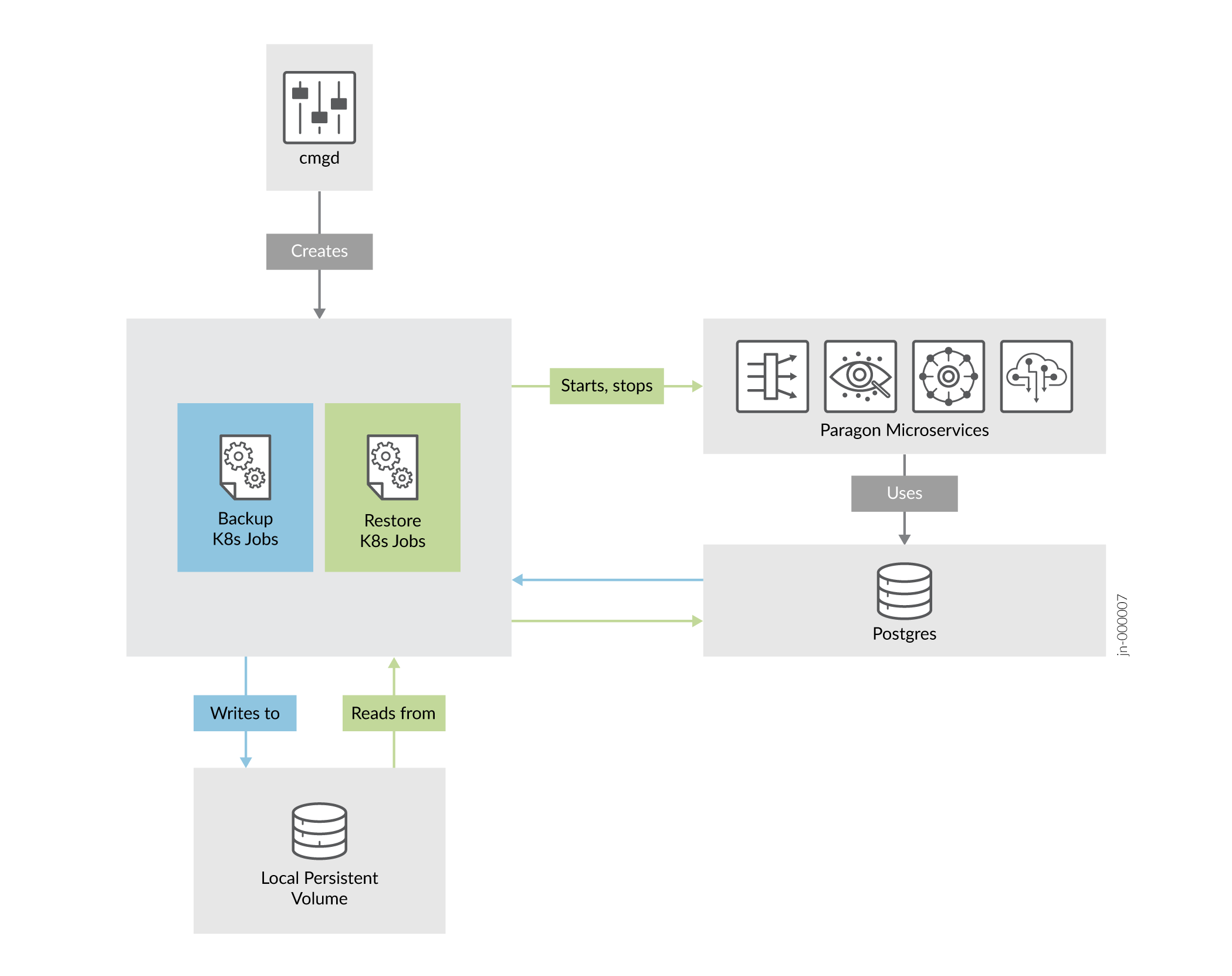
Backup and Restore
This topic describes the backup and restore capabilities available in Paragon Automation. Although Paragon Automation is a GUI-based application, the backup and restore operations are managed from the Paragon Insights cMGD CLI. Postgres is the primary persistent storage database for microservices. Backup files are saved in a local persistent volume on the cluster nodes. The backup procedure can be performed while microservices are running and does not affect the operation of the cluster. However, for restore procedures, microservices are stopped and the cluster is not functional until the databases are restored.
Currently, you cannot custom select applications to be backed up and restored. You can back up and restore only a preconfigured and fixed set of applications and administrations settings for each component, as listed in Table 1.
|
Devices |
Alerts/Alarm Settings |
Admin Groups |
|
Topics |
Plot Settings |
User Defined Actions and Functions |
|
Playbooks |
Summarization Profiles |
Auditlogs |
|
Device Groups |
Ingest Settings |
Topology Filter Configuration |
|
Network Groups |
SNMP Proxy Configuration |
Pathfinder Settings |
|
Notification Settings |
IAM Settings |
LSP Policies and Profiles |
|
Retention Policies |
Workflows |
Report Generation Settings (Destination, Report and Scheduler Settings) |
The backup procedure has the following limitations:
-
Telemetry data—Data captured from the devices will not be backed up, by default. Telemetry data must be backed up manually.
For more information, see Backup and Restore the TSDB.
-
Transient and logging data—Data which is being processed and expired events will not be backed up. For example:
-
Alerts and alarms generated
-
Configuration changes which are not committed
-
Most application logs
-
-
Non-Paragon-Automation Configuration—Configuration done on third-party services supported by Paragon Automation will not be backed up. For example:
-
LDAP user details
-
-
Topology Ingest Configuration-The cRPD configuration to peer with BGP-LS routers for topology information will not be backed up. This must be manually reconfigured again as required. For more information, see Modify cRPD Configuration.
You use containerized scripts invoked through Kubernetes jobs to implement the backup and restore procedures.
You can manually back up your cluster using the instructions described in Back Up the Configuration. You can also, use a backup script to back up your cluster using the instructions described in Backup and Restore Scripts.
Similarly, you can manually restore the backed up configuration using the instructions described in Restore the Configuration. You can also use a restore script to restore your backed up configuration using the instructions described in Backup and Restore Scripts.
For Paragon Automation Release 23.2, you can restore a backed up configuration from earlier releases of Paragon Automation only after you perform a dummy back up of a fresh Release 23.2 installation. To use the restore operation on a Release 23.2 cluster, we recommend that you:
-
Upgrade your current Paragon Automation cluster to Release 23.1.
-
Back up the Release 23.1 configuration.
-
Install a Release 23.2 cluster.
-
Back up the 23.2 cluster.
-
Copy the Release 23.1 configuration to the backed up Release 23.2 location.
-
Restore the copied backed up configuration.
Back Up the Configuration
Data across most Paragon Automation applications is primarily stored in Postgres. When you back up a configuration, system-determined and predefined data is backed up. When you perform a backup, the operational system and microservices are not affected. You can continue to use Paragon Automation while a backup is running. You'll use the management daemon (MGD) CLI, managed by Paragon Insights (formerly Healthbot), to perform the backup.
To back up the current Paragon Automation configuration:
Frequently Used kubectl Commands to View Backup Details
To view the status of your backup or the location of your backup files, or to view more information on the backup files, use the following commands.
-
Backup jobs exist in the common namespace and use the
common=db-backuplabel. To view all backup jobs:root@primary-node:~# kubectl get -n common jobs -l common=db-backup NAME COMPLETIONS DURATION AGE db-backup-hello-world 1/1 3m11s 2d20h
-
To view more details of a specific Kubernetes job:
root@primary-node:~# kubectl describe -n common jobs/db-backup-hello-world -
To view the logs of a specific Kubernetes job:
root@primary-node:~# kubectl logs -n common --tail 50 jobs/db-backup-hello-world -
To determine the location of the backup files:
root@primary-node:~# kubectl get -n common pvc db-backup-pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE db-backup-pvc Bound local-pv-cb20f386 145Gi RWO local-storage 3d3h
The output points you to the local persistent volume. Use that persistent volume to determine the node on which the backup files are stored.
root@primary-node:~# kubectl describe -n common pv local-pv-cb20f386 Node Affinity: Required Terms: Term 0: kubernetes.io/hostname in [10.49.xxx.x2] Message: Source: Type: LocalVolume (a persistent volume backed by local storage on a node) Path: /export/local-volumes/pv*
To view all the backup files, log in to the node and navigate to the location of the backup folder.
root@primary-node:~# ssh root@10.49.xxx.x2 root@10.49.xxx.x2:~# ls -l /export/local-volumes/pv*
To view commonly seen backup and restore failure scenarios, see Common Backup and Restore Issues.
Restore the Configuration
You can restore a Paragon Automation configuration from a previously backed-up configuration folder. A restore operation rewrites the databases with all the backed-up configuration information. You cannot selectively restore databases. When you perform a restore operation, a Kubernetes job is spawned, which stops the affected microservices. The job restores the backed-up configuration and restarts the microservices. Paragon Automation remains nonfunctional until the restoration procedure is complete.
You cannot run multiple restore jobs at the same time because the Kubernetes job stops the microservices during the restoration process. Also, you cannot run both backup and restore processes concurrently.
We strongly recommend that you restore a configuration during a maintenance window, otherwise the system can go into an inconsistent state.
To restore the Paragon Automation configuration to a previously backed-up configuration:
Frequently Used kubectl Commands to View Restore Details
To view more information and the status of your restore process, use the following commands:
-
Restore jobs exist in the common namespace and use the
common=db-restorelabel. To view all restore jobs:root@primary-node:~# kubectl get -n common jobs -l common=db-restore NAME COMPLETIONS DURATION AGE db-restore-hello-world 0/1 20s 21s
-
To view more details of a specific Kubernetes job:
root@primary-node:~# kubectl describe -n common jobs/db-restore-hello-world -
To view the logs of a particular Kubernetes job:
root@primary-node:~# kubectl logs -n common --tail 50 jobs/db-restore-hello-world
To view commonly seen backup and restore failure scenarios, see Common Backup and Restore Issues.
Backup and Restore Scripts
You can also use the Paragon Automation backup and restore scripts to simplify the backup and restore operations. This topic describes the backup and restore script operations and the caveats around the usage of the scripts.
Backup Script Operation
The backup script automatically backs up your current configuration. The primary benefit of the backup script is that you can run it as a cron job with the required frequency so as to schedule regular backups. Additionally, the backup script creates distinguishable date stamped backup folders and the folders do not get overwritten if the script is run on different days.
To back up your configuration using the backup script:
-
Log in to any one of the primary nodes.
-
Execute the backup script.
root@primary-node:~# data.sh --backup
The script runs a backup job to back up your current configuration. A backup folder is created and saved in a local persistent volume on one of the cluster nodes. The folder name is in the <name>-year_month_day format. The folder in your cluster node contains all your backed up configuration metadata.
The script also creates a folder of the same name in the current path in your primary node. The backup folder in your primary node contains the JSON files required for base platform used while restoring the backed up configuration.
As the script is running, a backup summary is generated and displayed onscreen. The summary contains the node and location of the backup files. For example:
===============================Backup Report================================
Name: db-backup-paa-2023-10-18
Namespace: common
Selector: controller-uid=446d45fd-0a7e-4b21-94b1-02f079b11879
Labels: apps=db-backup
common=db-backup
id=paa-2023-10-18
Annotations: <none>
Parallelism: 1
Completions: 1
Start Time: Wed, 18 Oct 2023 08:39:04 -0700
Completed At: Wed, 18 Oct 2023 08:39:23 -0700
Duration: 19s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: app=db-backup
common=db-backup
controller-uid=446d45fd-0a7e-4b21-94b1-02f079b11879
id=paa-2023-10-18
job-name=db-backup-paa-2023-10-18
Service Account: db-backup
Containers:
db-backup:
Image: localhost:5000/eng-registry.juniper.net/northstar-scm/northstar-containers/ns_dbinit:release-23-1-ge572e4b914
Port: <none>
Host Port: <none>
Command:
/bin/sh
Args:
-c
exec /entrypoint.sh --backup /paa-2023-10-18
Environment:
PG_HOST: atom-db.common
PG_PORT: 5432
PG_ADMIN_USER: <set to the key 'username' in secret 'atom.atom-db.credentials'> Optional: false
PG_ADMIN_PASS: <set to the key 'password' in secret 'atom.atom-db.credentials'> Optional: false
Mounts:
/opt/northstar/data/backup from postgres-backup (rw)
Volumes:
postgres-backup:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: db-backup-pvc
ReadOnly: false
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 47m job-controller Created pod: db-backup-paa-2023-10-18-95b8j
Normal Completed 47m job-controller Job completed
=============================================================================
Running EMS Backup.
===============================Get Backup file location======================
Name: local-pv-81fa4ecb
Labels: <none>
Annotations: pv.kubernetes.io/bound-by-controller: yes
pv.kubernetes.io/provisioned-by: local-volume-provisioner-10.16.18.20-b73872bc-257c-4e82-b744-c6981bc3e131
Finalizers: [kubernetes.io/pv-protection]
StorageClass: local-storage
Status: Bound
Claim: common/db-backup-pvc
Reclaim Policy: Delete
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 149Gi
Node Affinity:
Required Terms:
Term 0: kubernetes.io/hostname in [10.16.18.20]
Message:
Source:
Type: LocalVolume (a persistent volume backed by local storage on a node)
Path: /export/local-volumes/pv1
Events: <none>
=============================================================================
Running Pathfinder Kubernetes Config Backup.
=============================================================================
...<snipped>...
=============================Backup Completed================================
In this example, the backup folder containing all the backup metadata is stored in your cluster node with IP address 10.16.18.20 in the /export/local-volumes/pv1 folder.
Restore Script Operation
The restore script automatically restores your backed up configuration.
To restore your configuration using the restore script:
-
Log in to any one of the primary nodes.
-
Get your MGD container name:
#kubectl get po -n healthbot | grep mgd
-
Execute the restore command.
#kubectl exec -ti -n healthbot mgd-858f4b8c9-sttnh -- cli request system restore path /paa-2023-10-18
-
Find the restore pod in common namespace.
#kubectl get po -n common | grep restore db-restore-paa-2023-10-18-6znb8
-
Check logs from restore pod.
#kubectl logs -n common db-restore-paa-2023-10-18-6znb8
-
Follow logs and refresh looking for Restore Complete towards the end of the logs.
2023-10-18 16:01:11,127:DEBUG:pg_restore: creating ACL "metric_helpers.TABLE pg_stat_statements" 2023-10-18 16:01:11,129:DEBUG:pg_restore: creating ACL "metric_helpers.TABLE table_bloat" 2023-10-18 16:01:11,131:DEBUG:pg_restore: creating ACL "pg_catalog.TABLE pg_stat_activity" 2023-10-18 16:01:11,137:INFO:Restore complete 2023-10-18 16:01:11,388:INFO:Deleted secret ems/jobmanager-identitysrvcreds 2023-10-18 16:01:11,396:INFO:Deleted secret ems/devicemodel-connector-default-scope-id 2023-10-18 16:01:11,396:WARNING:Could not restore common/iam-smtp-config, iam-smtp-bkup.yml not found 2023-10-18 16:01:21,405:DEBUG:Waiting for secrets to be deleted (10/60) sec 2023-10-18 16:01:21,433:INFO:Created secret ems/jobmanager-identitysrvcreds 2023-10-18 16:01:21,443:INFO:Created secret ems/devicemodel-connector-default-scope-id 2023-10-18 16:01:21,444:INFO:Starting northstar applications 2023-10-18 16:01:22,810:INFO:Starting ems applications 2023-10-18 16:01:23,164:INFO:Starting auditlog applications 2023-10-18 16:01:23,247:INFO:Starting iam applications
-
Log in to the Release 23.2 UI and verify the restored data.
Caveats of Backup and Restore Scripts
The caveats of the backup and restore scripts are as following:
-
You can run the scripts either on a weekly basis or only once daily. Running them multiple times in a 24-hour period returns an error since there is already a backup folder for that day named <name>-year_month_day. If you need to take a manual backup in the same 24-hour period, you must remove the job using the
kubectl delete -n common jobscommand. For example:# kubectl delete -n common jobs db-backup-paa-2023_20_04 -
The scripts fill disk space with backup files depending on the frequency and size of backup files. Consider removing outdated backup metadata and files to free up disk space. You can remove the Kubernetes metadata using the
kubectl delete -n common jobscommand. For example:# kubectl delete -n common jobs db-backup-paa-2023_20_04You can remove the backup files by deleting the <name>-year-month-day folders created in the /root/ folder in the local volume path displayed in the summary when you run the backup script.