Monitoreo y solución de problemas
En esta sección se describen las funciones de supervisión de red y solución de problemas de Junos OS.
Ping Hosts
Propósito
Utilice el comando de la CLI ping para comprobar que se puede acceder a un host a través de la red. Este comando es útil para diagnosticar problemas de conectividad de host y red. El dispositivo envía una serie de solicitudes de eco (ping) del Protocolo de mensajes de control de Internet (ICMP) a un host especificado y recibe respuestas de eco ICMP.
Acción
Para usar el ping comando para enviar cuatro solicitudes (recuento de ping) al host3:
ping host count number
Salida de muestra
nombre-comando
ping host3 count 4 user@switch> ping host3 count 4 PING host3.site.net (192.0.2.111): 56 data bytes 64 bytes from 192.0.2.111: icmp_seq=0 ttl=122 time=0.661 ms 64 bytes from 192.0.2.111: icmp_seq=1 ttl=122 time=0.619 ms 64 bytes from 192.0.2.111: icmp_seq=2 ttl=122 time=0.621 ms 64 bytes from 192.0.2.111: icmp_seq=3 ttl=122 time=0.634 ms --- host3.site.net ping statistics --- 4 packets transmitted, 4 packets received, 0% packet loss round-trip min/avg/max/stddev = 0.619/0.634/0.661/0.017 ms
Significado
Los
pingresultados muestran la siguiente información:Tamaño del paquete de respuesta ping (en bytes).
Dirección IP del host desde el que se envió la respuesta.
Número de secuencia del paquete de respuesta ping. Puede usar este valor para hacer coincidir la respuesta ping con la solicitud ping correspondiente.
Valor de recuento de saltos de tiempo de vida (ttl) del paquete de respuesta de ping.
Tiempo total entre el envío del paquete de solicitud de ping y la recepción del paquete de respuesta de ping, en milisegundos. Este valor también se denomina tiempo de ida y vuelta.
Número de solicitudes de ping (sondeos) enviadas al host.
Número de respuestas de ping recibidas del host.
Porcentaje de pérdida de paquetes.
Estadísticas de ida y vuelta: desviación mínima, media, máxima y estándar del tiempo de ida y vuelta.
Supervisar el tráfico a través del enrutador o conmutador
Para diagnosticar un problema, muestre estadísticas en tiempo real sobre el tráfico que pasa a través de las interfaces físicas en el enrutador o conmutador.
Para mostrar estadísticas en tiempo real sobre interfaces físicas, realice estas tareas:
- Mostrar estadísticas en tiempo real sobre todas las interfaces del enrutador o conmutador
- Mostrar estadísticas en tiempo real sobre una interfaz en el enrutador o conmutador
Mostrar estadísticas en tiempo real sobre todas las interfaces del enrutador o conmutador
Propósito
Muestra estadísticas en tiempo real sobre el tráfico que pasa por todas las interfaces del enrutador o conmutador.
Acción
Para mostrar estadísticas en tiempo real sobre el tráfico que pasa por todas las interfaces del enrutador o conmutador:
user@host> monitor interface traffic
Salida de muestra
nombre-comando
user@host> monitor interface traffic host name Seconds: 15 Time: 12:31:09 Interface Link Input packets (pps) Output packets (pps) so-1/0/0 Down 0 (0) 0 (0) so-1/1/0 Down 0 (0) 0 (0) so-1/1/1 Down 0 (0) 0 (0) so-1/1/2 Down 0 (0) 0 (0) so-1/1/3 Down 0 (0) 0 (0) t3-1/2/0 Down 0 (0) 0 (0) t3-1/2/1 Down 0 (0) 0 (0) t3-1/2/2 Down 0 (0) 0 (0) t3-1/2/3 Down 0 (0) 0 (0) so-2/0/0 Up 211035 (1) 36778 (0) so-2/0/1 Up 192753 (1) 36782 (0) so-2/0/2 Up 211020 (1) 36779 (0) so-2/0/3 Up 211029 (1) 36776 (0) so-2/1/0 Up 189378 (1) 36349 (0) so-2/1/1 Down 0 (0) 18747 (0) so-2/1/2 Down 0 (0) 16078 (0) so-2/1/3 Up 0 (0) 80338 (0) at-2/3/0 Up 0 (0) 0 (0) at-2/3/1 Down 0 (0) 0 (0) Bytes=b, Clear=c, Delta=d, Packets=p, Quit=q or ESC, Rate=r, Up=^U, Down=^D
Significado
La salida de ejemplo muestra datos de tráfico para interfaces activas y la cantidad que cada campo ha cambiado desde que se inició el comando o desde que se borraron los contadores con la C clave. En este ejemplo, el monitor interface comando se ha estado ejecutando durante 15 segundos desde que se emitió el comando o desde la última vez que los contadores volvieron a cero.
Mostrar estadísticas en tiempo real sobre una interfaz en el enrutador o conmutador
Propósito
Muestra estadísticas en tiempo real sobre el tráfico que pasa a través de una interfaz en el enrutador o conmutador.
Acción
Para mostrar el tráfico que pasa a través de una interfaz en el enrutador o conmutador, utilice el siguiente comando del modo operativo de la CLI de Junos OS:
user@host> monitor interface interface-name
Salida de muestra
nombre-comando
user@host> monitor interface so-0/0/1 Next='n', Quit='q' or ESC, Freeze='f', Thaw='t', Clear='c', Interface='i' R1 Interface: so-0/0/1, Enabled, Link is Up Encapsulation: PPP, Keepalives, Speed: OC3 Traffic statistics: Input bytes: 5856541 (88 bps) Output bytes: 6271468 (96 bps) Input packets: 157629 (0 pps) Output packets: 157024 (0 pps) Encapsulation statistics: Input keepalives: 42353 Output keepalives: 42320 LCP state: Opened Error statistics: Input errors: 0 Input drops: 0 Input framing errors: 0 Input runts: 0 Input giants: 0 Policed discards: 0 L3 incompletes: 0 L2 channel errors: 0 L2 mismatch timeouts: 0 Carrier transitions: 1 Output errors: 0 Output drops: 0 Aged packets: 0 Active alarms : None Active defects: None SONET error counts/seconds: LOS count 1 LOF count 1 SEF count 1 ES-S 77 SES-S 77 SONET statistics: BIP-B1 0 BIP-B2 0 REI-L 0 BIP-B3 0 REI-P 0 Received SONET overhead: F1 : 0x00 J0 : 0xZ
Significado
La salida de ejemplo muestra los paquetes de entrada y salida para una interfaz SONET determinada (so-0/0/1). La información puede incluir errores comunes de interfaz, como alarmas SONET/SDH y T3, loopbacks detectados y aumentos en los errores de trama.
Para controlar el resultado del comando mientras se está ejecutando, utilice las teclas que se muestran en Tabla 1.
Acción |
Clave |
|---|---|
Mostrar información sobre la siguiente interfaz. El |
|
Mostrar información sobre una interfaz diferente. El comando le pedirá el nombre de una interfaz específica. |
|
Congele la pantalla, deteniendo la visualización de estadísticas actualizadas. |
|
Descongele la visualización y reanude la visualización de estadísticas actualizadas. |
|
Borre (cero) los contadores delta actuales desde que |
|
Detenga el |
|
Consulte el Explorador de CLI para obtener más información sobre el uso de condiciones de coincidencia con el monitor traffic comando.
Descripción general de la memoria direccionable de contenido ternario dinámico
La memoria direccionable de contenido ternario (TCAM) es utilizada por varias aplicaciones como firewall, administración de fallas de conectividad, PTPoE, RFC 2544, etc. El motor de reenvío de paquetes (PFE) de los enrutadores de la serie ACX utiliza TCAM con límites de espacio TCAM definidos. La asignación de recursos TCAM para varias aplicaciones de filtro se distribuye estáticamente. Esta asignación estática conduce a una utilización ineficiente de los recursos TCAM cuando es posible que todas las aplicaciones de filtro no utilicen este recurso TCAM simultáneamente.
La asignación dinámica del espacio TCAM en los enrutadores asigna eficientemente los recursos TCAM disponibles para diversas aplicaciones de filtro. En el modelo TCAM dinámico, varias aplicaciones de filtro (como inet-firewall, bridge-firewall, cfm-filters, etcetera.) pueden utilizar de manera óptima los recursos TCAM disponibles cuando sea necesario. La asignación dinámica de recursos TCAM se basa en el uso y se asigna dinámicamente para las aplicaciones de filtro según sea necesario. Cuando una aplicación de filtro ya no utiliza el espacio TCAM, el recurso se libera y está disponible para su uso por otras aplicaciones. Este modelo dinámico de TCAM atiende a una mayor escala de utilización de recursos de TCAM en función de la demanda de la aplicación.
- Aplicaciones que utilizan infraestructura TCAM dinámica
- Características que utilizan el recurso TCAM
- Monitoreo del uso de recursos TCAM
- Ejemplo: Monitoreo y solución de problemas del recurso TCAM
- Monitoreo y resolución de problemas del recurso TCAM en enrutadores de la serie ACX
- Escalado de servicios en enrutadores ACX5048 y ACX5096
Aplicaciones que utilizan infraestructura TCAM dinámica
Las siguientes categorías de aplicaciones de filtro utilizan la infraestructura TCAM dinámica:
Filtro de firewall: todas las configuraciones de firewall
Filtro implícito: demonios del motor de enrutamiento (RE) que usan filtros para lograr su funcionalidad. Por ejemplo, administración de fallos de conectividad, validación de IP MAC, etcetera.
Filtros dinámicos: aplicaciones que utilizan filtros para lograr la funcionalidad en el nivel PFE. Por ejemplo, clasificador fijo de nivel de interfaz lógica, RFC 2544, etcetera. Los demonios RE no sabrán acerca de estos filtros.
Filtros de inicio del sistema: filtros que requieren entradas a nivel del sistema o un conjunto fijo de entradas en la secuencia de arranque del enrutador. Por ejemplo, captura de protocolo de control de capa 2 y capa 3, aplicador de ARP predeterminado, etcetera.
Nota:El filtro System-init que tiene las aplicaciones para la captura de protocolos de control de capa 2 y capa 3 es esencial para la funcionalidad general del sistema. Las aplicaciones de este grupo de control consumen un espacio TCAM fijo y mínimo del espacio TCAM general. El filtro system-init no utilizará la infraestructura TCAM dinámica y se creará cuando se inicialice el enrutador durante la secuencia de arranque.
Características que utilizan el recurso TCAM
Las aplicaciones que utilizan el recurso TCAM se denominan tcam-app en este documento. Por ejemplo, inet-firewall, puente-firewall, administración de errores de conectividad, administración de fallas de enlace, etc. son todas tcam-apps diferentes.
Tabla 2 describe la lista de tcam-apps que utilizan recursos TCAM.
Aplicaciones TCAM/Usuarios de TCAM |
Característica/funcionalidad |
Etapa TCAM |
|---|---|---|
bd-dtag-validate |
Validación de doble etiquetado de dominio de puente Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Salida |
bd-tpid-swap |
Mapa VLAN de dominio de puente con operación tpid de intercambio |
Salida |
cfm-bd-filter |
Administración de errores de conectividad filtros implícitos de dominio de puente |
Ingreso |
cfm-filter |
Filtros implícitos de administración de errores de conectividad |
Ingreso |
cfm-vpls-filter |
Administración de errores de conectividad filtros vpls implícitos Nota:
Esta función solo se admite en enrutadores ACX5048 y ACX5096. |
Ingreso |
cfm-vpls-ifl-filter |
Administración de errores de conectividad vpls filtros de interfaz lógica implícitos Nota:
Esta función solo se admite en enrutadores ACX5048 y ACX5096. |
Ingreso |
cos-fc |
Clasificador fijo de nivel de interfaz lógica |
Pre-ingreso |
fw-ccc-in |
Firewall de entrada de la familia de conexión cruzada de circuitos |
Ingreso |
fw-family-out |
Firewall de salida a nivel familiar |
Salida |
fw-fbf |
Reenvío basado en filtros de firewall |
Pre-ingreso |
fw-fbf-inet6 |
Reenvío basado en filtros de firewall para la familia inet6 |
Pre-ingreso |
fw-ifl-in |
Firewall de ingreso a nivel de interfaz lógica |
Ingreso |
fw-ifl-out |
Firewall de salida a nivel de interfaz lógica |
Salida |
fw-inet-ftf |
Firewall de entrada de la familia Inet en una tabla de reenvío |
Ingreso |
fw-inet6-ftf |
Firewall de entrada de la familia Inet6 en una tabla de reenvío |
Ingreso |
fw-inet-in |
Firewall de entrada de la familia Inet |
Ingreso |
fw-inet-rpf |
Comprobación de fallo del firewall de entrada de la familia Inet en RPF |
Ingreso |
fw-inet6-in |
Firewall de entrada de la familia Inet6 |
Ingreso |
fw-inet6-family-out |
Firewall de salida a nivel de familia Inet6 |
Salida |
fw-inet6-rpf |
Firewall de entrada de la familia Inet6 en una comprobación de fallo de RPF |
Ingreso |
fw-inet-pm |
Firewall de la familia Inet con acción de espejo de puerto Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Ingreso |
fw-l2-in |
Firewall de entrada de familia de puentes en la interfaz de capa 2 |
Ingreso |
fw-mpls-in |
Firewall de entrada de la familia MPLS |
Ingreso |
fw-semantics |
Semántica de uso compartido de firewall para firewall configurado por CLI |
Pre-ingreso |
fw-vpls-in |
Firewall de entrada de la familia VPLS en la interfaz VPLS |
Ingreso |
ifd-src-mac-fil |
Filtro MAC de origen a nivel de interfaz física |
Pre-ingreso |
ifl-statistics-in |
Estadísticas de interfaz de nivel lógico en la entrada |
Ingreso |
ifl-statistics-out |
Estadísticas de interfaz de nivel lógico a la salida |
Salida |
ing-out-iff |
Aplicación de entrada en nombre del filtro de familia de salida para log y syslog |
Ingreso |
ip-mac-val |
Validación IP MAC |
Pre-ingreso |
ip-mac-val-bcast |
Validación IP MAC para difusión |
Pre-ingreso |
ipsec-reverse-fil |
Filtros inversos para el servicio IPsec Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Ingreso |
irb-cos-rw |
Reescritura de IRB CoS |
Salida |
lfm-802.3ah-in |
Administración de fallos de vínculo (IEEE 802.3ah) en la entrada Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Ingreso |
lfm-802.3ah-out |
Administración de errores de vínculo (IEEE 802.3ah) a la salida |
Salida |
lo0-inet-fil |
Looback interfaz inet filter |
Ingreso |
lo0-inet6-fil |
Filtro inet6 de interfaz Looback |
Ingreso |
mac-drop-cnt |
Las estadísticas de caídas por MAC validan y obtienen filtros MAC |
Ingreso |
mrouter-port-in |
Puerto de enrutador de multidifusión para espionaje |
Ingreso |
napt-reverse-fil |
Filtros inversos para el servicio de traducción de puertos de direcciones de red (NAPT) Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Ingreso |
no-local-switching |
Puente sin conmutación local |
Ingreso |
ptpoe |
Trampas punto a punto a través de Ethernet Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Ingreso |
ptpoe-cos-rw |
Reescritura de CoS para PTPoE Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Salida |
rfc2544-layer2-in |
RFC2544 para el servicio de capa 2 en la entrada |
Pre-ingreso |
rfc2544-layer2-out |
RFC2544 para el servicio de capa 2 a la salida Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Salida |
service-filter-in |
Filtro de servicio al ingresar Nota:
Esta función no se admite en enrutadores ACX5048 y ACX5096. |
Ingreso |
Monitoreo del uso de recursos TCAM
Puede utilizar los comandos show y clear para supervisar y solucionar problemas de uso de recursos TCAM dinámicos.
Tabla 3 resume los comandos de la interfaz de línea de comandos (CLI) que puede usar para supervisar y solucionar problemas de uso de recursos TCAM dinámicos.
Tarea |
Comando |
|---|---|
Mostrar las aplicaciones compartidas y las aplicaciones relacionadas para una aplicación en particular |
|
Mostrar el uso de recursos TCAM para una aplicación y las etapas (salida, entrada y preentrada) |
(ACX5448) Mostrar resumen de HW del filtro PFE |
Mostrar los errores de uso de recursos TCAM para aplicaciones y etapas (salida, entrada y preentrada) |
|
Borra las estadísticas de errores de uso de recursos TCAM para aplicaciones y etapas (salida, entrada y preentrada) |
Ejemplo: Monitoreo y solución de problemas del recurso TCAM
En esta sección se describe un caso de uso en el que puede supervisar y solucionar problemas de recursos de TCAM mediante comandos show. En este caso de uso, ha configurado servicios de capa 2 y las aplicaciones relacionadas con el servicio de capa 2 utilizan recursos TCAM. El enfoque dinámico, como se muestra en este ejemplo, le brinda la flexibilidad completa para administrar los recursos de TCAM según sea necesario.
El requisito de servicio es el siguiente:
Cada dominio de puente tiene una interfaz UNI y una interfaz NNI
Cada interfaz UNI tiene:
Un controlador de nivel de interfaz lógica para vigilar el tráfico a 10 Mbps.
Clasificador multicampo con cuatro términos para asignar clase de reenvío y prioridad de pérdida.
Cada interfaz UNI configura CFM UP MEP en el nivel 4.
Cada interfaz NNI configura CFM DOWN MEP en el nivel 2
Consideremos un escenario en el que hay 100 servicios configurados en el enrutador. Con esta escala, todas las aplicaciones se configuran correctamente y el estado muestra OK el estado.
-
Visualización del uso de recursos TCAM para todas las etapas.
Para ver el uso de recursos TCAM para todas las etapas (salida, entrada y preentrada), utilice el
show pfe tcam usage all-tcam-stages detailcomando. En enrutadores ACX5448, utilice elshow pfe filter hw summarycomando para ver el recurso TCAM usgae.user@host> show pfe tcam usage all-tcam-stages detail Slot 0 Tcam Resource Stage: Pre-Ingress -------------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usage Tcam Resource Stage: Ingress ---------------------------- Free [hw-grps: 2 out of 8] Group: 11, Mode: SINGLE, Hw grps used: 3, Tcam apps: 2 Used Allocated Available Errors Tcam-Entries 800 1024 224 0 Counters 800 1024 224 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- cfm-filter 500 500 0 3 OK cfm-bd-filter 300 300 0 2 OK Group: 8, Mode: DOUBLE, Hw grps used: 2, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 500 512 12 0 Counters 500 1024 524 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-l2-in 500 500 0 2 OK fw-semantics 0 X X 1 OK Group: 14, Mode: SINGLE, Hw grps used: 1, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 200 512 312 0 Counters 200 512 312 0 Policers 100 512 412 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-ifl-in 200 200 100 1 OK Tcam Resource Stage: Egress --------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usage Configure servicios adicionales de capa 2 en el enrutador.
Por ejemplo, agregue 20 servicios más en el enrutador, aumentando así el número total de servicios a 120. Después de agregar más servicios, puede comprobar el estado de la configuración comprobando el mensaje syslog mediante el comando
show log messageso ejecutando elshow pfe tcam errorscomando.A continuación se muestra un ejemplo de salida de mensaje syslog que muestra la escasez de recursos TCAM para filtros de familia de conmutación Ethernet para configuraciones más recientes ejecutando el comando CLI
show log messages.[Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_check_phy_slice_availability :Insufficient phy slices to accomodate grp:13/IN_IFF_BRIDGE mode:1/DOUBLE [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_check_resource_availability :Could not write filter: f-bridge-ge-0/0/0.103-i, insufficient TCAM resources [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_update_filter_in_hw :acx_dfw_check_resource_availability failed for filter:f-bridge-ge-0/0/0.103-i [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_create_hw_instance :Status:1005 Could not program dfw(f-bridge-ge-0/0/0.103-i) type(IN_IFF_BRIDGE)! [1005] [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_bind_shim :[1005] Could not create dfw(f-bridge-ge-0/0/0.103-i) type(IN_IFF_BRIDGE) [Sat Jul 11 16:10:33.794 LOG: Err] ACX Error (dfw):acx_dfw_bind :[1000] bind failed for filter f-bridge-ge-0/0/0.103-i
Si utiliza el comando de la
show pfe tcam errors all-tcam-stages detailCLI para comprobar el estado de la configuración, el resultado será el siguiente:user@host> show pfe tcam errors all-tcam-stages detail Slot 0 Tcam Resource Stage: Pre-Ingress -------------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usage Tcam Resource Stage: Ingress ---------------------------- Free [hw-grps: 2 out of 8] Group: 11, Mode: SINGLE, Hw grps used: 3, Tcam apps: 2 Used Allocated Available Errors Tcam-Entries 960 1024 64 0 Counters 960 1024 64 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- cfm-filter 600 600 0 3 OK cfm-bd-filter 360 360 0 2 OK Group: 8, Mode: DOUBLE, Hw grps used: 2, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 510 512 2 18 Counters 510 1024 514 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-l2-in 510 510 0 2 FAILED fw-semantics 0 X X 1 OK App error statistics: ---------------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-l2-in 18 0 0 2 FAILED fw-semantics 0 X X 1 OK Group: 14, Mode: SINGLE, Hw grps used: 1, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 240 512 272 0 Counters 240 512 272 0 Policers 120 512 392 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-ifl-in 240 240 120 1 OK Tcam Resource Stage: Egress --------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usageEl resultado indica que la fw-l2-in aplicación se está quedando sin recursos TCAM y pasa al estado ERROR. Aunque hay dos segmentos TCAM disponibles en la etapa de entrada, la fw-l2-in aplicación no puede utilizar el espacio TCAM disponible debido a su modo (DOUBLE), lo que provoca un error en la escasez de recursos.
-
Arreglar las aplicaciones que han fallado debido a la escasez de recursos TCAM.
La fw-l2-in aplicación falló debido a que se agregó más cantidad de servicios en los enrutadores, lo que resultó en una escasez de recursos TCAM. Aunque otras aplicaciones parecen funcionar bien, se recomienda desactivar o quitar los servicios recién agregados para que la fw-l2-in aplicación pase a un estado OK. Después de quitar o desactivar los servicios recién agregados, debe ejecutar los
show pfe tcam usagecomandos yshow pfe tcam errorpara comprobar que no hay más aplicaciones en estado de error.Para ver el uso de recursos TCAM para todas las etapas (salida, entrada y preentrada), utilice el
show pfe tcam usage all-tcam-stages detailcomando. Para enrutadores ACX5448, utilice elshow pfe filter hw summarycomando para ver el uso de recursos TCAM.user@host> show pfe tcam usage all-tcam-stages detail Slot 0 Tcam Resource Stage: Pre-Ingress -------------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usage Tcam Resource Stage: Ingress ---------------------------- Free [hw-grps: 2 out of 8] Group: 11, Mode: SINGLE, Hw grps used: 3, Tcam apps: 2 Used Allocated Available Errors Tcam-Entries 800 1024 224 0 Counters 800 1024 224 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- cfm-filter 500 500 0 3 OK cfm-bd-filter 300 300 0 2 OK Group: 8, Mode: DOUBLE, Hw grps used: 2, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 500 512 12 18 Counters 500 1024 524 0 Policers 0 1024 1024 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-l2-in 500 500 0 2 OK fw-semantics 0 X X 1 OK Group: 14, Mode: SINGLE, Hw grps used: 1, Tcam apps: 1 Used Allocated Available Errors Tcam-Entries 200 512 312 0 Counters 200 512 312 0 Policers 100 512 412 0 App tcam usage: ---------------- App-Name Entries Counters Policers Precedence State Related-App-Name .. ----------------------------------------------------------------- fw-ifl-in 200 200 100 1 OK Tcam Resource Stage: Egress --------------------------- Free [hw-grps: 3 out of 3] No dynamic tcam usagePara ver los errores de uso de recursos TCAM para todas las etapas (salida, entrada y preingreso), use el
show pfe tcam errors all-tcam-stagescomando.user@host> show pfe tcam errors all-tcam-stages detail Slot 0 Tcam Resource Stage: Pre-Ingress -------------------------------- No tcam usage Tcam Resource Stage: Ingress ---------------------------- Group: 11, Mode: SINGLE, Hw grps used: 3, Tcam apps: 2 Errors Resource-Shortage Tcam-Entries 0 0 Counters 0 0 Policers 0 0 Group: 8, Mode: DOUBLE, Hw grps used: 2, Tcam apps: 1 Errors Resource-Shortage Tcam-Entries 18 0 Counters 0 0 Policers 0 0 Group: 14, Mode: SINGLE, Hw grps used: 1, Tcam apps: 1 Errors Resource-Shortage Tcam-Entries 0 0 Counters 0 0 Policers 0 0 Tcam Resource Stage: Egress --------------------------- No tcam usagePuede ver que todas las aplicaciones que utilizan los recursos TCAM están en OK estado e indica que el hardware se ha configurado correctamente.
Como se muestra en el ejemplo, deberá ejecutar los show pfe tcam errors comandos y show pfe tcam usage en cada paso para asegurarse de que las configuraciones son válidas y de que las aplicaciones que usan el recurso TCAM están en buen estado. Para enrutadores ACX5448, use el show pfe filter hw summary comando para ver el uso de recursos TCAM.
Monitoreo y resolución de problemas del recurso TCAM en enrutadores de la serie ACX
La asignación dinámica del espacio de memoria direccionable de contenido ternario (TCAM) en la serie ACX asigna eficientemente los recursos TCAM disponibles para diversas aplicaciones de filtro. En el modelo TCAM dinámico, varias aplicaciones de filtro (como inet-firewall, bridge-firewall, cfm-filters, etcetera.) pueden utilizar de manera óptima los recursos TCAM disponibles cuando sea necesario. La asignación dinámica de recursos TCAM se basa en el uso y se asigna dinámicamente para las aplicaciones de filtro según sea necesario. Cuando una aplicación de filtro ya no utiliza el espacio TCAM, el recurso se libera y está disponible para su uso por otras aplicaciones. Este modelo dinámico de TCAM atiende a una mayor escala de utilización de recursos de TCAM en función de la demanda de la aplicación. Puede utilizar los comandos show and clear para supervisar y solucionar problemas de uso dinámico de recursos TCAM en los enrutadores de la serie ACX.
Las aplicaciones que utilizan el recurso TCAM se denominan tcam-app en este documento.
Descripción general de la memoria direccionable de contenido ternario dinámico muestra la tarea y los comandos para supervisar y solucionar problemas de recursos TCAM en enrutadores de la serie ACX
|
Cómo |
Comando |
|---|---|
|
Ver las aplicaciones compartidas y relacionadas para una aplicación en particular. |
|
|
Vea el número de aplicaciones en todas las etapas de tcam. |
|
|
Vea el número de aplicaciones que utilizan el recurso TCAM en una etapa especificada. |
|
|
Vea el recurso TCAM utilizado por una aplicación en detalle. |
|
|
Ver el recurso TCAM utilizado por una aplicación en una etapa especificada. |
|
|
Conozca la cantidad de recursos TCAM consumidos por una tcam-app |
|
|
Vea los errores de uso de recursos TCAM para todas las etapas. |
|
|
Ver los errores de uso de recursos TCAM para una etapa |
|
|
Ver los errores de uso de recursos TCAM para una aplicación. |
|
|
Ver los errores de uso de recursos TCAM para una aplicación junto con su otra aplicación compartida. |
|
|
Borre las estadísticas de errores de uso de recursos TCAM para todas las etapas. |
|
|
Borre las estadísticas de error de uso de recursos TCAM para una etapa especificada |
|
|
Borre las estadísticas de error de uso de recursos TCAM para una aplicación. |
|
Para obtener más información sobre el TCAM dinámico en la serie ACX, consulte Descripción general de la memoria direccionable de contenido ternario dinámico.
Escalado de servicios en enrutadores ACX5048 y ACX5096
En enrutadores ACX5048 y ACX5096, un servicio típico (como ELINE, ELAN e IP VPN) que se implementa puede requerir aplicaciones (como policías, filtros de firewall, administración de errores de conectividad IEEE 802.1ag, RFC2544) que utilicen la infraestructura TCAM dinámica.
Las aplicaciones de servicio que usan recursos TCAM están limitadas por la disponibilidad de recursos TCAM. Por lo tanto, la escala del servicio depende del consumo del recurso TCAM por parte de dichas aplicaciones.
Puede encontrar un caso de uso de ejemplo para monitorear y solucionar problemas de escala de servicio en enrutadores ACX5048 y ACX5096 en la sección Descripción general de la memoria direccionable de contenido ternario dinámico .
Solucionar problemas de resolución de nombres DNS en directivas de seguridad del sistema lógico (solo administradores principales)
Problema
Description
Es posible que la dirección de un nombre de host en una entrada de la libreta de direcciones que se usa en una directiva de seguridad no se resuelva correctamente.
Causa
Normalmente, las entradas de la libreta de direcciones que contienen nombres de host dinámicos se actualizan automáticamente para los firewalls de la serie SRX. El campo TTL asociado a una entrada DNS indica la hora a partir de la cual la entrada debe actualizarse en la caché de directivas. Una vez que expira el valor TTL, el firewall de la serie SRX actualiza automáticamente la entrada DNS para una entrada de libreta de direcciones.
Sin embargo, si el firewall de la serie SRX no puede obtener una respuesta del servidor DNS (por ejemplo, la solicitud DNS o el paquete de respuesta se pierde en la red o el servidor DNS no puede enviar una respuesta), es posible que la dirección de un nombre de host en una entrada de libreta de direcciones no se resuelva correctamente. Esto puede hacer que el tráfico se caiga ya que no se encuentra ninguna política de seguridad o coincidencia de sesión.
Solución
El administrador principal puede usar el comando para mostrar información de show security dns-cache caché DNS en el firewall de la serie SRX. Si es necesario actualizar la información de caché DNS, el administrador principal puede usar el clear security dns-cache comando.
Estos comandos solo están disponibles para el administrador principal en dispositivos configurados para sistemas lógicos. Este comando no está disponible en sistemas lógicos de usuario ni en dispositivos que no están configurados para sistemas lógicos.
Consulte también
Solucionar problemas de la interfaz de servicios de vínculo
Para resolver problemas de configuración en una interfaz de servicios de vínculo:
- Determinar qué componentes de CoS se aplican a los vínculos constituyentes
- Determinar qué causa la fluctuación y la latencia en el paquete multivínculo
- Determinar si LFI y equilibrio de carga funcionan correctamente
- Determinar por qué se dejan caer paquetes en un PVC entre un dispositivo de Juniper Networks y un dispositivo de terceros
Determinar qué componentes de CoS se aplican a los vínculos constituyentes
Problema
Description
Está configurando un paquete multivínculo, pero también tiene tráfico sin encapsulación MLPPP que pasa a través de vínculos constituyentes del paquete multivínculo. ¿Aplica todos los componentes de CoS a los enlaces constituyentes o es suficiente aplicarlos al paquete multivínculo?
Solución
Puede aplicar una asignación de programador al paquete multivínculo y a sus vínculos constituyentes. Aunque puede aplicar varios componentes de CoS con la asignación del programador, configure solo los que sean necesarios. Le recomendamos que mantenga la configuración de los enlaces constituyentes simple para evitar retrasos innecesarios en la transmisión.
Tabla 5 muestra los componentes de CoS que se aplicarán en un paquete multivínculo y sus vínculos constituyentes.
Componente Cos |
Paquete Multilink |
Enlaces constituyentes |
Explicación |
|---|---|---|---|
Clasificador |
Sí |
No |
La clasificación CoS tiene lugar en el lado entrante de la interfaz, no en el lado de transmisión, por lo que no se necesitan clasificadores en los enlaces constituyentes. |
Clase de reenvío |
Sí |
No |
La clase de reenvío se asocia a una cola y la cola se aplica a la interfaz mediante una asignación de programador. La asignación de cola está predeterminada en los vínculos constituyentes. Todos los paquetes de Q2 del paquete multivínculo se asignan a Q2 del enlace constituyente, y los paquetes de todas las demás colas se ponen en cola en Q0 del enlace constituyente. |
Mapa del programador |
Sí |
Sí |
Aplique las asignaciones del programador en el paquete multivínculo y el vínculo constituyente de la siguiente manera:
|
Velocidad de conformación para un programador por unidad o un programador de nivel de interfaz |
No |
Sí |
Dado que la programación por unidad se aplica solo en el punto final, aplique esta velocidad de conformación solo a los vínculos constituyentes. Cualquier configuración aplicada anteriormente se sobrescribe con la configuración del vínculo constituyente. |
Velocidad de transmisión exacta o modelado a nivel de cola |
Sí |
No |
La forma a nivel de interfaz aplicada en los vínculos constituyentes anula cualquier forma en la cola. Por lo tanto, aplique la forma exacta de la velocidad de transmisión solo en el paquete multivínculo. |
Reescritura de reglas |
Sí |
No |
Los bits de reescritura se copian del paquete en los fragmentos automáticamente durante la fragmentación. Por lo tanto, lo que se configura en el paquete multivínculo se lleva en los fragmentos a los enlaces constituyentes. |
Grupo de canales virtuales |
Sí |
No |
Los grupos de canales virtuales se identifican mediante reglas de filtro de firewall que se aplican a los paquetes solo antes del paquete multivínculo. Por lo tanto, no es necesario aplicar la configuración del grupo de canales virtuales a los vínculos constituyentes. |
Consulte también
Determinar qué causa la fluctuación y la latencia en el paquete multivínculo
Problema
Description
Para probar la fluctuación y la latencia, se envían tres flujos de paquetes IP. Todos los paquetes tienen la misma configuración de prioridad de IP. Después de configurar LFI y CRTP, la latencia aumentó incluso en un vínculo no congestionado. ¿Cómo puede reducir la fluctuación y la latencia?
Solución
Para reducir la fluctuación y la latencia, haga lo siguiente:
Asegúrese de que ha configurado una velocidad de conformación en cada enlace constituyente.
Asegúrese de que no ha configurado una velocidad de conformación en la interfaz de servicios de vínculo.
Asegúrese de que el valor de la velocidad de conformación configurada sea igual al ancho de banda de la interfaz física.
Si las velocidades de conformación están configuradas correctamente y la fluctuación persiste, comuníquese con el Centro de asistencia técnica de Juniper Networks (JTAC).
Determinar si LFI y equilibrio de carga funcionan correctamente
Problema
Description
En este caso, tiene una sola red que admite varios servicios. La red transmite datos y tráfico de voz sensible a los retrasos. Después de configurar MLPPP y LFI, asegúrese de que los paquetes de voz se transmiten a través de la red con muy poco retraso y fluctuación. ¿Cómo puede saber si los paquetes de voz se tratan como paquetes LFI y si el equilibrio de carga se realiza correctamente?
Solución
Cuando LFI está habilitado, los paquetes de datos (no LFI) se encapsulan con un encabezado MLPPP y se fragmentan en paquetes de un tamaño especificado. Los paquetes de voz sensibles al retardo (LFI) están encapsulados en PPP e intercalados entre fragmentos de paquetes de datos. Las colas y el equilibrio de carga se realizan de manera diferente para los paquetes LFI y no LFI.
Para comprobar que LFI se realiza correctamente, determine que los paquetes estén fragmentados y encapsulados según lo configurado. Después de saber si un paquete se trata como un paquete LFI o un paquete que no es LFI, puede confirmar si el equilibrio de carga se realiza correctamente.
Solution Scenario: supongamos que dos dispositivos de Juniper Networks, R0 y R1, están conectados por un paquete lsq-0/0/0.0 multivínculo que agrega dos vínculos se-1/0/0 serie y se-1/0/1. En R0 y R1, MLPPP y LFI se habilitan en la interfaz de servicios de vínculo y el umbral de fragmentación se establece en 128 bytes.
En este ejemplo, usamos un generador de paquetes para generar flujos de voz y datos. Puede utilizar la función de captura de paquetes para capturar y analizar los paquetes en la interfaz entrante.
Los dos flujos de datos siguientes se enviaron en el paquete multivínculo:
100 paquetes de datos de 200 bytes (mayores que el umbral de fragmentación)
500 paquetes de datos de 60 bytes (más pequeños que el umbral de fragmentación)
Las dos secuencias de voz siguientes se enviaron en el paquete multivínculo:
100 paquetes de voz de 200 bytes desde el puerto fuente 100
300 paquetes de voz de 200 bytes desde el puerto fuente 200
Para confirmar que la LFI y el equilibrio de carga se realizan correctamente:
En este ejemplo, solo se muestran y describen las partes significativas de la salida del comando.
Compruebe la fragmentación de paquetes. Desde el modo operativo, escriba el
show interfaces lsq-0/0/0comando para comprobar que los paquetes grandes están fragmentados correctamente.user@R0#> show interfaces lsq-0/0/0 Physical interface: lsq-0/0/0, Enabled, Physical link is Up Interface index: 136, SNMP ifIndex: 29 Link-level type: LinkService, MTU: 1504 Device flags : Present Running Interface flags: Point-To-Point SNMP-Traps Last flapped : 2006-08-01 10:45:13 PDT (2w0d 06:06 ago) Input rate : 0 bps (0 pps) Output rate : 0 bps (0 pps) Logical interface lsq-0/0/0.0 (Index 69) (SNMP ifIndex 42) Flags: Point-To-Point SNMP-Traps 0x4000 Encapsulation: Multilink-PPP Bandwidth: 16mbps Statistics Frames fps Bytes bps Bundle: Fragments: Input : 0 0 0 0 Output: 1100 0 118800 0 Packets: Input : 0 0 0 0 Output: 1000 0 112000 0 ... Protocol inet, MTU: 1500 Flags: None Addresses, Flags: Is-Preferred Is-Primary Destination: 9.9.9/24, Local: 9.9.9.10Meaning: el resultado muestra un resumen de los paquetes que transitan por el dispositivo en el paquete multivínculo. Compruebe la siguiente información en el paquete multivínculo:El número total de paquetes en tránsito = 1000
El número total de fragmentos en tránsito=1100
El número de paquetes de datos fragmentados =100
El número total de paquetes enviados (600 + 400) en el paquete multivínculo coincide con el número de paquetes en tránsito (1000), lo que indica que no se descartó ningún paquete.
El número de fragmentos en tránsito supera en 100 el número de paquetes en tránsito, lo que indica que 100 paquetes de datos grandes se fragmentaron correctamente.
Corrective Action: si los paquetes no están fragmentados correctamente, compruebe la configuración del umbral de fragmentación. Los paquetes menores que el umbral de fragmentación especificado no se fragmentan.Verifique la encapsulación del paquete. Para averiguar si un paquete se trata como un paquete LFI o no LFI, determine su tipo de encapsulación. Los paquetes LFI están encapsulados PPP y los paquetes que no son LFI se encapsulan con PPP y MLPPP. Las encapsulaciones PPP y MLPPP tienen diferentes sobrecargas, lo que resulta en paquetes de diferentes tamaños. Puede comparar tamaños de paquetes para determinar el tipo de encapsulación.
Un pequeño paquete de datos no fragmentado contiene un encabezado PPP y un solo encabezado MLPPP. En un paquete de datos fragmentado de gran tamaño, el primer fragmento contiene un encabezado PPP y un encabezado MLPPP, pero los fragmentos consecutivos contienen solo un encabezado MLPPP.
Las encapsulaciones PPP y MLPPP agregan el siguiente número de bytes a un paquete:
La encapsulación PPP agrega 7 bytes:
4 bytes de encabezado + 2 bytes de secuencia de comprobación de tramas (FCS) + 1 byte que está inactivo o contiene una marca
La encapsulación MLPPP agrega entre 6 y 8 bytes:
4 bytes de encabezado PPP+2 a 4 bytes de encabezado multivínculo
Figura 1 muestra la sobrecarga agregada a los encabezados PPP y MLPPP.
Figura 1: Encabezados PPP y MLPPP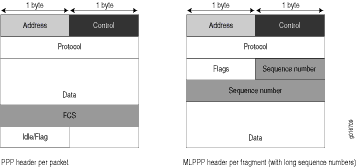
Para los paquetes CRTP, la sobrecarga de encapsulación y el tamaño del paquete son incluso menores que para un paquete LFI. Para obtener más información, consulte Ejemplo: Configuración del protocolo de transporte comprimido en tiempo real.
Tabla 6 muestra la sobrecarga de encapsulación de un paquete de datos y un paquete de voz de 70 bytes cada uno. Después de la encapsulación, el tamaño del paquete de datos es mayor que el tamaño del paquete de voz.
Tabla 6: Sobrecarga de encapsulación PPP y MLPPP Tipo de paquete
Encapsulación
Tamaño inicial del paquete
Sobrecarga de encapsulación
Tamaño del paquete después de la encapsulación
Paquete de voz (LFI)
PPP
70 bytes
4 + 2 + 1 = 7 bytes
77 bytes
Fragmento de datos (no LFI) con secuencia corta
MLPPP
70 bytes
4 + 2 + 1 + 4 + 2 = 13 bytes
83 bytes
Fragmento de datos (no LFI) con secuencia larga
MLPPP
70 bytes
4 + 2 + 1 + 4 + 4 = 15 bytes
85 bytes
Desde el modo operativo, escriba el
show interfaces queuecomando para mostrar el tamaño del paquete transmitido en cada cola. Divida el número de bytes transmitidos por el número de paquetes para obtener el tamaño de los paquetes y determinar el tipo de encapsulación.Verifique el equilibrio de carga. Desde el modo operativo, introduzca el
show interfaces queuecomando en el paquete multivínculo y sus enlaces constituyentes para confirmar si el equilibrio de carga se realiza en consecuencia en los paquetes.user@R0> show interfaces queue lsq-0/0/0 Physical interface: lsq-0/0/0, Enabled, Physical link is Up Interface index: 136, SNMP ifIndex: 29 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 600 0 pps Bytes : 44800 0 bps Transmitted: Packets : 600 0 pps Bytes : 44800 0 bps Tail-dropped packets : 0 0 pps RED-dropped packets : 0 0 pps … Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 400 0 pps Bytes : 61344 0 bps Transmitted: Packets : 400 0 pps Bytes : 61344 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 0 0 pps Bytes : 0 0 bps …user@R0> show interfaces queue se-1/0/0 Physical interface: se-1/0/0, Enabled, Physical link is Up Interface index: 141, SNMP ifIndex: 35 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 350 0 pps Bytes : 24350 0 bps Transmitted: Packets : 350 0 pps Bytes : 24350 0 bps ... Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 100 0 pps Bytes : 15272 0 bps Transmitted: Packets : 100 0 pps Bytes : 15272 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 19 0 pps Bytes : 247 0 bps Transmitted: Packets : 19 0 pps Bytes : 247 0 bps …user@R0> show interfaces queue se-1/0/1 Physical interface: se-1/0/1, Enabled, Physical link is Up Interface index: 142, SNMP ifIndex: 38 Forwarding classes: 8 supported, 8 in use Egress queues: 8 supported, 8 in use Queue: 0, Forwarding classes: DATA Queued: Packets : 350 0 pps Bytes : 24350 0 bps Transmitted: Packets : 350 0 pps Bytes : 24350 0 bps … Queue: 1, Forwarding classes: expedited-forwarding Queued: Packets : 0 0 pps Bytes : 0 0 bps … Queue: 2, Forwarding classes: VOICE Queued: Packets : 300 0 pps Bytes : 45672 0 bps Transmitted: Packets : 300 0 pps Bytes : 45672 0 bps … Queue: 3, Forwarding classes: NC Queued: Packets : 18 0 pps Bytes : 234 0 bps Transmitted: Packets : 18 0 pps Bytes : 234 0 bpsMeaning: el resultado de estos comandos muestra los paquetes transmitidos y en cola en cada cola de la interfaz de servicios de vínculo y sus vínculos constituyentes. Tabla 7 muestra un resumen de estos valores. (Dado que el número de paquetes transmitidos es igual al número de paquetes en cola en todos los vínculos, esta tabla muestra sólo los paquetes en cola).Tabla 7: Número de paquetes transmitidos en una cola Paquetes en cola
Paquete lsq-0/0/0.0
Enlace constituyente se-1/0/0
Enlace constituyente se-1/0/1
Explicación
Paquetes en Q0
600
350
350
El número total de paquetes que transitan por los vínculos constituyentes (350+350 = 700) superó el número de paquetes en cola (600) en el paquete multivínculo.
Paquetes en Q2
400
100
300
El número total de paquetes que transitan por los vínculos constituyentes es igual al número de paquetes del paquete.
Paquetes en Q3
0
19
18
Los paquetes que transitan Q3 de los enlaces constituyentes son para mensajes keepalive intercambiados entre enlaces constituyentes. Por lo tanto, no se contaron paquetes en Q3 del paquete.
En el paquete multivínculo, compruebe lo siguiente:
El número de paquetes en cola coincide con el número transmitido. Si los números coinciden, no se descartó ningún paquete. Si se ponían en cola más paquetes de los que se transmitían, los paquetes se descartaban porque el búfer era demasiado pequeño. El tamaño del búfer en los vínculos constituyentes controla la congestión en la etapa de salida. Para corregir este problema, aumente el tamaño del búfer en los vínculos constituyentes.
El número de paquetes que transitan Q0 (600) coincide con el número de paquetes de datos grandes y pequeños recibidos (100+500) en el paquete multivínculo. Si los números coinciden, todos los paquetes de datos transitaron correctamente Q0.
El número de paquetes que transitan Q2 en el paquete multivínculo (400) coincide con el número de paquetes de voz recibidos en el paquete multivínculo. Si los números coinciden, todos los paquetes LFI de voz transitaron correctamente Q2.
En los vínculos constituyentes, compruebe lo siguiente:
El número total de paquetes que transitan Q0 (350+350) coincide con el número de paquetes de datos y fragmentos de datos (500+200). Si los números coinciden, todos los paquetes de datos después de la fragmentación transitaron correctamente Q0 de los enlaces constituyentes.
Los paquetes transitaron por ambos enlaces constituyentes, lo que indica que el equilibrio de carga se realizó correctamente en paquetes que no eran LFI.
El número total de paquetes que transitan Q2 (300+100) en los enlaces constituyentes coincide con el número de paquetes de voz recibidos (400) en el paquete multivínculo. Si los números coinciden, todos los paquetes LFI de voz transitaron correctamente Q2.
Paquetes LFI desde el puerto
100de origen transitadosse-1/0/0y paquetes LFI desde el puerto200de origen transitadosse-1/0/1. Por lo tanto, todos los paquetes LFI (Q2) se cifraron en función del puerto de origen y transitaron correctamente ambos enlaces constituyentes.
Corrective Action: si los paquetes transitaron solo un vínculo, siga estos pasos para resolver el problema:Determine si el vínculo físico está
up(operativo) odown(no disponible). Un vínculo no disponible indica un problema con el PIM, el puerto de interfaz o la conexión física (errores de capa de enlace). Si el vínculo está operativo, vaya al paso siguiente.Compruebe que los clasificadores estén definidos correctamente para los paquetes que no son LFI. Asegúrese de que los paquetes que no sean LFI no estén configurados para ponerse en cola en Q2. Todos los paquetes en cola para Q2 se tratan como paquetes LFI.
Compruebe que al menos uno de los siguientes valores es diferente en los paquetes LFI: dirección de origen, dirección de destino, protocolo IP, puerto de origen o puerto de destino. Si se configuran los mismos valores para todos los paquetes LFI, todos los paquetes se cifran al mismo flujo y transitan por el mismo vínculo.
Utilice los resultados para verificar el equilibrio de carga.
Determinar por qué se dejan caer paquetes en un PVC entre un dispositivo de Juniper Networks y un dispositivo de terceros
Problema
Description
Está configurando un circuito virtual permanente (PVC) entre interfaces T1, E1, T3 o E3 en un dispositivo de Juniper Networks y un dispositivo de terceros, y los paquetes se descartan y se produce un error en el ping.
Solución
Si el dispositivo de terceros no tiene la misma compatibilidad con FRF.12 que el dispositivo de Juniper Networks o admite FRF.12 de otra manera, la interfaz del dispositivo de Juniper Networks en el PVC podría descartar un paquete fragmentado que contenga encabezados FRF.12 y contarlo como un "descarte vigilado".
Como solución alternativa, configure paquetes multivínculo en ambos pares y configure umbrales de fragmentación en los paquetes multivínculo.
Solucionar problemas de las políticas de seguridad
- Sincronizar políticas entre el motor de enrutamiento y el motor de reenvío de paquetes
- Comprobar un error de confirmación de política de seguridad
- Verificar una confirmación de política de seguridad
- Búsqueda de directivas de depuración
Sincronizar políticas entre el motor de enrutamiento y el motor de reenvío de paquetes
Problema
Description
Las políticas de seguridad se almacenan en el motor de enrutamiento y en el motor de reenvío de paquetes. Las políticas de seguridad se insertan desde el motor de enrutamiento al motor de reenvío de paquetes cuando se confirman las configuraciones. Si las políticas de seguridad del motor de enrutamiento no están sincronizadas con el motor de reenvío de paquetes, se produce un error en la confirmación de una configuración. Se pueden generar archivos de volcado de núcleo si se intenta la confirmación repetidamente. La falta de sincronización puede deberse a:
Un mensaje de política del motor de enrutamiento al motor de reenvío de paquetes se pierde en tránsito.
Un error con el motor de enrutamiento, como un UID de directiva reutilizado.
Entorno
Las directivas del motor de enrutamiento y del motor de reenvío de paquetes deben estar sincronizadas para que se confirme la configuración. Sin embargo, en determinadas circunstancias, es posible que las directivas del motor de enrutamiento y del motor de reenvío de paquetes no estén sincronizadas, lo que provoca un error en la confirmación.
Síntomas
Cuando se modifican las configuraciones de directiva y las directivas no están sincronizadas, aparece el siguiente mensaje de error: error: Warning: policy might be out of sync between RE and PFE <SPU-name(s)> Please request security policies check/resync.
Solución
Use el show security policies checksum comando para mostrar el valor de suma de comprobación de la directiva de seguridad y use el request security policies resync comando para sincronizar la configuración de las directivas de seguridad en el motor de enrutamiento y el motor de reenvío de paquetes, si las directivas de seguridad no están sincronizadas.
Comprobar un error de confirmación de política de seguridad
Problema
Description
La mayoría de los errores de configuración de directivas se producen durante una confirmación o un tiempo de ejecución.
Los errores de confirmación se notifican directamente en la CLI cuando se ejecuta el comando commit-check de la CLI en modo de configuración. Estos errores son errores de configuración y no puede confirmar la configuración sin corregirlos.
Solución
Para corregir estos errores, haga lo siguiente:
Revise los datos de configuración.
Abra el archivo /var/log/nsd_chk_only. Este archivo se sobrescribe cada vez que se realiza una comprobación de confirmación y contiene información detallada sobre el error.
Verificar una confirmación de política de seguridad
Problema
Description
Al realizar una confirmación de configuración de directiva, si observa que el comportamiento del sistema es incorrecto, siga estos pasos para solucionar este problema:
Solución
Comandos operativos show : ejecute los comandos operativos para las políticas de seguridad y compruebe que la información que se muestra en el resultado es coherente con lo que esperaba. De lo contrario, la configuración debe cambiarse adecuadamente.
Traceoptions: defina el comando en la configuración de
traceoptionsla política. Los indicadores bajo esta jerarquía se pueden seleccionar según el análisis del usuario de la salida delshowcomando. Si no puede determinar qué indicador usar, la opciónallde indicador se puede usar para capturar todos los registros de seguimiento.user@host#
set security policies traceoptions <flag all>
También puede configurar un nombre de archivo opcional para capturar los registros.
user@host# set security policies traceoptions <filename>
Si especificó un nombre de archivo en las opciones de seguimiento, puede buscar el archivo de registro en /var/log/<filename> para determinar si se ha notificado algún error en el archivo. (Si no especificó un nombre de archivo, el nombre de archivo predeterminado es eventual). Los mensajes de error indican el lugar del error y la razón apropiada.
Después de configurar las opciones de seguimiento, debe volver a confirmar el cambio de configuración que provocó el comportamiento incorrecto del sistema.
Búsqueda de directivas de depuración
Problema
Description
Si tiene la configuración correcta, pero parte del tráfico se ha interrumpido o permitido incorrectamente, puede habilitar el lookup indicador en las traceoptions de las políticas de seguridad. La lookup marca registra los seguimientos relacionados con la búsqueda en el archivo de seguimiento.
Solución
user@host# set security policies traceoptions <flag lookup>
Tabla de historial de cambios
La compatibilidad de la función depende de la plataforma y la versión que utilice. Utilice Feature Explorer a fin de determinar si una función es compatible con la plataforma.