ON THIS PAGE
Example: Summarizing Ranges of Routes in OSPF Link-State Advertisements Sent into the Backbone Area
Example: Controlling the Cost of Individual OSPF Network Segments
Understanding Weighted ECMP Traffic Distribution on One-Hop OSPFv2 Neighbors
Example: Weighted ECMP Traffic Distribution on One-Hop OSPFv2 Neighbors
Example: Dynamically Adjusting OSPF Interface Metrics Based on Bandwidth
Example: Configuring OSPF to Make Routing Devices Appear Overloaded
Configuring OSPF Refresh and Flooding Reduction in Stable Topologies
Configuring OSPF Route Control
Understanding OSPF Route Summarization
Area border routers (ABRs) send summary link advertisements to describe the routes to other areas. Depending on the number of destinations, an area can get flooded with a large number of link-state records, which can utilize routing device resources. To minimize the number of advertisements that are flooded into an area, you can configure the ABR to coalesce, or summarize, a range of IP addresses and send reachability information about these addresses in a single link-state advertisement (LSA). You can summarize one or more ranges of IP addresses, where all routes that match the specified area range are filtered at the area boundary, and the summary is advertised in their place.
For an OSPF area, you can summarize and filter intra-area prefixes. All routes that match the specified area range are filtered at the area boundary, and the summary is advertised in their place. For an OSPF not-so-stubby area (NSSA), you can only coalesce or filter NSSA external (Type 7) LSAs before they are translated into AS external (Type 5) LSAs and enter the backbone area. All external routes learned within the area that do not fall into the range of one of the prefixes are advertised individually to other areas.
In addition, you can also limit the number of prefixes (routes) that are exported into OSPF. By setting a user-defined maximum number of prefixes, you prevent the routing device from flooding an excessive number of routes into an area.
Example: Summarizing Ranges of Routes in OSPF Link-State Advertisements Sent into the Backbone Area
This example shows how to summarize routes sent into the backbone area.
Requirements
Before you begin:
Configure the router identifiers for the devices in your OSPF network. See Example: Configuring an OSPF Router Identifier.
Control OSPF designated router election. See Example: Controlling OSPF Designated Router Election
Configure a static route. See Examples: Configuring Static Routes in the Junos OS Routing Protocols Library for Routing Devices.
Overview
You can summarize a range of IP addresses to minimize the size of the backbone router’s link-state database. All routes that match the specified area range are filtered at the area boundary, and the summary is advertised in their place.
Figure 1 shows the topology used in this example. R5 is the ABR between area 0.0.0.4 and the backbone. The networks in area 0.0.0.4 are 10.0.8.4/30, 10.0.8.0/30, and 10.0.8.8/30, which can be summarized as 10.0.8.0/28. R3 is the ABR between NSSA area 0.0.0.3 and the backbone. The networks in area 0.0.0.3 are 10.0.4.4/30, 10.0.4.0/30, and 10.0.4.12/30, which can be summarized as 10.0.4.0/28. Area 0.0.0.3 also contains external static route 3.0.0.8, which will be flooded throughout the network.
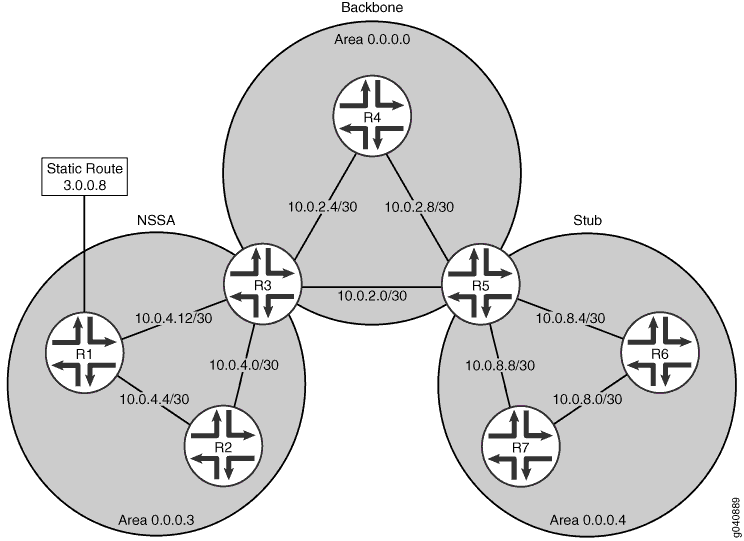
In this example, you configure the ABRs for route summarization by including the following settings:
area-range—For an area, summarizes a range of IP addresses when sending summary intra-area link advertisements. For an NSSA, summarizes a range of IP addresses when sending NSSA link-state advertisements (Type 7 LSAs). The specified prefixes are used to aggregate external routes learned within the area when the routes are advertised to other areas.
network/mask-length—Indicates the summarized IP address range and the number of significant bits in the network mask.
Topology
Configuration
CLI Quick Configuration
To quickly configure route summarization for an OSPF area, copy the following commands and paste them into the CLI. The following is the configuration on ABR R5:
[edit] set interfaces fe-0/0/1 unit 0 family inet address 10.0.8.3/30 set interfaces fe-0/0/2 unit 0 family inet address 10.0.8.4/30 set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.3/30 set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.5/30 set protocols ospf area 0.0.0.4 stub set protocols ospf area 0.0.0.4 interface fe-0/0/1 set protocols ospf area 0.0.0.4 interface fe-0/0/2 set protocols ospf area 0.0.0.0 interface fe-0/0/0 set protocols ospf area 0.0.0.0 interface fe-0/0/4 set protocols ospf area 0.0.0.4 area-range 10.0.8.0/28
To quickly configure route summarization for an OSPF NSSA, copy the following commands and paste them into the CLI. The following is the configuration on ABR R3:
[edit] set interfaces fe-0/0/1 unit 0 family inet address 10.0.4.10/30 set interfaces fe-0/0/2 unit 0 family inet address 10.0.4.1/30 set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.1/30 set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.7/30 set protocols ospf area 0.0.0.3 interface fe-0/0/1 set protocols ospf area 0.0.0.3 interface fe-0/0/2 set protocols ospf area 0.0.0.0 interface fe-0/0/0 set protocols ospf area 0.0.0.0 interface fe-0/0/4 set protocols ospf area 0.0.0.3 area-range 10.0.4.0/28 set protocols ospf area 0.0.0.3 nssa set protocols ospf area 0.0.0.3 nssa area-range 3.0.0.0/8
Procedure
Step-by-Step Procedure
To summarize routes sent to the backbone area:
Configure the interfaces.
Note:For OSPFv3, include IPv6 addresses.
[edit] user@R5#
set interfaces fe-0/0/1 unit 0 family inet address 10.0.8.3/30user@R5#set interfaces fe-0/0/2 unit 0 family inet address 10.0.8.4/30user@R5#set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.3/30user@R5#set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.5/30[edit] user@R3#
set interfaces fe-0/0/1 unit 0 family inet address 10.0.4.10/30user@R3#set interfaces fe-0/0/2 unit 0 family inet address 10.0.4.1/30user@R3#set interfaces fe-0/0/0 unit 0 family inet address 10.0.2.1/30user@R3#set interfaces fe-0/0/4 unit 0 family inet address 10.0.2.7/30Configure the type of OSPF area.
Note:For OSPFv3, include the
ospf3statement at the[edit protocols]hierarchy level.[edit] user@R5# set protocols ospf area 0.0.0.4 stub
[edit] user@R3# set protocols ospf area 0.0.0.3 nssa
Assign the interfaces to the OSPF areas.
user@R5#
set protocols ospf area 0.0.0.4 interface fe-0/0/1user@R5#set protocols ospf area 0.0.0.4 interface fe-0/0/2user@R5#set protocols ospf area 0.0.0.0 interface fe-0/0/0user@R5#set protocols ospf area 0.0.0.0 interface fe-0/0/4user@R3#
set protocols ospf area 0.0.0.3 interface fe-0/0/1user@R3#set protocols ospf area 0.0.0.3 interface fe-0/0/2user@R3#set protocols ospf area 0.0.0.0 interface fe-0/0/0user@R3#set protocols ospf area 0.0.0.0 interface fe-0/0/4Summarize the routes that are flooded into the backbone.
[edit] user@R5# set protocols ospf area 0.0.0.4 area-range 10.0.8.0/28
[edit] user@R3# set protocols ospf area 0.0.0.3 area-range 10.0.4.0/28
On ABR R3, restrict the external static route from leaving area 0.0.0.3.
[edit] user@R3# set protocols ospf area 0.0.0.3 nssa area-range 3.0.0.0/8
If you are done configuring the devices, commit the configuration.
[edit] user@host# commit
Results
Confirm your configuration by entering the show
interfaces and the show protocols ospf commands.
If the output does not display the intended configuration, repeat
the instructions in this example to correct the configuration.
Configuration on ABR R5:
user@R5# show interfaces
fe-0/0/0 {
unit 0 {
family inet {
address 10.0.2.3/32;
}
}
}
fe-0/0/1 {
unit 0 {
family inet {
address 10.0.8.3/32;
}
}
}
fe-0/0/2 {
unit 0 {
family inet {
address 10.0.8.4/32;
}
}
}
fe-0/0/4 {
unit 0 {
family inet {
address 10.0.2.5/32;
}
}
}
user@R5# show protocols ospf
area 0.0.0.0 {
interface fe-0/0/0.0;
interface fe-0/0/4.0;
}
area 0.0.0.4 {
stub;
area-range 10.0.8.0/28;
interface fe-0/0/1.0;
interface fe-0/0/2.0;
}
Configuration on ABR R3:
user@R3# show interfaces
fe-0/0/0 {
unit 0 {
family inet {
address 10.0.2.1/32;
}
}
}
fe-0/0/1 {
unit 0 {
family inet {
address 10.0.4.10/32;
}
}
}
fe-0/0/2 {
unit 0 {
family inet {
address 10.0.4.1/32;
}
}
}
fe-0/0/4 {
unit 0 {
family inet {
address 10.0.2.7/32;
}
}
}
user@R3t# show protocols ospf
area 0.0.0.0 {
interface fe-0/0/0.0;
interface fe-0/0/4.0;
}
area 0.0.0.3 {
nssa {
area-range 3.0.0.0/8 ;
}
area-range 10.0.4.0/28;
interface fe-0/0/1.0;
interface fe-0/0/2.0;
}
To confirm your OSPFv3 configuration, enter the show interfaces and show protocols ospf3 commands.
Verification
Confirm that the configuration is working properly.
Verifying the Summarized Route
Purpose
Verify that the routes you configured for route summarization are being aggregated by the ABRs before the routes enter the backbone area. Confirm route summarization by checking the entries of the OSPF link-state database for the routing devices in the backbone.
Action
From operational mode, enter the show ospf database command for OSPFv2, and enter the show ospf3 database command for OSPFv3.
Example: Limiting the Number of Prefixes Exported to OSPF
This example shows how to limit the number of prefixes exported to OSPF.
Requirements
Before you begin:
Configure the device interfaces. See the Junos OS Network Interfaces Library for Routing Devices.
Configure the router identifiers for the devices in your OSPF network. See Example: Configuring an OSPF Router Identifier.
Control OSPF designated router election. See Example: Controlling OSPF Designated Router Election
Configure a single-area OSPF network. See Example: Configuring a Single-Area OSPF Network.
Configure a multiarea OSPF network. See Example: Configuring a Multiarea OSPF Network.
Overview
By default, there is no limit to the number of prefixes (routes) that can be exported into OSPF. By allowing any number of routes to be exported into OSPF, the routing device can become overwhelmed and potentially flood an excessive number of routes into an area.
You can limit the number of routes exported into OSPF to minimize the load on the routing device and prevent this potential problem. If the routing device exceeds the configured prefix export value, the routing device purges the external prefixes and enters into an overload state. This state ensures that the routing device is not overwhelmed as it attempts to process routing information. The prefix export limit number can be a value from 0 through 4,294,967,295.
In this example, you configure a prefix export limit of 100,000
by including the prefix-export-limit statement.
Topology
Configuration
CLI Quick Configuration
To quickly limit the number of prefixes exported
to OSPF, copy the following commands, paste them into a text file,
remove any line breaks, change any details necessary to match your
network configuration, copy and paste the commands into the CLI at
the [edit] hierarchy level, and then enter commit from
configuration mode.
[edit] set protocols ospf prefix-export-limit 100000
Procedure
Step-by-Step Procedure
To limit the number of prefixes exported to OSPF:
Configure the prefix export limit value.
Note:For OSPFv3, include the
ospf3statement at the[edit protocols]hierarchy level.[edit] user@host# set protocols ospf prefix-export-limit 100000
If you are done configuring the device, commit the configuration.
[edit] user@host# commit
Results
Confirm your configuration by entering the show
protocols ospf command. If the output does not display the intended
configuration, repeat the instructions in this example to correct
the configuration.
user@host# show protocols ospf prefix-export-limit 100000;
To confirm your OSPFv3 configuration, enter the show protocols
ospf3 command.
Verification
Confirm that the configuration is working properly.
Understanding OSPF Traffic Control
Once a topology is shared across the network, OSPF uses the topology to route packets
between network nodes. Each path between neighbors is assigned a cost based
on
interface throughput.
The default
algorithm computes the interface metric based on a reference bandwidth of 100 Mbps using
the formula cost = reference-bandwidth / interface bandwidth. The
result is any interface operating at 100 Mbps or faster is assigned the same metric
value of 1. You can manually assign the OSPF interface metric to override the default
value. Alternatively, given current Juniper platforms support interfaces that operate
at 400 Gbps, its often a good idea to configure a larger
reference-bandwidth value. Configuring a reference bandwidth value
that is based on a multiple of the highest speed interface in your network automatically
optimizes network paths based on interface speed and provides room for growth in network
speeds.
The sum of the costs across a particular path between hosts determines the overall cost of the path. Packets are then routed along the shortest path using the shortest-path-first (SPF) algorithm. If multiple equal-cost paths exist between a source and destination address, OSPF routes packets along each path alternately, in round-robin fashion. Routes with lower total path metrics are preferred over those with higher path metrics.
You can use the following methods to control OSPF traffic:
-
Control the cost of individual OSPF network segments
-
Dynamically adjust OSPF interface metrics based on bandwidth
-
Control OSPF route selection
- Controlling the Cost of Individual OSPF Network Segments
- Dynamically Adjusting OSPF Interface Metrics Based on Bandwidth
- Controlling OSPF Route Preferences
Controlling the Cost of Individual OSPF Network Segments
OSPF uses the following formula to determine the cost of a route:
cost = reference-bandwidth / interface bandwidth
You can modify the reference-bandwidth value, which is used to calculate the default interface cost. The interface bandwidth value is not user-configurable and refers to the actual bandwidth of the physical interface.
By default, OSPF assigns a default cost metric of 1 to any link faster than 100 Mbps, and a default cost metric of 0 to the loopback interface (lo0). No bandwidth is associated with the loopback interface.
To control the flow of packets across the network, OSPF allows you to manually assign a cost (or metric) to a particular path segment. When you specify a metric for a specific OSPF interface, that value is used to determine the cost of routes advertised from that interface. For example, if all routers in the OSPF network use default metric values, and you increase the metric on one interface to 5, all paths through that interface have a calculated metric higher than the default and are not preferred.
Any value you configure for the metric overrides the default behavior of using the reference-bandwidth value to calculate the route cost for that interface.
When there are multiple equal-cost routes to the same destination in a routing table, an equal-cost multipath (ECMP) set is formed. If there is an ECMP set for the active route, the Junos OS software uses a hash algorithm to choose one of the next-hop addresses in the ECMP set to install in the forwarding table.
You can configure Junos OS so that multiple next-hop entries in an ECMP set are installed in the forwarding table. Define a load-balancing routing policy by including one or more policy-statement configuration statements at the [edit policy-options] hierarchy level, with the action load-balance per-packet. Then apply the routing policy to routes exported from the routing table to the forwarding table.
Dynamically Adjusting OSPF Interface Metrics Based on Bandwidth
You can specify a set of bandwidth threshold values and associated metric values for an OSPF interface or for a topology on an OSPF interface. When the bandwidth of an interface changes (for example, if the lag loses an interface member or if the interface speed is administratively changed), Junos OS automatically sets the interface metric to the value associated with the appropriate bandwidth threshold value. Junos OS uses the smallest configured bandwidth threshold value that is equal to or greater than the actual interface bandwidth to determine the metric value. If the interface bandwidth is greater than any of the configured bandwidth threshold values, the metric value configured for the interface is used instead of any of the bandwidth-based metric values configured. The ability to recalculate the metric for an interface when its bandwidth changes is especially useful for aggregate interfaces.
You must also configure a metric for the interface when you enable bandwidth-based metrics.
Controlling OSPF Route Preferences
You can control the flow of packets through the network using route preferences. Route preferences are used to select which route is installed in the forwarding table when several protocols calculate routes to the same destination. The route with the lowest preference value is selected.
By default, internal OSPF routes have a preference value of 10, and external OSPF routes have a preference value of 150. Although the default settings are appropriate for most environments, you might want to modify the default settings if all of the routing devices in your OSPF network use the default preference values, or if you are planning to migrate from OSPF to a different interior gateway protocol (IGP). If all of the devices use the default route preference values, you can change the route preferences to ensure that the path through a particular device is selected for the forwarding table any time multiple equal-cost paths to a destination exist. When migrating from OSPF to a different IGP, modifying the route preferences allows you to perform the migration in a controlled manner.
See Also
Example: Controlling the Cost of Individual OSPF Network Segments
This example shows how to control the cost of individual OSPF network segments.
Requirements
Before you begin:
Configure the device interfaces. See the Interfaces User Guide for Security Devices.
Configure the router identifiers for the devices in your OSPF network. See Example: Configuring an OSPF Router Identifier.
Control OSPF designated router election. See Example: Controlling OSPF Designated Router Election
Configure a single-area OSPF network. See Example: Configuring a Single-Area OSPF Network.
Overview
All OSPF interfaces have a cost, which is a routing metric that is used in the link-state calculation. Routes with lower total path metrics are preferred to those with higher path metrics. In this example, we explore how to control the cost of OSPF network segments.
By default, OSPF assigns a default cost metric of 1 to any link faster than 100 Mbps, and a default cost metric of 0 to the loopback interface (lo0). No bandwidth is associated with the loopback interface. This means that all interfaces faster than 100 Mbps have the same default cost metric of 1. If multiple equal-cost paths exist between a source and destination address, OSPF routes packets along each path alternately, in round-robin fashion.
Having the same default metric might not be a problem if all of the interfaces are running at the same speed. If the interfaces operate at different speeds, you might notice that traffic is not routed over the fastest interface because OSPF equally routes packets across the different interfaces. For example, if your routing device has Fast Ethernet and Gigabit Ethernet interfaces running OSPF, each of these interfaces have a default cost metric of 1.
In the first example, you set the reference bandwidth to 10g (10 Gbps, as denoted by 10,000,000,000 bits) by including the reference-bandwidth statement. With this configuration, OSPF assigns the Fast Ethernet interface a default metric of 100, and the Gigabit Ethernet interface a metric of 10. Since the Gigabit Ethernet interface has the lowest metric, OSPF selects it when routing packets. The range is 9600 through 1,000,000,000,000 bits.
Figure 2 shows three routing devices in area 0.0.0.0 and assumes that the link between Device R2 and Device R3 is congested with other traffic. You can also control the flow of packets across the network by manually assigning a metric to a particular path segment. Any value you configure for the metric overrides the default behavior of using the reference-bandwidth value to calculate the route cost for that interface. To prevent the traffic from Device R3 going directly to Device R2, you adjust the metric on the interface on Device R3 that connects with Device R1 so that all traffic goes through Device R1.
In the second example, you set the metric to 5 on interface fe-1/0/1 on Device R3 that connects with Device R1 by including the metric statement. The range is 1 through 65,535.
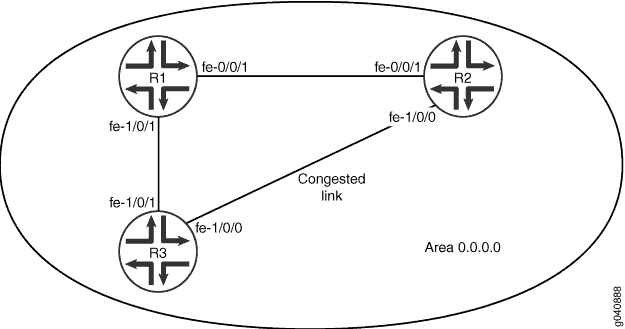
Topology
Configuration
Configuring the Reference Bandwidth
CLI Quick Configuration
To quickly configure the reference bandwidth,
copy the following commands, paste them into a text file, remove any
line breaks, change any details necessary to match your network configuration,
copy and paste the commands into the CLI at the [edit] hierarchy level,
and then enter commit from configuration mode.
[edit] set protocols ospf reference-bandwidth 10g
Step-by-Step Procedure
To configure the reference bandwidth:
Configure the reference bandwidth to calculate the default interface cost.
Note:To specify OSPFv3, include the ospf3 statement at the [edit protocols] hierarchy level.
[edit] user@host# set protocols ospf reference-bandwidth 10g
Tip:As a shortcut in this example, you enter 10g to specify 10 Gbps reference bandwidth. Whether you enter 10g or 10000000000, the output of show protocols ospf command displays 10 Gbps as 10g, not 10000000000.
If you are done configuring the device, commit the configuration.
[edit] user@host# commit
Note:Repeat this entire configuration on all routing devices in a shared network.
Results
Confirm your configuration by entering the show protocols ospf command. If the output does not display the intended configuration, repeat the instructions in this example to correct the configuration.
user@host# show protocols ospf reference-bandwidth 10g;
To confirm your OSPFv3 configuration, enter the show protocols ospf3 command.
Configuring a Metric for a Specific OSPF Interface
CLI Quick Configuration
To quickly configure a metric for a specific
OSPF interface, copy the following commands, paste them into a text
file, remove any line breaks, change any details necessary to match
your network configuration, copy and paste the commands into the CLI
at the [edit] hierarchy level, and then enter commit from
configuration mode.
[edit] set protocols ospf area 0.0.0.0 interface fe-1/0/1 metric 5
Step-by-Step Procedure
To configure the metric for a specific OSPF interface:
Create an OSPF area.
Note:To specify OSPFv3, include the ospf3 statement at the [edit protocols] hierarchy level.
[edit] user@host# edit protocols ospf area 0.0.0.0
Configure the metric of the OSPF network segment.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface fe-1/0/1 metric 5
If you are done configuring the device, commit the configuration.
[edit protocols ospf area 0.0.0.0 ] user@host# commit
Results
Confirm your configuration by entering the show protocols ospf command. If the output does not display the intended configuration, repeat the instructions in this example to correct the configuration.
user@host# show protocols ospf
area 0.0.0.0 {
interface fe-1/0/1.0 {
metric 5;
}
}
To confirm your OSPFv3 configuration, enter the show protocols ospf3 command.
Verification
Confirm that the configuration is working properly.
Verifying the Configured Metric
Purpose
Verify the metric setting on the interface. Confirm that the Cost field displays the interface’s configured metric (cost). When choosing paths to a destination, OSPF uses the path with the lowest cost.
Action
From operational mode, enter the show ospf interface detail command for OSPFv2, and enter the show ospf3 interface detail command for OSPFv3.
Understanding Weighted ECMP Traffic Distribution on One-Hop OSPFv2 Neighbors
Equal-cost multipath (ECMP) is a popular technique to load balance traffic across multiple paths. With ECMP enabled, if paths to a remote destination have the same cost, then traffic is distributed between them in equal proportion. Equal distribution of traffic across multiple paths is not desirable if the local links to adjacent routers towards the ultimate destination have unequal capacity. Typically the traffic distribution between two links is equal and the link utilization is the same. However, if the capacity of an aggregated Ethernet bundle changes, equal traffic distribution results in imbalance of link utilization. In this case, weighted ECMP enables load balancing of traffic between equal cost paths in proportion to the capacity of the local links.
Taking as an example, there are two devices interconnected with an aggregated Ethernet bundle with four links and a single link of the same cost. Under normal conditions, both the AE bundles and the single link is utilized evenly to distribute traffic. However, if a link in the AE bundle goes down, there is a change in the link capacity that results in uneven link utilization. Weighted ECMP load balances traffic between the equal cost paths in proportion to the capacity of the local links. In this case, traffic is distributed in 30/40 proportion between the AE bundle and the single link.
This feature provides weighted ECMP routing to OSPFv2 neighbors that are one hop away. The operating system supports this feature on immediately connected routers only and does not support weighted ECMP on multihop routers, that is, on routers that are more than one hop away.
To enable weighted ECMP traffic distribution on directly connected OSPFv2 neighbors,
configure weighted one-hop statement at the [edit protocols ospf
spf-options multipath] hierarchy level.
You must configure per-packet load balancing policy before configuring this feature. WECMP will be operational if per-packet load balancing policy is in place.
For logical interfaces, you must configure interface bandwidth to distribute traffic across equal cost multipaths based on the underlying physical interface bandwidth. If you do not configure the logical bandwidth for each logical interface, the operating system assumes that the entire bandwidth of the physical interface is available for each logical interface.
Example: Weighted ECMP Traffic Distribution on One-Hop OSPFv2 Neighbors
Use this example to configure weighted equal cost multipath (ECMP) routing for distributing traffic to OSPFv2 neighbors that are one hop away to ensure optimal load balancing.
Our content testing team has validated and updated this example.
|
Reading Time |
30 minutes |
|
Configuration Time |
20 minutes |
- Example Prerequisites
- Before You Begin
- Functional Overview
- Topology Overview
- Topology Illustration
- R0 Configuration Steps
- Verification
- Appendix 1: Set Commands on All Devices
Example Prerequisites
|
Hardware requirements |
Two MX Series routers. |
|
Software requirements |
Junos OS Release 24.2R1 or later running on all devices. |
Before You Begin
|
Benefits |
Weighted ECMP routing distributes traffic unequally over multiple paths for better load balancing. It is more efficient than equal distribution of traffic during per-packet load balancing. |
|
Know more |
Understanding Weighted ECMP Traffic Distribution on One-Hop OSPF Neighbors |
Functional Overview
|
Technologies used |
|
|
Primary verification tasks |
|
Topology Overview
This configuration example depicts three aggregated Ethernet bundles ae0, ae1, and ae2 with two links each configured between Router R0 and Router R1. The Packet Forwarding Engine distributes traffic unequally between the three Ethernet bundles when one of the links goes down, depending on the available bandwidth.
|
Hostname |
Role |
Function |
|---|---|---|
|
R0 |
The device on which the WECMP is configured. |
R0 sends traffic to R1. |
|
R1 |
The device that is directly connected to R0. |
R1 receives traffic from R0. |
Topology Illustration
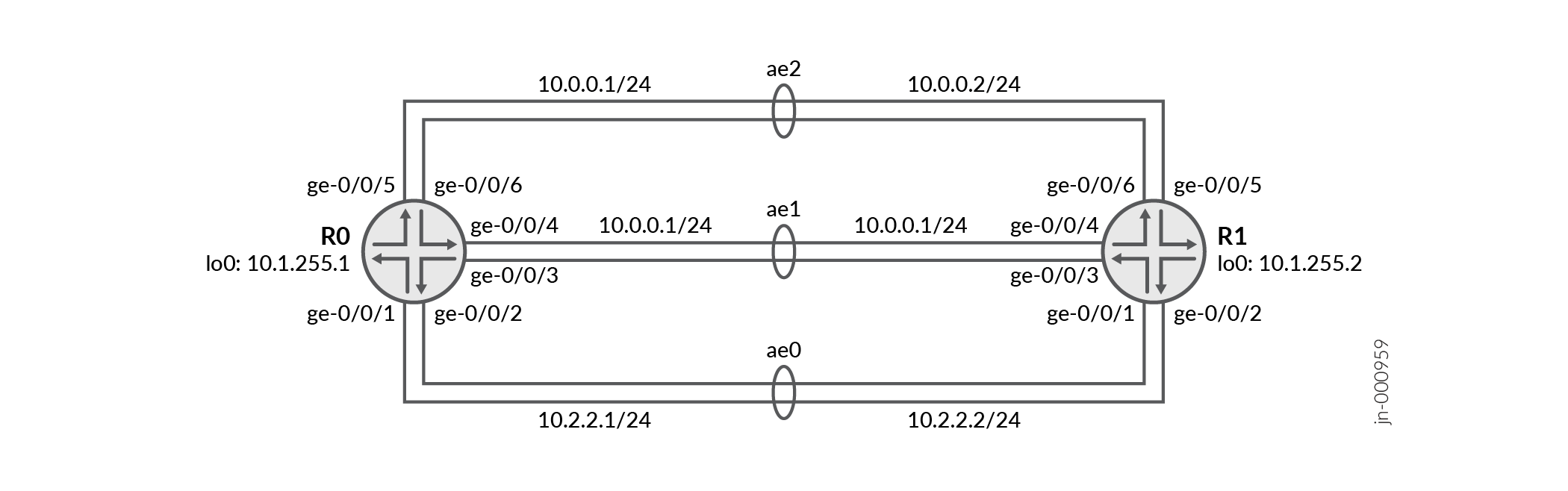
R0 Configuration Steps
For complete sample configurations on R0, see: Appendix 1: Set Commands on All Devices
This section highlights the main configuration tasks needed to configure the R0 device for this example. The first step is common to configuring the aggregated Ethernet interfaces. The following set of steps are specific to configuring OSPF on the AE bundles and configuring weighted ECMP.
-
Configure the two member links of the ae0, ae1, and ae2 aggregated Ethernet bundles.
Configure IP address and the Link Aggregation Control Protocol (LACP) for the ae0, ae1, and ae2 aggregated Ethernet interfaces.
Configure the aggregated Ethernet interfaces (ae0, ae1, and ae2) for vlan tagging.
Configure the loopback interface address.
Configure the OSPF router identifier by entering the [router-id] configuration value.
Configure logical interfaces with appropriate bandwidth based on the underlying physical bandwidth.
Note:For logical interfaces, configure interface bandwidth to distribute traffic across equal-cost multipaths based on the underlying operational interface bandwidth. When you configure multiple logical interfaces on a single interface, configure appropriate logical bandwidth for each logical interface to see the desired traffic distribution over the logical interfaces.
Configure a tunnel interface and specify the amount of bandwidth to reserve for tunnel traffic on each Packet Forwarding Engine of R0.
[edit] set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 gigether-options 802.3ad ae2
[edit] set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae2 aggregated-ether-options minimum-links 1 set interfaces ae2 aggregated-ether-options lacp active
[edit] set interfaces ae0 vlan-tagging set interfaces ae1 vlan-tagging set interfaces ae2 vlan-tagging
[edit] set interfaces lo0 unit 0 family inet address 10.1.255.1/32
[edit] set routing-options router-id 10.1.255.1
[edit] set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.1/24 set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.1/24 set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.1/24
Specify the maximum number of weighted ECMP interfaces that you want to configure. Enable graceful switchover and specify the number of aggregated Ethernet interfaces to be created.
[edit] set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3
Configure OSPF on all the interfaces and on the AE bundles.
[edit]set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0Configure per-packet load balancing.
[edit] set policy-options policy-statement pplb then load-balance per-packet
Apply per-packet load balancing policy.
[edit] set routing-options forwarding-table export ppl
Enable weighted ECMP traffic distribution on directly connected OSPFv2 neighbors.
[edit] set protocols ospf spf-options multipath weighted one-hop
Verification
| Command | Verification Task |
|---|---|
| show route extensive | Verify equal distribution of traffic over equal-cost multiple paths. |
| show route extensive | Verify unequal traffic distribution over available bandwidth. |
| show interfaces extensive | Verify unequal traffic distribution over available bandwidth. |
- Verifying Equal Distribution of Traffic Over Equal-Cost Multiple Paths
- Verifying Unequal Traffic Distribution Over Available Bandwidth
Verifying Equal Distribution of Traffic Over Equal-Cost Multiple Paths
Purpose
To verify that traffic is equally distributed over the aggregated Ethernet bundles.
Action
From operational mode, enter the show route 10.1.255.2
extensive command.
user@R0> show route 10.1.255.2 extensive
inet.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden)
10.1.255.2/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 10.1.255.2/32 -> {list:10.0.0.2, 10.0.1.2, 10.2.2.2}
*OSPF Preference: 10
Next hop type: Router, Next hop index: 0
Address: 0x819a814
Next-hop reference count: 2, Next-hop session id: 0
Kernel Table Id: 0
Next hop: 10.0.0.2 via ae0.0 weight 0x1 balance 33%
Session Id: 0
Next hop: 10.0.1.2 via ae1.0 weight 0x1 balance 33%, selected
Session Id: 0
Next hop: 10.2.2.2 via ae2.0 weight 0x1 balance 33%
Session Id: 0
State: <Active Int>
Age: 4d 17:55:37 Metric: 1
Validation State: unverified
Area: 0.0.0.0
Task: OSPF
Announcement bits (1): 0-KRT
AS path: I
Thread: junos-main
user@R0> show interfaces ae0.0 extensive
Logical interface ae0.0 (Index 337) (SNMP ifIndex 578) (Generation 173)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.6 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89241 0 7140674 0
Output: 89244 0 8731668 0
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/1.0
Input : 47583 0 3807058 0
Output: 0 0 0 0
ge-0/0/2.0
Input : 41632 0 3331512 0
Output: 89243 0 8731574 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/1.0 0 0 0 0
ge-0/0/2.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 177, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.0.0/24, Local: 10.0.0.1, Broadcast: 10.0.0.255, Generation: 157
Protocol multiservice, MTU: Unlimited, Generation: 178, Route table: 0
Flags: Is-Primary, 0x0
Policer: Input: __default_arp_policer__
user@R0> show interfaces ae1.0 extensive
Logical interface ae1.0 (Index 362) (SNMP ifIndex 593) (Generation 175)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.16 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89631 0 7194074 312
Output: 89626 1 8793864 784
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/3.0
Input : 89631 0 7194074 312
Output: 89626 0 8793864 0
ge-0/0/4.0
Input : 0 0 0 0
Output: 0 0 0 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/3.0 0 0 0 0
ge-0/0/4.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 180, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.0.1/24, Local: 10.0.1.1, Broadcast: 10.0.1.255, Generation: 159
Protocol multiservice, MTU: Unlimited, Generation: 181, Route table: 0
Flags: 0x0
Policer: Input: __default_arp_policer__
user@R0> show interfaces ae2.0 extensive
Logical interface ae2.0 (Index 364) (SNMP ifIndex 592) (Generation 177)
Flags: Up SNMP-Traps 0x4000 VLAN-Tag [ 0x8100.26 ] Encapsulation: ENET2
Statistics Packets pps Bytes bps
Bundle:
Input : 89612 0 7193002 0
Output: 89664 0 8797828 0
Adaptive Statistics:
Adaptive Adjusts: 0
Adaptive Scans : 0
Adaptive Updates: 0
Link:
ge-0/0/5.0
Input : 89612 0 7193002 0
Output: 89664 0 8797828 0
ge-0/0/6.0
Input : 0 0 0 0
Output: 0 0 0 0
Aggregate member links: 2
Marker Statistics: Marker Rx Resp Tx Unknown Rx Illegal Rx
ge-0/0/5.0 0 0 0 0
ge-0/0/6.0 0 0 0 0
Protocol inet, MTU: 1500
Max nh cache: 75000, New hold nh limit: 75000, Curr nh cnt: 1, Curr new hold cnt: 0, NH drop cnt: 0
Generation: 183, Route table: 0
Flags: Sendbcast-pkt-to-re, 0x0
Addresses, Flags: Is-Preferred Is-Primary
Destination: 10.2.2/24, Local: 10.2.2.1, Broadcast: 10.2.2.255, Generation: 161
Protocol multiservice, MTU: Unlimited, Generation: 184, Route table: 0
Flags: 0x0
Policer: Input: __default_arp_policer__Meaning
OSPF distributes traffic equally when the three aggregated Ethernet bundles have the same bandwidth available.
Verifying Unequal Traffic Distribution Over Available Bandwidth
Purpose
To verify that OSPF distributes traffic unevenly when one of the aggregated link is down during per-packet load balancing depending on the available bandwidth.
Action
Disable one of the links on the ae0 bundle. From operational mode, enter the
show route 10.1.255.2 extensive command.
user@R0> show route 10.1.255.2 extensive
inet.0: 17 destinations, 17 routes (17 active, 0 holddown, 0 hidden)
10.1.255.2/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 10.1.255.2/32 -> {list:10.0.0.2, 10.0.1.2, 10.2.2.2}
*OSPF Preference: 10
Next hop type: Router, Next hop index: 0
Address: 0x819ba14
Next-hop reference count: 2, Next-hop session id: 0
Kernel Table Id: 0
Next hop: 10.0.0.2 via ae0.0 weight 0x1 balance 20%
Session Id: 0
Next hop: 10.0.1.2 via ae1.0 weight 0x1 balance 40%, selected
Session Id: 0
Next hop: 10.2.2.2 via ae2.0 weight 0x1 balance 40%
Session Id: 0
State: <Active Int>
Age: 23 Metric: 1
Validation State: unverified
Area: 0.0.0.0
Task: OSPF
Announcement bits (1): 0-KRT
AS path: I
Thread: junos-main Meaning
OSPF infers that the ae0 bundle has lesser bandwidth available. Therefore, modifies per-packet load balancing according to the available bandwidth. As per the output, only 20 percent of the bandwidth is available on ae0 because one of the aggregated Ethernet links is down. Thus OSPF distributes traffic unequally depending on the available bandwidth.
Appendix 1: Set Commands on All Devices
To quickly configure this example, copy the following commands, paste them into a text file, remove any line breaks, change any details necessary to match your network configuration, and then copy and paste the commands into the CLI at the [edit] hierarchy level.
R0
set system host-name R0 set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3 set interfaces ge-0/0/1 description "LinkID: R0R1-1" set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 description "LinkID: R0R1-2" set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 description "LinkID: R0R1-3" set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 description "LinkID: R0R1-4" set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 description "LinkID: R0R1-5" set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 description "LinkID: R0R1-6" set interfaces ge-0/0/6 gigether-options 802.3ad ae2 set interfaces ae0 vlan-tagging set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.1/24 set interfaces ae1 vlan-tagging set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.1/24 set interfaces ae2 vlan-tagging set interfaces ae2 aggregated-ether-options minimum-links 2 set interfaces ae2 aggregated-ether-options lacp active set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.1/24 set interfaces lo0 unit 0 family inet address 10.1.255.1/32 set policy-options policy-statement pplb then load-balance per-packet set routing-options router-id 10.1.255.1 set routing-options forwarding-table export pplb set protocols ospf spf-options multipath weighted one-hop set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0
R1
set system host-name R1 set chassis maximum-ecmp 64 set chassis aggregated-devices ethernet device-count 3 set interfaces ge-0/0/1 description "LinkID: R0R1-1" set interfaces ge-0/0/1 gigether-options 802.3ad ae0 set interfaces ge-0/0/2 description "LinkID: R0R1-2" set interfaces ge-0/0/2 gigether-options 802.3ad ae0 set interfaces ge-0/0/3 description "LinkID: R0R1-3" set interfaces ge-0/0/3 gigether-options 802.3ad ae1 set interfaces ge-0/0/4 description "LinkID: R0R1-4" set interfaces ge-0/0/4 gigether-options 802.3ad ae1 set interfaces ge-0/0/5 description "LinkID: R0R1-5" set interfaces ge-0/0/5 gigether-options 802.3ad ae2 set interfaces ge-0/0/6 description "LinkID: R0R1-6" set interfaces ge-0/0/6 gigether-options 802.3ad ae2 set interfaces ae0 vlan-tagging set interfaces ae0 aggregated-ether-options minimum-links 1 set interfaces ae0 aggregated-ether-options lacp active set interfaces ae0 unit 0 vlan-id 6 set interfaces ae0 unit 0 family inet address 10.0.0.2/24 set interfaces ae1 vlan-tagging set interfaces ae1 aggregated-ether-options minimum-links 1 set interfaces ae1 aggregated-ether-options lacp active set interfaces ae1 unit 0 vlan-id 16 set interfaces ae1 unit 0 family inet address 10.0.1.2/24 set interfaces ae2 vlan-tagging set interfaces ae2 aggregated-ether-options minimum-links 2 set interfaces ae2 aggregated-ether-options lacp active set interfaces ae2 unit 0 vlan-id 26 set interfaces ae2 unit 0 family inet address 10.2.2.2/24 set interfaces lo0 unit 0 family inet address 10.1.255.2/32 set routing-options router-id 10.1.255.2 set protocols ospf area 0.0.0.0 interface ae0.0 set protocols ospf area 0.0.0.0 interface ae1.0 set protocols ospf area 0.0.0.0 interface ae2.0 set protocols ospf area 0.0.0.0 interface lo0.0
Example: Dynamically Adjusting OSPF Interface Metrics Based on Bandwidth
This example shows how to dynamically adjust OSPF interface metrics based on bandwidth.
Configuration
CLI Quick Configuration
To quickly configure bandwidth threshold values
and associated metric values for an OSPF interface, copy the following
commands, paste them into a text file, remove any line breaks, change
any details necessary to match your network configuration, copy and
paste the commands into the CLI at the [edit] hierarchy level, and
then enter commit from configuration mode.
[edit] set protocols ospf area 0.0.0.0 interface ae0.0 metric 5 set protocols ospf area 0.0.0.0 interface ae0.0 bandwidth-based-metrics bandwidth 1g metric 60 set protocols ospf area 0.0.0.0 interface ae0.0 bandwidth-based-metrics bandwidth 10g metric 50
Step-by-Step Procedure
To configure the metric for a specific OSPF interface:
-
Create an OSPF area.
Note:To specify OSPFv3, include the ospf3 statement at the [edit protocols] hierarchy level.
[edit] user@host# edit protocols ospf area 0.0.0.0
-
Configure the metric of the OSPF network segment.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface ae0 metric 5
-
Configure the bandwidth threshold values and associated metric values. With this configuration when aggregated Ethernet interface’s bandwidth is 1g, OSPF considers metric 60 for this interface. When aggregated Ethernet interface’s bandwidth is 10g , OSPF considers metric 50 for this interface.
[edit protocols ospf area 0.0.0.0 ] user@host# set interface ae0.0 bandwidth-based-metrics bandwidth 1g metric 60 user@host# set interface ae0.0 bandwidth-based-metrics bandwidth 10g metric 50
-
If you are done configuring the device, commit the configuration.
[edit protocols ospf area 0.0.0.0 ] user@host# commit
Results
Confirm your configuration by entering the show protocols ospf command. If the output does not display the intended configuration, repeat the instructions in this example to correct the configuration.
user@host# show protocols ospf
area 0.0.0.0 {
interface ae0.0 {
bandwidth-based-metrics {
bandwidth 1g metric 60;
bandwidth 10g metric 50;
}
metric 5;
}
}
To confirm your OSPFv3 configuration, enter the show protocols ospf3 command.
Requirements
Before you begin:
Configure the device interfaces. See the Interfaces User Guide for Security Devices.
Configure the router identifiers for the devices in your OSPF network. See Example: Configuring an OSPF Router Identifier.
Control OSPF designated router election. See Example: Controlling OSPF Designated Router Election
Configure a single-area OSPF network. See Example: Configuring a Single-Area OSPF Network.
Overview
You can specify a set of bandwidth threshold values and associated metric values for an OSPF interface. When the bandwidth of an interface changes, Junos OS automatically sets the interface metric to the value associated with the appropriate bandwidth threshold value. When you configure bandwidth-based metric values, you typically configure multiple bandwidth and metric values.
In this example, you configure OSPF interface ae0 for bandwidth-based metrics by including the bandwidth-based-metrics statement and the following settings:
bandwidth—Specifies the bandwidth threshold in bits per second. The range is 9600 through 1,000,000,000,000,000.
metric—Specifies the metric value to associate with a specific bandwidth value. The range is 1 through 65,535.
Topology
Verification
Confirm that the configuration is working properly.
Verifying the Configured Metric
Purpose
Verify the metric setting on the interface. Confirm that the Cost field displays the interface’s configured metric (cost). When choosing paths to a destination, OSPF uses the path with the lowest cost.
Action
From operational mode, enter the show ospf interface detail command for OSPFv2, and enter the show ospf3 interface detail command for OSPFv3.
Example: Controlling OSPF Route Preferences
This example shows how to control OSPF route selection in the forwarding table. This example also shows how you might control route selection if you are migrating from OSPF to another IGP.
Configuration
CLI Quick Configuration
To quickly configure the OSPF route preference
values, copy the following commands, paste them into a text file,
remove any line breaks, change any details necessary to match your
network configuration, copy and paste the commands into the CLI at
the [edit] hierarchy level, and then enter commit from
configuration mode.
[edit] set protocols ospf preference 168 external-preference 169
Step-by-Step Procedure
To configure route selection:
Enter OSPF configuration mode and set the external and internal routing preferences.
Note:To specify OSPFv3, include the
ospf3statement at the[edit protocols]hierarchy level.[edit] user@host# set protocols ospf preference 168 external-preference 169
If you are done configuring the device, commit the configuration.
[edit] user@host# commit
Results
Confirm your configuration by entering the show
protocols ospf command. If the output does not display the intended
configuration, repeat the instructions in this example to correct
the configuration.
user@host# show protocols ospf preference 168; external-preference 169;
To confirm your OSPFv3 configuration, enter the show protocols
ospf3 command.
Requirements
This example assumes that OSPF is properly configured and running in your network, and you want to control route selection because you are planning to migrate from OSPF to a different IGP.
Configure the device interfaces. See the Interfaces User Guide for Security Devices.
Configure the IGP that you want to migrate to.
Overview
Route preferences are used to select which route is installed in the forwarding table when several protocols calculate routes to the same destination. The route with the lowest preference value is selected.
By default, internal OSPF routes have a preference value of 10, and external OSPF routes have a preference value of 150. You might want to modify this setting if you are planning to migrate from OSPF to a different IGP. Modifying the route preferences enables you to perform the migration in a controlled manner.
This example makes the following assumptions:
OSPF is already running in your network.
You want to migrate from OSPF to IS-IS.
You configured IS-IS per your network requirements and confirmed it is working properly.
In this example, you increase the OSPF route preference values to make them less preferred than IS-IS routes by specifying 168 for internal OSPF routes and 169 for external OSPF routes. IS-IS internal routes have a preference of either 15 (for Level1) or 18 (for Level 2), and external routes have a preference of 160 (for Level 1) or 165 (for Level 2). In general, it is preferred to leave the new protocol at its default settings to minimize complexities and simplify any future addition of routing devices to the network. To modify the OSPF route preference values, configure the following settings:
preference—Specifies the route preference for internal OSPF routes. By default, internal OSPF routes have a value of 10. The range is from 0 through 4,294967,295 (232 – 1).external-preference—Specifies the route preference for external OSPF routes. By default, external OSPF routes have a value of 150. The range is from 0 through 4,294967,295 (232 – 1).
Topology
Verification
Confirm that the configuration is working properly.
Verifying the Route
Purpose
Verify that the IGP is using the appropriate route.
After the new IGP becomes the preferred protocol (in this example,
IS-IS), you should monitor the network for any issues. After you confirm
that the new IGP is working properly, you can remove the OSPF configuration
from the routing device by entering the delete ospf command
at the [edit protocols] hierarchy level.
Action
From operational mode, enter the show route command.
Understanding OSPF Overload Function
If the time elapsed after the OSPF instance is enabled is less than the specified timeout, overload mode is set.
You can configure the local routing device so that it appears to be overloaded. An overloaded routing device determines it is unable to handle any more OSPF transit traffic, which results in sending OSPF transit traffic to other routing devices. OSPF traffic to directly attached interfaces continues to reach the routing device. You might configure overload mode for many reasons, including:
If you want the routing device to participate in OSPF routing, but do not want it to be used for transit traffic. This could include a routing device that is connected to the network for analysis purposes, but is not considered part of the production network, such as network management routing devices.
If you are performing maintenance on a routing device in a production network. You can move traffic off that routing device so network services are not interrupted during your maintenance window.
You configure or disable overload mode in OSPF with or without a timeout. Without a timeout, overload mode is set until it is explicitly deleted from the configuration. With a timeout, overload mode is set if the time elapsed since the OSPF instance started is less than the specified timeout.
A timer is started for the difference between the timeout and the time elapsed since the instance started. When the timer expires, overload mode is cleared. In overload mode, the router link-state advertisement (LSA) is originated with all the transit router links (except stub) set to a metric of 0xFFFF. The stub router links are advertised with the actual cost of the interfaces corresponding to the stub. This causes the transit traffic to avoid the overloaded routing device and to take paths around the routing device. However, the overloaded routing device’s own links are still accessible.
The routing device can also dynamically enter the overload state, regardless of configuring the device to appear overloaded. For example, if the routing device exceeds the configured OSPF prefix limit, the routing device purges the external prefixes and enters into an overload state.
In cases of incorrect configurations, the huge number of routes
might enter OSPF, which can hamper the network performance. To prevent
this, prefix-export-limit should be configured which will
purge externals and prevent the network from the bad impact.
By allowing any number of routes to be exported into OSPF, the routing device can become overwhelmed and potentially flood an excessive number of routes into an area. You can limit the number of routes exported into OSPF to minimize the load on the routing device and prevent this potential problem.
By default, there is no limit to the number of prefixes (routes)
that can be exported into OSPF. To prevent this, prefix-export-limit should be configured which will purge externals and prevent the
network.
Starting from Junos OS Release 18.2 onward, the following functionalities are supported by Stub Router in your OSPF network, when the OSPF is overloaded:
Allow Route leaking—external prefixes are redistributed during OSPF overload and the prefixes are originated with normal cost.
Advertise stub network with max metric—stub networks are advertised with maximum metric during OSPF overload.
Advertise intra-area prefix with max metric—intra-area prefixes are advertised with maximum metric during OSPF overload.
Advertise external prefix with max possible metric—OSPF AS external prefixes are redistributed during OSPF overload and the prefixes are advertised with maximum cost.
You can now configure the following when OSPF is overloaded:
allow-route-leakingat the[edit protocols <ospf | ospf3> overload]hierarchy level to advertise the external prefixes with normal cost.stub-networkat the[edit protocols ospf overload]hierarchy level to advertise stub network with maximum metric.intra-area-prefixat the[edit protocols ospf3 overload]hierarchy level to advertise intra-area prefix with maximum metric.as-externalat the[edit protocols <ospf | ospf3> overload]hierarchy level to advertise external prefix with maximum metric.
To limit the number of prefixes exported to OSPF:
[edit] set protocols ospf prefix-export-limit number
The prefix export limit number can be a value from 0 through 4,294,967,295.
See Also
Example: Configuring OSPF to Make Routing Devices Appear Overloaded
This example shows how to configure a routing device running OSPF to appear to be overloaded.
Requirements
Before you begin:
Configure the device interfaces. See the Interfaces User Guide for Security Devices.
Configure the router identifiers for the devices in your OSPF network. See Example: Configuring an OSPF Router Identifier.
Control OSPF designated router election. See Example: Controlling OSPF Designated Router Election
Configure a single-area OSPF network. See Example: Configuring a Single-Area OSPF Network.
Configure a multiarea OSPF network. See Example: Configuring a Multiarea OSPF Network.
Overview
You can configure a local routing device running OSPF to appear to be overloaded, which allows the local routing device to participate in OSPF routing, but not for transit traffic. When configured, the transit interface metrics are set to the maximum value of 65535.
This example includes the following settings:
overload—Configures the local routing device so it appears to be overloaded. You might configure this if you want the routing device to participate in OSPF routing, but do not want it to be used for transit traffic, or you are performing maintenance on a routing device in a production network.
timeout seconds—(Optional) Specifies the number of seconds at which the overload is reset. If no timeout interval is specified, the routing device remains in the overload state until the overload statement is deleted or a timeout is set. In this example, you configure 60 seconds as the amount of time the routing device remains in the overload state. By default, the timeout interval is 0 seconds (this value is not configured). The range is from 60 through 1800 seconds.
Topology
Configuration
Procedure
CLI Quick Configuration
To quickly configure a local routing device
to appear as overloaded, copy the following commands, paste them into
a text file, remove any line breaks, change any details necessary
to match your network configuration, copy and paste the commands into
the CLI at the [edit] hierarchy level, and then enter commit from configuration mode.
[edit] set protocols ospf overload timeout 60
Step-by-Step Procedure
To configure a local routing device to appear overloaded:
Enter OSPF configuration mode.
Note:To specify OSPFv3, include the
ospf3statement at the[edit protocols]hierarchy level.[edit] user@host# edit protocols ospfConfigure the local routing device to be overloaded.
[edit protocols ospf] user@host# set overload(Optional) Configure the number of seconds at which overload is reset.
[edit protocols ospf] user@host#
set overload timeout 60(Optional) Configure the limit on the number prefixes exported to OSPF, to minimise the load on the routing device and prevent the device from entering the overload mode.
[edit protocols ospf] user@host# set prefix-export-limit 50
If you are done configuring the device, commit the configuration.
[edit protocols ospf] user@host# commit
Results
Confirm your configuration by entering the show
protocols ospf command. If the output does not display the intended
configuration, repeat the instructions in this example to correct
the configuration. The output includes the optional timeout and prefix-export-limit statements.
user@host# show protocols ospf prefix-export-limit 50; overload timeout 60;
To confirm your OSPFv3 configuration, enter the show protocols
ospf3 command.
Verification
Confirm that the configuration is working properly.
- Verifying Traffic Has Moved Off Devices
- Verifying Transit Interface Metrics
- Verifying the Overload Configuration
- Verifying the Viable Next Hop
Verifying Traffic Has Moved Off Devices
Purpose
Verify that the traffic has moved off the upstream devices.
Action
From operational mode, enter the show interfaces
detail command.
Verifying Transit Interface Metrics
Purpose
Verify that the transit interface metrics are set to the maximum value of 65535 on the downstream neighboring device.
Action
From operational mode, enter the show ospf database
router detail advertising-router address command for OSPFv2, and enter the show ospf3 database router
detail advertising-router address command
for OSPFv3.
Verifying the Overload Configuration
Purpose
Verify that overload is configured by reviewing the Configured overload field. If the overload timer is also configured, this field also displays the time that remains before it is set to expire.
Action
From operational mode, enter the show ospf overview command for OSPFv2, and the show ospf3 overview command
for OSPFv3.
Verifying the Viable Next Hop
Purpose
Verify the viable next hop configuration on the upstream neighboring device. If the neighboring device is overloaded, it is not used for transit traffic and is not displayed in the output.
Action
From operational mode, enter the show route address command.
Understanding the SPF Algorithm Options for OSPF
OSPF uses the shortest-path-first (SPF) algorithm, also referred to as the Dijkstra algorithm, to determine the route to reach each destination. The SPF algorithm describes how OSPF determines the route to reach each destination, and the SPF options control the timers that dictate when the SPF algorithm runs. Depending on your network environment and requirements, you might want to modify the SPF options. For example, consider a large-scale environment with a large number of devices flooding link-state advertisements (LSAs) through out the area. In this environment, it is possible to receive a large number of LSAs to process, which can consume memory resources. By configuring the SPF options, you continue to adapt to the changing network topology, but you can minimize the amount of memory resources being used by the devices to run the SPF algorithm.
You can configure the following SPF options:
The delay in the time between the detection of a topology change and when the SPF algorithm actually runs.
The maximum number of times that the SPF algorithm can run in succession before the hold-down timer begins.
The time to hold down, or wait, before running another SPF calculation after the SPF algorithm has run in succession the configured number of times. If the network stabilizes during the holddown period and the SPF algorithm does not need to run again, the system reverts to the configured values for the delay and
rapid-runsstatements.
Example: Configuring SPF Algorithm Options for OSPF
This example shows how to configure the SPF algorithm options. The SPF options control the timers that dictate when the SPF algorithm runs.
Requirements
Before you begin:
Configure the device interfaces. See the Junos OS Network Interfaces Library for Routing Devices.
Configure the router identifiers for the devices in your OSPF network. See Example: Configuring an OSPF Router Identifier.
Control OSPF designated router election. See Example: Controlling OSPF Designated Router Election
Configure a single-area OSPF network. See Example: Configuring a Single-Area OSPF Network.
Configure a multiarea OSPF network. See Example: Configuring a Multiarea OSPF Network.
Overview
OSPF uses the SPF algorithm to determine the route to reach each destination. All routing devices in an area run this algorithm in parallel, storing the results in their individual topology databases. Routing devices with interfaces to multiple areas run multiple copies of the algorithm. The SPF options control the timers used by the SPF algorithm.
Before you modify any of the default settings, you should have a good understanding of your network environment and requirements.
This example shows how to configure the options for running
the SPF algorithm. You include the spf-options statement
and the following options:
delay—Configures the amount of time (in milliseconds) between the detection of a topology and when the SPF actually runs. When you modify the delay timer, consider your requirements for network reconvergence. For example, you want to specify a timer value that can help you identify abnormalities in the network, but allow a stable network to reconverge quickly. By default, the SPF algorithm runs 200 milliseconds after the detection of a topology. The range is from 50 through 8000 milliseconds.
rapid-runs—Configures the maximum number of times that the SPF algorithm can run in succession before the hold-down timer begins. By default, the number of SPF calculations that can occur in succession is 3. The range is from 1 through 10. Each SPF algorithm is run after the configured SPF delay. When the maximum number of SPF calculations occurs, the hold-down timer begins. Any subsequent SPF calculation is not run until the hold-down timer expires.
holddown—Configures the time to hold down, or wait, before running another SPF calculation after the SPF algorithm has run in succession the configured maximum number of times. By default, the hold down time is 5000 milliseconds. The range is from 2000 through 20,000 milliseconds. If the network stabilizes during the holddown period and the SPF algorithm does not need to run again, the system reverts to the configured values for the delay and
rapid-runsstatements.
Topology
Configuration
CLI Quick Configuration
To quickly configure the SPF options, copy the following commands and paste them into the CLI.
[edit] set protocols ospf spf-options delay 210 set protocols ospf spf-options rapid-runs 4 set protocols ospf spf-options holddown 5050
Procedure
Step-by-Step Procedure
To configure the SPF options:
Enter OSPF configuration mode.
Note:To specify OSPFv3, include the
ospf3statement at the[edit protocols]hierarchy level.[edit] user@host# edit protocols ospf
Configure the SPF delay time.
[edit protocols ospf] user@host# set spf-options delay 210
Configure the maximum number of times that the SPF algorithm can run in succession.
[edit protocols ospf] user@host# set spf-options rapid-runs 4
Configure the SPF hold-down timer.
[edit protocols ospf] user@host# set spf-options holddown 5050
If you are done configuring the device, commit the configuration.
[edit protocols ospf] user@host# commit
Results
Confirm your configuration by entering the show
protocols ospf command. If the output does not display the intended
configuration, repeat the instructions in this example to correct
the configuration.
user@host# show protocols ospf
spf-options {
delay 210;
holddown 5050;
rapid-runs 4;
}
To confirm your OSPFv3 configuration, enter the show protocols
ospf3 command.
Verification
Confirm that the configuration is working properly.
Verifying SPF Options
Purpose
Verify that SPF is operating per your network requirements. Review the SPF delay field, the SPF holddown field, and the SPF rapid runs fields.
Action
From operational mode, enter the show ospf overview command for OSPFv2, and enter the show ospf3 overview command for OSPFv3.
Configuring OSPF Refresh and Flooding Reduction in Stable Topologies
The OSPF standard requires that every link-state advertisement (LSA) be refreshed every 30 minutes. The Juniper Networks implementation refreshes LSAs every 50 minutes. By default, any LSA that is not refreshed expires after 60 minutes. This requirement can result in traffic overhead that makes it difficult to scale OSPF networks. You can override the default behavior by specifying that the DoNotAge bit be set in self-originated LSAs when they are initially sent by the router or switch. Any LSA with the DoNotAge bit set is reflooded only when a change occurs in the LSA. This feature thus reduces protocol traffic overhead while permitting any changed LSAs to be flooded immediately. Routers or switches enabled for flood reduction continue to send hello packets to their neighbors and to age self-originated LSAs in their databases.
The Juniper implementation of OSPF refresh and flooding reduction is based on RFC 4136, OSPF Refresh and Flooding Reduction in Stable Topologies. However, the Juniper implementation does not include the forced-flooding interval defined in the RFC. Not implementing the forced-flooding interval ensures that LSAs with the DoNotAge bit set are reflooded only when a change occurs.
This feature is supported for the following:
OSPFv2 and OSPFv3 interfaces
OSPFv3 realms
OSPFv2 and OSPFv3 virtual links
OSPFv2 sham links
OSPFv2 peer interfaces
All routing instances supported by OSPF
Logical systems
To configure flooding reduction for an OSPF interface, include
the flood-reduction statement at the [edit protocols
(ospf | ospf3) area area-id interface interface-id] hierarchy level.
If you configure flooding reduction for an interface configured as a demand circuit, the LSAs are not initially flooded, but sent only when their content has changed. Hello packets and LSAs are sent and received on a demand-circuit interface only when a change occurs in the network topology.
In the following example, the OSPF interface so-0/0/1.0 is configured for flooding reduction. As a result, all the LSAs generated by the routes that traverse the specified interface have the DoNotAge bit set when they are initially flooded, and LSAs are refreshed only when a change occurs.
[edit]
protocols ospf {
area 0.0.0.0 {
interface so-0/0/1.0 {
flood-reduction;
}
interface lo0.0;
interface so-0/0/0.0;
}
}
Beginning with Junos OS Release 12.2, you can configure
a global default link-state advertisement (LSA) flooding interval
in OSPF for self-generated LSAs by including the lsa-refresh-interval minutes statement at the [edit protocols (ospf
| ospf3)] hierarchy level. The Juniper Networks implementation
refreshes LSAs every 50 minutes. The range is 25 through 50 minutes.
By default, any LSA that is not refreshed expires after 60 minutes.
If you have both the global LSA refresh interval configured for OSPF and OSPF flooding reduction configured for a specific interface in an OSPF area, the OSPF flood reduction configuration takes precedence for that specific interface.
Understanding Synchronization Between LDP and IGPs
LDP is a protocol for distributing labels in non-traffic-engineered applications. Labels are distributed along the best path determined by the interior gateway protocol (IGP). If synchronization between LDP and the IGP is not maintained, the label-switch path (LSP) goes down. When LDP is not fully operational on a given link (a session is not established and labels are not exchanged), the IGP advertises the link with the maximum cost metric. The link is not preferred but remains in the network topology.
LDP synchronization is supported only on active point-to-point interfaces and LAN interfaces configured as point-to-point under the IGP. LDP synchronization is not supported during graceful restart.
See Also
Example: Configuring Synchronization Between LDP and OSPF
This example shows how to configure synchronization between LDP and OSPFv2.
Requirements
Before you begin:
Configure the device interfaces. See the Junos OS Network Interfaces Library for Routing Devices.
Configure the router identifiers for the devices in your OSPF network. See Example: Configuring an OSPF Router Identifier.
Control OSPF designated router election. See Example: Controlling OSPF Designated Router Election
Configure a single-area OSPF network. See Example: Configuring a Single-Area OSPF Network.
Configure a multiarea OSPF network. See Example: Configuring a Multiarea OSPF Network.
Overview
In this example, configure synchronization between LDP and OSPFv2 by performing the following tasks:
Enable LDP on interface so-1/0/3, which is a member of OSPF area 0.0.0.0, by including the
ldpstatement at the[edit protocols]hierarchy level. You can configure one or more interfaces. By default, LDP is disabled on the routing device.Enable LDP synchronization by including the
ldp-synchronizationstatement at the[edit protocols ospf area area-id interface interface-name]hierarchy level. This statement enables LDP synchronization by advertising the maximum cost metric until LDP is operational on the link.Configure the amount of time (in seconds) the routing device advertises the maximum cost metric for a link that is not fully operational by including the
hold-timestatement at the[edit protocols ospf area area-id interface interface-name ldp-synchronization]hierarchy level. If you do not configure thehold-timestatement, the hold-time value defaults to infinity. The range is from 1 through 65,535 seconds. In this example, configure 10 seconds for the hold-time interval.
This example also shows how to disable synchronization between
LDP and OSPFv2 by including the disable statement at the [edit protocols ospf area area-id interface interface-name ldp-synchronization] hierarchy level.
Topology
Configuration
Enabling Synchronization Between LDP and OSPFv2
CLI Quick Configuration
The following example requires you to navigate various levels in the configuration hierarchy. For information about navigating the CLI, see Modifying the Junos OS Configuration in CLI User Guide.
To quickly enable synchronization between LDP and OSPFv2, copy the following commands, remove any line breaks, and then paste them into the CLI.
[edit] set protocols ldp interface so-1/0/3 set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-syncrhonization hold-time 10
Step-by-Step Procedure
To enable synchronization between LDP and OSPFv2:
Enable LDP on the interface.
[edit] user@host# set protocols ldp interface so-1/0/3
Configure LDP synchronization and optionally configure a time period of 10 seconds to advertise the maximum cost metric for a link that is not fully operational.
[edit ] user@host# edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization
Configure a time period of 10 seconds to advertise the maximum cost metric for a link that is not fully operational.
[edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization ] user@host# set hold-time 10
If you are done configuring the device, commit the configuration.
[edit protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization] user@host# commit
Results
Confirm your configuration by entering the show
protocols ldp and show protocols ospf commands. If
the output does not display the intended configuration, repeat the
instructions in this example to correct the configuration.
user@host# show protocols ldp interface so-1/0/3.0;
user@host# show protocols ospf
area 0.0.0.0 {
interface so-1/0/3.0 {
ldp-synchronization {
hold-time 10;
}
}
}
Disabling Synchronization Between LDP and OSPFv2
CLI Quick Configuration
To quickly disable synchronization between LDP and OSPFv2, copy the following command and paste it into the CLI.
[edit] set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization disable
Step-by-Step Procedure
To disable synchronization between LDP and OSPF:
Disable synchronization by including the
disablestatement.[edit ] user@host# set protocols ospf area 0.0.0.0 interface so-1/0/3 ldp-synchronization disable
If you are done configuring the device, commit the configuration.
[edit] user@host# commit
Results
Confirm your configuration by entering the show
protocols ospf command. If the output does not display the intended
configuration, repeat the instructions in this example to correct
the configuration.
user@host# show protocols ospf
area 0.0.0.0 {
interface so-1/0/3.0 {
ldp-synchronization {
disable;
}
}
}
Verification
Confirm that the configuration is working properly.
Verifying the LDP Synchronization State of the Interface
Purpose
Verify the current state of LDP synchronization on the interface. The LDP sync state displays information related to the current state, and the config holdtime field displays the configured hold-time interval.
Action
From operational mode, enter the show ospf interface
extensive command.
OSPFv2 Compatibility with RFC 1583 Overview
By default, the Junos OS implementation of OSPFv2 is compatible with RFC 1583, OSPF Version 2. This means that Junos OS maintains a single best route to an autonomous system (AS) boundary router in the OSPF routing table, rather than multiple intra-AS paths, if they are available. You can now disable compatibility with RFC 1583. It is preferable to do so when the same external destination is advertised by AS boundary routers that belong to different OSPF areas. When you disable compatibility with RFC 1583, the OSPF routing table maintains the multiple intra-AS paths that are available, which the router uses to calculate AS external routes as defined in RFC 2328, OSPF Version 2. Being able to use multiple available paths to calculate an AS external route can prevent routing loops.
See Also
Example: Disabling OSPFv2 Compatibility with RFC 1583
This example shows how to disable OSPFv2 compatibility with RFC 1583 on the routing device.
Requirements
No special configuration beyond device initialization is required before disabling OSPFv2 compatibility with RFC 1583.
Overview
By default, the Junos OS implementation of OSPF is compatible with RFC 1583. This means that Junos OS maintains a single best route to an autonomous system (AS) boundary router in the OSPF routing table, rather than multiple intra-AS paths, if they are available. You can disable compatibility with RFC 1583. It is preferable to do so when the same external destination is advertised by AS boundary routers that belong to different OSPF areas. When you disable compatibility with RFC 1583, the OSPF routing table maintains the multiple intra-AS paths that are available, which the router uses to calculate AS external routes as defined in RFC 2328. Being able to use multiple available paths to calculate an AS external route can prevent routing loops. To minimize the potential for routing loops, configure the same RFC compatibility on all OSPF devices in an OSPF domain.
Topology
Configuration
Procedure
CLI Quick Configuration
To quickly disable OSPFv2 compatibility with
RFC 1583, copy the following commands, paste them into a text file,
remove any line breaks, change any details necessary to match your
network configuration, copy and paste the commands into the CLI at
the [edit] hierarchy level, and then enter commit from
configuration mode. You configure this setting on all devices that
are part of the OSPF domain.
[edit] set protocols ospf no-rfc-1583
Step-by-Step Procedure
To disable OSPFv2 compatibility with RFC 1583:
Disable RFC 1583.
[edit] user@host# set protocols ospf no-rfc-1583
If you are done configuring the device, commit the configuration.
[edit] user@host# commit
Note:Repeat this configuration on each routing device that participates in an OSPF routing domain.
Results
Confirm your configuration by entering the show
protocols ospf command. If the output does not display the intended
configuration, repeat the instructions in this example to correct
the configuration.
user@host# show protocols ospf no-rfc-1583;
Verification
Confirm that the configuration is working properly.