이 필요합니다.
각 디바이스에 대한 제어 포트를 구성하고 구성을 커밋하려면 다음을 수행합니다.
-
SRX5800-1(노드 0)에 대한 제어 포트를 구성하고 구성을 커밋합니다.
user@SRX5800-1# set chassis cluster control-ports fpc 1 port 0 user@SRX5800-1# set chassis cluster control-ports fpc 13 port 0 user@SRX5800-1# commit and-quit -
SRX5800-2(노드 1)에 대한 제어 포트를 구성하고 구성을 커밋합니다.
user@SRX5800-2# set chassis cluster control-ports fpc 1 port 0 user@SRX5800-2# set chassis cluster control-ports fpc 13 port 0 user@SRX5800-2# commit and-quit
클러스터 모드 활성화
단계별 절차
두 장치를 클러스터 모드로 설정합니다. cluster ID와 노드 ID를 설정한 후 클러스터 모드로 들어가려면 재부팅해야 합니다. CLI에서 매개 변수를 포함하여 reboot 시스템이 자동으로 부팅되도록 할 수 있습니다. 두 디바이스 모두에서 작동 모드 명령을 입력해야 합니다. 시스템이 부팅되면 두 노드가 모두 클러스터로 나타납니다.
세그먼트에는 단일 클러스터만 있으므로 이 예에서는 디바이스 SRX5800-1을 노드 0으로, 디바이스 SRX5800-2를 노드 1로 하는 클러스터 ID 1을 사용합니다.
클러스터 모드에서 두 장치를 설정하려면:
-
SRX5800-1(노드 0)에서 클러스터 모드를 활성화합니다.
user@SRX5800-1> set chassis cluster cluster-id 1 node 0 reboot -
SRX5800-2(노드 1)에서 클러스터 모드를 활성화합니다.
user@SRX5800-2> set chassis cluster cluster-id 1 node 1 reboot메모:단일 브로드캐스트 도메인에 여러 SRX 디바이스 클러스터가 있는 경우 MAC 주소 충돌을 방지하기 위해 각 클러스터에 서로 다른 cluster ID를 할당해야 합니다.
클러스터 ID는 두 디바이스에서 동일하지만, 한 디바이스는 노드 0이고 다른 디바이스는 노드 1이므로 노드 ID가 달라야 합니다. 클러스터 ID의 범위는 1에서 15까지입니다. cluster ID를 0으로 설정하는 것은 클러스터를 비활성화하는 것과 같습니다.
이제 장치가 한 쌍입니다. 이 시점부터 클러스터 구성이 노드 구성원 간에 동기화되고 두 개의 개별 장치가 하나의 장치로 작동합니다.
클러스터 모드 구성
단계별 절차
클러스터 모드에서는 명령을 실행할 때 노드 간에 클러스터가 동기화됩니다 commit . 모든 명령은 명령이 구성된 디바이스에 관계없이 두 노드에 모두 적용됩니다.
고급 SRX 시리즈 디바이스에서 섀시 클러스터를 구성하려면 다음을 수행합니다.
-
액티브/패시브 모드에서 RTO(Real-time Objects)를 전달하는 데 사용되는 클러스터의 패브릭(데이터) 포트를 구성합니다. 함께 연결할 두 개의 패브릭 인터페이스를 각 섀시에 하나씩 정의합니다.
user@SRX5800-1# set interfaces fab0 fabric-options member-interfaces xe-11/3/0 user@SRX5800-1# set interfaces fab1 fabric-options member-interfaces xe-23/3/0 -
SRX 서비스 게이트웨이 섀시 클러스터 구성은 하나의 공통된 구성 내에 포함되어 있기 때문에 그룹이라고 하는 Junos OS 노드별 구성 방법을 사용하여 구성의 일부 요소를 특정 멤버에게만 할당합니다.
이
set apply-groups ${node}명령은 노드 변수를 사용하여 그룹이 노드에 적용되는 방법을 정의합니다. 각 노드는 해당 번호를 인식하고 그에 따라 구성을 수락합니다. 또한 클러스터의 개별 컨트롤 플레인에 대해 별도의 IP 주소를 사용하여 SRX5800 서비스 게이트웨이의 fxp0 인터페이스에서 대역 외 관리를 구성해야 합니다.메모:백업 라우터 대상 주소를 x.x.x.0/0으로 구성하는 것은 허용되지 않습니다.
user@SRX5800-1# set groups node0 system host-name SRX5800-1 user@SRX5800-1# set groups node0 system backup-router 10.52.63.254 user@SRX5800-1# set groups node0 system backup-router destination 10.0.0.0/8 user@SRX5800-1# set groups node0 interfaces fxp0 unit 0 family inet address 10.52.43.57/19 user@SRX5800-1# set groups node1 system host-name SRX5800-2 user@SRX5800-1# set groups node1 system backup-router 10.52.63.254 user@SRX5800-1# set groups node1 system backup-router destination 10.0.0.0/8 user@SRX5800-1# set groups node1 interfaces fxp0 unit 0 family inet address 10.52.52.27/19 user@SRX5800-1# set apply-groups “${node}” -
섀시 클러스터링을 위한 중복 그룹을 구성합니다. 각 노드는 인터페이스가 활성 중복 그룹에서 활성화되는 중복 그룹의 인터페이스를 가지고 있습니다(여러 활성 인터페이스가 하나의 중복 그룹에 존재할 수 있음).
중복 그룹 0은 컨트롤 플레인을 제어하고 중복 그룹 1+는 데이터 플레인을 제어하며 데이터 플레인 포트를 포함합니다. 모든 액티브/패시브 모드 클러스터의 경우, 중복 그룹 0과 1만 구성해야 합니다. 4개의 reth 인터페이스를 사용하며, 모두 중복 그룹 1의 구성원입니다. 중복 그룹 외에도 다음을 정의해야 합니다.
-
중복 이더넷 인터페이스 수 - 시스템이 적절한 리소스를 할당할 수 있도록 구성할 수 있는 중복 이더넷 인터페이스(RETH)의 수를 구성합니다.
-
컨트롤 플레인 및 데이터 플레인 우선 순위—컨트롤 플레인에 대한 우선 순위(섀시 클러스터의 경우 높은 우선 순위가 선호됨)를 가진 디바이스와 데이터 플레인에 대해 활성화를 선호하는 디바이스를 정의합니다.
메모:액티브/패시브 또는 액티브/액티브 모드에서 컨트롤 플레인(중복 그룹 0)은 데이터 플레인(중복 그룹 1+ 및 그룹) 섀시와 다른 섀시에서 활성화될 수 있습니다. 그러나 이 예에서는 동일한 섀시 멤버에서 컨트롤 플레인과 데이터 플레인을 모두 활성화하는 것이 좋습니다. 트래픽이 다른 멤버 노드로 이동하기 위해 패브릭 링크를 통과하면 지연이 발생합니다.
user@SRX5800-1# set chassis cluster reth-count 4 user@SRX5800-1# set chassis cluster redundancy-group 0 node 0 priority 129 user@SRX5800-1# set chassis cluster redundancy-group 0 node 1 priority 128 user@SRX5800-1# set chassis cluster redundancy-group 1 node 0 priority 129 user@SRX5800-1# set chassis cluster redundancy-group 1 node 1 priority 128 -
-
데이터 플레인 페일오버 발생 시 다른 섀시 클러스터 멤버가 연결을 원활하게 이어받을 수 있도록 플랫폼에 데이터 인터페이스를 구성합니다.
새로운 액티브 노드로의 원활한 전환은 데이터 플레인 페일오버를 통해 발생합니다. 컨트롤 플레인 페일오버의 경우 모든 데몬이 새 노드에서 다시 시작됩니다. 따라서 피어와의 인접 관계를 잃지 않도록 관련 라우팅 프로토콜에 대해 Graceful Restart를 활성화하는 것이 좋습니다. 이는 패킷 손실 없이 새로운 노드로 원활하게 전환할 수 있도록 도와줍니다.
다음 항목을 정의합니다.
-
reth 인터페이스에 대한 멤버 인터페이스의 멤버십 정보.
user@SRX5800-1# set interfaces xe-6/0/0 gigether-options redundant-parent reth0 user@SRX5800-1# set interfaces xe-6/1/0 gigether-options redundant-parent reth1 user@SRX5800-1# set interfaces xe-6/2/0 gigether-options redundant-parent reth2 user@SRX5800-1# set interfaces xe-6/3/0 gigether-options redundant-parent reth3 user@SRX5800-1# set interfaces xe-18/0/0 gigether-options redundant-parent reth0 user@SRX5800-1# set interfaces xe-18/1/0 gigether-options redundant-parent reth1 user@SRX5800-1# set interfaces xe-18/2/0 gigether-options redundant-parent reth2 user@SRX5800-1# set interfaces xe-18/3/0 gigether-options redundant-parent reth3 -
reth 인터페이스가 속한 중복 그룹. 이 액티브/패시브 예제의 경우 항상 1입니다.
user@SRX5800-1# set interfaces reth0 redundant-ether-options redundancy-group 1 user@SRX5800-1# set interfaces reth1 redundant-ether-options redundancy-group 1 user@SRX5800-1# set interfaces reth2 redundant-ether-options redundancy-group 1 user@SRX5800-1# set interfaces reth3 redundant-ether-options redundancy-group 1 -
인터페이스의 IP 주소와 같은 reth 인터페이스 정보.
user@SRX5800-1# set interfaces reth0 unit 0 family inet address 10.1.1.1/24 user@SRX5800-1# set interfaces reth1 unit 0 family inet address 10.2.2.1/24 user@SRX5800-1# set interfaces reth2 unit 0 family inet address 10.3.3.1/24 user@SRX5800-1# set interfaces reth3 unit 0 family inet address 10.4.4.1/24
-
-
장애 발생 시 섀시 클러스터 동작을 구성합니다.
각 인터페이스는 링크 손실 시 중복 그룹 임계값 255에서 차감된 가중치 값으로 구성됩니다. 장애 조치(failover) 임계값은 255로 하드 코딩되며 변경할 수 없습니다. 인터페이스 링크의 가중치를 변경하여 섀시 페일오버에 미치는 영향을 확인할 수 있습니다.
중복 그룹 임계값이 0에 도달하면, 해당 중복 그룹은 보조 노드로 실패합니다.
SRX5800-1에서 다음 명령을 입력합니다.
user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-6/0/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-6/1/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-6/2/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-6/3/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-18/0/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-18/1/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-18/2/0 weight 255 user@SRX5800-1# set chassis cluster redundancy-group 1 interface-monitor xe-18/3/0 weight 255 user@SRX5800-1# set chassis cluster control-link-recovery user@SRX5800-1# set chassis cluster redundancy-group 1 preempt이 단계는 SRX5800에 대한 액티브/패시브 모드 예시의 섀시 클러스터 구성 부분을 완료합니다. 이 절차의 나머지 부분에서는 구축 시나리오를 완료하기 위해 영역, 가상 라우터, 라우팅, EX9214 및 MX480을 구성하는 방법에 대해 설명합니다.
영역, 보안 정책 및 프로토콜 구성
단계별 절차
영역을 구성하고, 적절한 reth 인터페이스를 추가하고, OSPF를 구성합니다.
영역 및 OSPF를 구성하려면 다음을 수행합니다.
-
두 개의 영역을 구성하고 적절한 reth 인터페이스를 추가합니다.
user@SRX5800-1# set security zones security-zone Untrust interfaces reth0.0 user@SRX5800-1# set security zones security-zone Untrust interfaces reth1.0 user@SRX5800-1# set security zones security-zone Trust interfaces reth2.0 user@SRX5800-1# set security zones security-zone Trust interfaces reth3.0 -
적절한 프로토콜 및 서비스가 트러스트(Trust) 및 언트러스트(Untrust) 영역의 인터페이스에 도달하도록 허용합니다.
user@SRX5800-1# set security zones security-zone Trust host-inbound-traffic protocols ospf user@SRX5800-1# set security zones security-zone Trust host-inbound-traffic system-services all user@SRX5800-1# set security zones security-zone Untrust host-inbound-traffic system-services ping user@SRX5800-1# set security zones security-zone Untrust host-inbound-traffic protocols ospf -
트러스트 영역에서 언트러스트(untrust) 영역으로 트래픽을 허용하도록 보안 정책을 구성합니다.
user@SRX5800-1# set security policies from-zone Trust to-zone Untrust policy allow match source-address any user@SRX5800-1# set security policies from-zone Trust to-zone Untrust policy allow match destination-address any user@SRX5800-1# set security policies from-zone Trust to-zone Untrust policy allow match application any user@SRX5800-1# set security policies from-zone Trust to-zone Untrust policy allow then permit user@SRX5800-1# set security policies from-zone Untrust to-zone Trust policy allow match source-address any user@SRX5800-1# set security policies from-zone Untrust to-zone Trust policy allow match destination-address any user@SRX5800-1# set security policies from-zone Untrust to-zone Trust policy allow match application any user@SRX5800-1# set security policies from-zone Untrust to-zone Trust policy allow then permit -
OSPF를 구성합니다.
user@SRX5800-1# set protocols ospf area 0.0.0.0 interface reth0.0 user@SRX5800-1# set protocols ospf area 0.0.0.0 interface reth1.0 user@SRX5800-1# set protocols ospf area 0.0.0.0 interface reth2.0 user@SRX5800-1# set protocols ospf area 0.0.0.0 interface reth3.0
EX9214-1 구성
단계별 절차
EX9214 이더넷 스위치의 경우, 다음 명령은 SRX5800 서비스 게이트웨이에 대한 이 액티브/패시브 풀 메시 예와 관련된 적용 가능한 구성의 개요만 제공합니다. 가장 주목할 만한 것은 VLAN, 라우팅 및 인터페이스 구성입니다.
EX9214-1을 구성하려면:
-
인터페이스를 구성합니다.
user@EX9214-1# set interfaces xe-1/0/0 unit 0 family ethernet-switching interface-mode access user@EX9214-1# set interfaces xe-1/0/0 unit 0 family ethernet-switching vlan members SRX5800-RETH2 user@EX9214-1# set interfaces xe-2/0/0 unit 0 family ethernet-switching interface-mode access user@EX9214-1# set interfaces xe-2/0/0 unit 0 family ethernet-switching vlan members SRX5800-RETH2 user@EX9214-1# set interfaces xe-3/0/0 unit 0 family ethernet-switching interface-mode trunk user@EX9214-1# set interfaces xe-3/0/0 unit 0 family ethernet-switching vlan members SRX5800-RETH2 user@EX9214-1# set interfaces xe-3/0/0 unit 0 family ethernet-switching vlan members SRX5800-RETH3 -
두 EX 스위치 간에 VRRP를 구성합니다.
user@EX9214-1# set interfaces irb unit 50 family inet address 10.3.3.254/24 vrrp-group 1 virtual-address 10.3.3.100 user@EX9214-1# set interfaces irb unit 50 family inet address 10.3.3.254/24 vrrp-group 1 priority 200 user@EX9214-1# set interfaces irb unit 50 family inet address 10.3.3.254/24 vrrp-group 1 accept-data user@EX9214-1# set interfaces irb unit 60 family inet address 10.4.4.254/24 vrrp-group 2 virtual-address 10.4.4.100 user@EX9214-1# set interfaces irb unit 60 family inet address 10.4.4.254/24 vrrp-group 2 priority 100 user@EX9214-1# set interfaces irb unit 60 family inet address 10.4.4.254/24 vrrp-group 2 accept-data -
VLAN을 구성합니다.
user@EX9214-1# set vlans SRX5800-RETH2 vlan-id 50 user@EX9214-1# set vlans SRX5800-RETH2 l3-interface irb.50 user@EX9214-1# set vlans SRX5800-RETH3 vlan-id 60 user@EX9214-1# set vlans SRX5800-RETH3 l3-interface irb.60 -
프로토콜을 구성합니다.
user@EX9214-1# set protocols ospf area 0.0.0.0 interface irb.50 user@EX9214-1# set protocols ospf area 0.0.0.0 interface irb.60 user@EX9214-1# set protocols rstp interface all
EX9214-2 구성
단계별 절차
EX9214-2를 구성하려면:
-
인터페이스를 구성합니다.
user@EX9214-2# set interfaces xe-1/0/0 unit 0 family ethernet-switching interface-mode access user@EX9214-2# set interfaces xe-1/0/0 unit 0 family ethernet-switching vlan members SRX5800-RETH3 user@EX9214-2# set interfaces xe-2/0/0 unit 0 family ethernet-switching interface-mode access user@EX9214-2# set interfaces xe-2/0/0 unit 0 family ethernet-switching vlan members SRX5800-RETH3 user@EX9214-2# set interfaces xe-3/0/0 unit 0 family ethernet-switching interface-mode trunk user@EX9214-2# set interfaces xe-3/0/0 unit 0 family ethernet-switching vlan members SRX5800-RETH2 user@EX9214-2# set interfaces xe-3/0/0 unit 0 family ethernet-switching vlan members SRX5800-RETH3 -
두 EX 스위치 간에 VRRP를 구성합니다.
user@EX9214-2# set interfaces irb unit 50 family inet address 10.3.3.250/24 vrrp-group 1 virtual-address 10.3.3.100 user@EX9214-2# set interfaces irb unit 50 family inet address 10.3.3.250/24 vrrp-group 1 priority 100 user@EX9214-2# set interfaces irb unit 50 family inet address 10.3.3.250/24 vrrp-group 1 accept-data user@EX9214-2# set interfaces irb unit 60 family inet address 10.4.4.250/24 vrrp-group 2 virtual-address 10.4.4.100 user@EX9214-2# set interfaces irb unit 60 family inet address 10.4.4.250/24 vrrp-group 2 priority 200 user@EX9214-2# set interfaces irb unit 60 family inet address 10.4.4.250/24 vrrp-group 2 accept-data -
VLAN을 구성합니다.
user@EX9214-2# set vlans SRX5800-RETH2 vlan-id 50 user@EX9214-2# set vlans SRX5800-RETH2 l3-interface irb.50 user@EX9214-2# set vlans SRX5800-RETH3 vlan-id 60 user@EX9214-2# set vlans SRX5800-RETH3 l3-interface irb.60 -
프로토콜을 구성합니다.
user@EX9214-2# set protocols ospf area 0.0.0.0 interface irb.50 user@EX9214-2# set protocols ospf area 0.0.0.0 interface irb.60 user@EX9214-2# set protocols rstp interface all
MX480-1 구성
단계별 절차
MX480 에지 라우터의 경우 다음 명령은 SRX5800 서비스 게이트웨이에 대한 이 액티브/패시브 모드 예와 관련된 적용 가능한 구성의 개요만 제공합니다. 특히 스위치의 가상 스위치 인스턴스 내에서 IRB 인터페이스를 사용해야 합니다.
MX480-1을 구성하려면:
-
다운스트림 인터페이스를 구성합니다.
user@MX480-1# set interfaces xe-1/0/0 encapsulation ethernet-bridge user@MX480-1# set interfaces xe-1/0/0 unit 0 family bridge user@MX480-1# set interfaces xe-3/0/0 encapsulation ethernet-bridge user@MX480-1# set interfaces xe-3/0/0 unit 0 family bridge -
업스트림 인터페이스를 구성합니다.
user@MX480-1# set interfaces xe-6/0/0 unit 0 family inet address 198.51.100.1/24 -
IRB 인터페이스를 구성합니다.
user@MX480-1# set interfaces irb unit 0 family inet address 10.1.1.254/24 -
정적 경로 및 Graceful Restart를 구성합니다.
user@MX480-1# set routing-options static route 0.0.0.0/0 next-hop 198.51.100.254 user@MX480-1# set policy-options policy-statement def-route term 1 from protocol static user@MX480-1# set policy-options policy-statement def-route term 1 from route-filter 0.0.0.0/0 exact user@MX480-1# set policy-options policy-statement def-route term 1 then accept -
브리지 도메인을 구성합니다.
user@MX480-1# set bridge-domains BD-50 vlan-id 50 user@MX480-1# set bridge-domains BD-50 domain-type bridge user@MX480-1# set bridge-domains BD-50 interface xe-1/0/0 user@MX480-1# set bridge-domains BD-50 interface xe-3/0/0 user@MX480-1# set bridge-domains BD-50 routing-interface irb.0 -
OSPF를 구성합니다.
user@MX480-1# set protocols ospf area 0.0.0.0 interface irb.0 user@MX480-1# set protocols ospf area 0.0.0.0 interface xe-6/0/0.0 passive user@MX480-1# set protocols ospf export def-route
MX480-2 구성
단계별 절차
MX480-2를 구성하려면:
-
다운스트림 인터페이스를 구성합니다.
user@MX480-2# set interfaces xe-1/0/0 encapsulation ethernet-bridge user@MX480-2# set interfaces xe-1/0/0 unit 0 family bridge user@MX480-2# set interfaces xe-3/0/0 encapsulation ethernet-bridge user@MX480-2# set interfaces xe-3/0/0 unit 0 family bridge -
업스트림 인터페이스를 구성합니다.
user@MX480-2# set interfaces xe-6/0/0 unit 0 family inet address 203.0.113.1/24 -
IRB 인터페이스를 구성합니다.
user@MX480-2# set interfaces irb unit 0 family inet address 10.2.2.250/24 -
정적 경로 및 Graceful Restart를 구성합니다.
user@MX480-2# set routing-options static route 0.0.0.0/0 next-hop 203.0.113.254 user@MX480-2# set policy-options policy-statement def-route term 1 from protocol static user@MX480-2# set policy-options policy-statement def-route term 1 from route-filter 0.0.0.0/0 exact user@MX480-2# set policy-options policy-statement def-route term 1 then accept -
브리지 도메인을 구성합니다.
user@MX480-2# set bridge-domains BD-60 vlan-id 60 user@MX480-2# set bridge-domains BD-60 domain-type bridge user@MX480-2# set bridge-domains BD-60 interface xe-1/0/0 user@MX480-2# set bridge-domains BD-60 interface xe-3/0/0 user@MX480-2# set bridge-domains BD-60 routing-interface irb.0 -
OSPF를 구성합니다.
user@MX480-2# set protocols ospf area 0.0.0.0 interface irb.0 user@MX480-2# set protocols ospf area 0.0.0.0 interface xe-6/0/0.0 passive user@MX480-2# set protocols ospf export def-route
기타 설정 구성
단계별 절차
이 SRX5800에 대한 풀 메시 섀시 클러스터링 예시는 네트워크 주소 변환(NAT), 보안 정책 또는 VPN을 구성하는 방법과 같은 기타 구성에 대해 자세히 설명하지 않습니다. 기본적으로 독립 실행형 구성의 경우와 동일합니다.
그러나 섀시 클러스터 구성에서 프록시 ARP를 수행하는 경우, 멤버 인터페이스가 아닌 RETH 인터페이스에 프록시 ARP 구성을 적용해야 합니다.
SRX5800에서 VLAN 및 트렁크 인터페이스를 사용하여 별도의 논리적 인터페이스 구성을 구성할 수도 있습니다. 이러한 구성은 VLAN 및 트렁크 인터페이스를 사용하는 독립형 구현과 유사합니다.
확인
구성이 제대로 작동하는지 확인하려면 다음의 작업을 수행하십시오:
- 섀시 클러스터 상태 확인
- 섀시 클러스터 인터페이스 확인
- 섀시 클러스터 통계 확인
- 섀시 클러스터 컨트롤 플레인 통계 확인
- 섀시 클러스터 데이터 플레인 통계 확인
- 섀시 클러스터 이중화 그룹 상태 확인
- EX 디바이스 연결 확인
- 로그로 문제 해결
섀시 클러스터 상태 확인
목적
섀시 클러스터 상태, 장애 조치 상태 및 중복 그룹 정보를 확인합니다.
행동
운영 모드에서 명령을 입력합니다 show chassis cluster status .
{primary:node0}
user@SRX5800-1> show chassis cluster status
Monitor Failure codes:
CS Cold Sync monitoring FL Fabric Connection monitoring
GR GRES monitoring HW Hardware monitoring
IF Interface monitoring IP IP monitoring
LB Loopback monitoring MB Mbuf monitoring
NH Nexthop monitoring NP NPC monitoring
SP SPU monitoring SM Schedule monitoring
CF Config Sync monitoring RE Relinquish monitoring
IS IRQ storm
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 0 , Failover count: 1
node0 129 primary no no None
node1 128 secondary no no None
Redundancy group: 1 , Failover count: 3
node0 129 primary yes no None
node1 128 secondary yes no None
의미
샘플 출력은 기본 노드와 보조 노드의 상태를 보여 주며 수동 장애 조치(failover)가 없음을 보여줍니다.
섀시 클러스터 인터페이스 확인
목적
섀시 클러스터 인터페이스에 대한 정보를 확인합니다.
행동
운영 모드에서 명령을 입력합니다 show chassis cluster interfaces .
{primary:node0}
user@SRX5800-1> show chassis cluster interfaces
Control link status: Up
Control interfaces:
Index Interface Monitored-Status Internal-SA Security
0 em0 Up Disabled Disabled
Fabric link status: Up
Fabric interfaces:
Name Child-interface Status Security
(Physical/Monitored)
fab0 xe-11/3/0 Up / Up Disabled
fab0
fab1 xe-23/3/0 Up / Up Disabled
fab1
Redundant-ethernet Information:
Name Status Redundancy-group
reth0 Up 1
reth1 Up 1
reth2 Up 1
reth3 Up 1
Redundant-pseudo-interface Information:
Name Status Redundancy-group
lo0 Up 0
Interface Monitoring:
Interface Weight Status Redundancy-group
(Physical/Monitored)
xe-18/3/0 255 Up / Up 1
xe-18/1/0 255 Up / Up 1
xe-6/3/0 255 Up / Up 1
xe-6/1/0 255 Up / Up 1
xe-18/2/0 255 Up / Up 1
xe-6/2/0 255 Up / Up 1
xe-18/0/0 255 Up / Up 1
xe-6/0/0 255 Up / Up 1
의미
샘플 출력에는 각 인터페이스의 상태, 가중치 값, 해당 인터페이스가 속한 중복 그룹이 표시됩니다.
섀시 클러스터 통계 확인
목적
섀시 클러스터 서비스 및 제어 링크 통계(전송 및 수신된 하트비트), 패브릭 링크 통계(전송 및 수신된 프로브) 및 서비스에 대해 전송 및 수신된 실시간 객체(RTO) 수에 대한 정보를 확인합니다.
행동
운영 모드에서 명령을 입력합니다 show chassis cluster statistics .
{primary:node0}
user@SRX5800-1> show chassis cluster statistics
Control link statistics:
Control link 0:
Heartbeat packets sent: 1191183
Heartbeat packets received: 1191154
Heartbeat packet errors: 0
Fabric link statistics:
Child link 0
Probes sent: 2387707
Probes received: 2387679
Child link 1
Probes sent: 0
Probes received: 0
Services Synchronized:
Service name RTOs sent RTOs received
Translation context 0 0
Incoming NAT 0 0
Resource manager 0 0
DS-LITE create 0 0
Session create 251 7
IPv6 session create 0 0
IPv4/6 session RTO ACK 0 0
Session close 230 4
IPv6 session close 0 0
Session change 0 0
IPv6 session change 0 0
ALG Support Library 0 0
Gate create 0 0
Session ageout refresh requests 0 1
IPv6 session ageout refresh requests 0 0
Session ageout refresh replies 1 0
IPv6 session ageout refresh replies 0 0
IPSec VPN 0 0
Firewall user authentication 0 0
MGCP ALG 0 0
H323 ALG 0 0
SIP ALG 0 0
SCCP ALG 0 0
PPTP ALG 0 0
JSF PPTP ALG 0 0
RPC ALG 0 0
RTSP ALG 0 0
RAS ALG 0 0
MAC address learning 0 0
GPRS GTP 0 0
GPRS SCTP 0 0
GPRS FRAMEWORK 0 0
JSF RTSP ALG 0 0
JSF SUNRPC MAP 0 0
JSF MSRPC MAP 0 0
DS-LITE delete 0 0
JSF SLB 0 0
APPID 0 0
JSF MGCP MAP 0 0
JSF H323 ALG 0 0
JSF RAS ALG 0 0
JSF SCCP MAP 0 0
JSF SIP MAP 0 0
PST_NAT_CREATE 0 0
PST_NAT_CLOSE 0 0
PST_NAT_UPDATE 0 0
JSF TCP STACK 0 0
JSF IKE ALG 0 0
Packet stats Pkts sent Pkts received
ICD Data 0 0
의미
샘플 출력을 사용하여 다음을 수행할 수 있습니다.
-
이(가 Heartbeat packets sent ) 증가하는지 확인합니다.
-
이(가 Heartbeat packets received ) 의 Heartbeats packets sent수에 가까운 숫자인지 확인합니다.
-
이(가) Heartbeats packets errors 0인지 확인합니다.
이를 통해 하트비트 패킷이 오류 없이 전송 및 수신되고 있는지 확인합니다.
섀시 클러스터 컨트롤 플레인 통계 확인
목적
섀시 클러스터 컨트롤 플레인 통계(송수신된 하트비트) 및 패브릭 링크 통계(송수신된 프로브)에 대한 정보를 확인합니다.
행동
운영 모드에서 명령을 입력합니다 show chassis cluster control-plane statistics .
{primary:node0}
user@SRX5800-1> show chassis cluster control-plane statistics
Control link statistics:
Control link 0:
Heartbeat packets sent: 1191222
Heartbeat packets received: 1191193
Heartbeat packet errors: 0
Fabric link statistics:
Child link 0
Probes sent: 2387785
Probes received: 2387757
Child link 1
Probes sent: 0
Probes received: 0
의미
샘플 출력을 사용하여 다음을 수행할 수 있습니다.
-
이(가 Heartbeat packets sent ) 증가하는지 확인합니다.
-
이(가 Heartbeat packets received ) 의 Heartbeats packets sent수에 가까운 숫자인지 확인합니다.
-
이(가) Heartbeats packets errors 0인지 확인합니다.
이를 통해 하트비트 패킷이 오류 없이 전송 및 수신되고 있는지 확인합니다.
섀시 클러스터 데이터 플레인 통계 확인
목적
서비스에 대해 전송 및 수신된 RTO(Real-Time Objects) 수에 대한 정보를 확인합니다.
행동
운영 모드에서 명령을 입력합니다 show chassis cluster data-plane statistics .
{primary:node0}
user@SRX5800-1> show chassis cluster data-plane statistics
Services Synchronized:
Service name RTOs sent RTOs received
Translation context 0 0
Incoming NAT 0 0
Resource manager 0 0
DS-LITE create 0 0
Session create 251 7
IPv6 session create 0 0
IPv4/6 session RTO ACK 0 0
Session close 230 4
IPv6 session close 0 0
Session change 0 0
IPv6 session change 0 0
ALG Support Library 0 0
Gate create 0 0
Session ageout refresh requests 0 1
IPv6 session ageout refresh requests 0 0
Session ageout refresh replies 1 0
IPv6 session ageout refresh replies 0 0
IPSec VPN 0 0
Firewall user authentication 0 0
MGCP ALG 0 0
H323 ALG 0 0
SIP ALG 0 0
SCCP ALG 0 0
PPTP ALG 0 0
JSF PPTP ALG 0 0
RPC ALG 0 0
RTSP ALG 0 0
RAS ALG 0 0
MAC address learning 0 0
GPRS GTP 0 0
GPRS SCTP 0 0
GPRS FRAMEWORK 0 0
JSF RTSP ALG 0 0
JSF SUNRPC MAP 0 0
JSF MSRPC MAP 0 0
DS-LITE delete 0 0
JSF SLB 0 0
APPID 0 0
JSF MGCP MAP 0 0
JSF H323 ALG 0 0
JSF RAS ALG 0 0
JSF SCCP MAP 0 0
JSF SIP MAP 0 0
PST_NAT_CREATE 0 0
PST_NAT_CLOSE 0 0
PST_NAT_UPDATE 0 0
JSF TCP STACK 0 0
JSF IKE ALG 0 0
Packet stats Pkts sent Pkts received
ICD Data 0 0
의미
샘플 출력은 다양한 서비스에 대해 전송 및 수신된 RTO를 보여줍니다.
섀시 클러스터 이중화 그룹 상태 확인
목적
클러스터에 있는 두 노드의 상태 및 우선 순위를 확인하고 기본 노드가 선점되었는지 또는 수동 장애 조치(failover)가 있었는지 여부에 대한 정보를 확인합니다.
행동
운영 모드에서 명령을 입력합니다 chassis cluster status redundancy-group .
{primary:node0}
user@SRX5800-1> show chassis cluster status redundancy-group 1
Monitor Failure codes:
CS Cold Sync monitoring FL Fabric Connection monitoring
GR GRES monitoring HW Hardware monitoring
IF Interface monitoring IP IP monitoring
LB Loopback monitoring MB Mbuf monitoring
NH Nexthop monitoring NP NPC monitoring
SP SPU monitoring SM Schedule monitoring
CF Config Sync monitoring RE Relinquish monitoring
IS IRQ storm
Cluster ID: 1
Node Priority Status Preempt Manual Monitor-failures
Redundancy group: 1 , Failover count: 3
node0 129 primary yes no None
node1 128 secondary yes no None
의미
샘플 출력은 기본 노드와 보조 노드의 상태를 보여 주며 수동 장애 조치(failover)가 없음을 보여줍니다.
EX 디바이스 연결 확인
목적
EX 디바이스에서 연결을 확인합니다.
행동
운영 모드에서 이러한 ping 192.168.1.1 count 2 및 traceroute 192.168.1.1 명령을 입력합니다.
user@@EX1-R3> ping 192.168.1.1 count 2 PING 192.168.1.1 (192.168.1.1): 56 data bytes 64 bytes from 192.168.1.1: icmp_seq=0 ttl=62 time=3.964 ms 64 bytes from 192.168.1.1: icmp_seq=1 ttl=62 time=20.603 ms --- 192.168.1.1 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max/stddev = 3.964/12.284/20.603/8.320 ms
user@@EX1-R3> traceroute 192.168.1.1 traceroute to 192.168.1.1 (192.168.1.1), 30 hops max, 52 byte packets 1 10.3.3.1 (10.3.3.1) 2.287 ms 1.700 ms 1.978 ms 2 10.1.1.254 (10.1.1.254) 3.164 ms 2.750 ms 2.537 ms 3 192.168.1.1 (192.168.1.1) 4.660 ms 4.144 ms 4.473 ms