Install Multinode Cluster on Red Hat Enterprise Linux
Read the following topics to learn how to install Paragon Automation on a multinode cluster with Red Hat Enterprise Linux (RHEL) host OS. Figure 1 shows a summary of installation tasks at a high level. Ensure that you've completed the preconfiguration and preparation steps described in Installation Prerequisites on Red Hat Enterprise Linux before you begin installation.
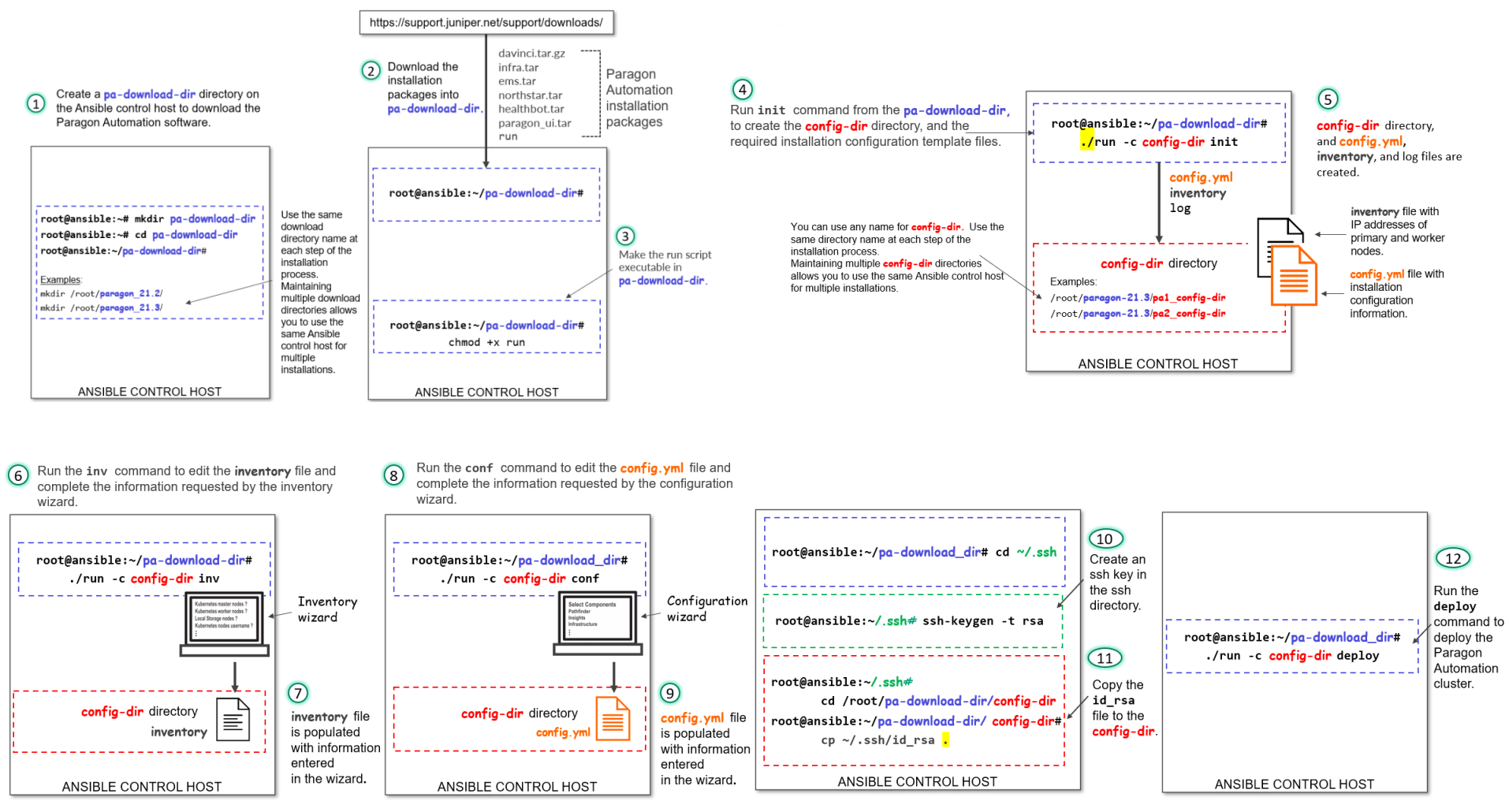
To view a higher-resolution image in your Web browser, right-click the image and open in a new tab. To view the image in PDF, use the zoom option to zoom in.
Download the Paragon Automation Software
Prerequisite
-
You need a Juniper account to download the Paragon Automation software.
- Log in to the control host.
-
Create a directory in which you'll download the software.
We refer to this directory as pa-download-dir in this guide.
- Select the version number from the Version list on the Paragon Automation software download page at https://support.juniper.net/support/downloads/?p=pa.
-
Download the Paragon Automation Setup installation
files to the download folder and extract the file. You can use the
wget "http://cdn.juniper.net/software/file-download-url"command to download the files and any extraction utility to extract the files.The Paragon Automation setup installation bundle consists of the following scripts and TAR files to install each of the component modules:
-
davinci.tar.gz, which is the primary installer file.
-
infra.tar, which installs the Kubernetes infrastructure components including Docker and Helm.
-
ems.tar, which installs the base platform component.
-
northstar.tar, which installs the Paragon Pathfinder and Paragon Planner components.
-
healthbot.tar, which installs the Paragon Insights component.
-
paragon_ui.tar, which installs the Paragon Automation UI component.
-
addons.tar, which installs infrastructure components that are not part of the base Kubernetes installation. The infrastructure components include, IAM, Kafka, ZooKeeper, cert-manager, Ambassador, Postgres, Metrics, Kubernetes Dashboard, Open Distro for Elasticsearch, Fluentd, Reloader, ArangoDB, and Argo.
- rke2-packages.tgz, which installs the RKE2-based Kubernetes components.
- 3rdparty.tar.gz, which installs the required third-party utilities.
-
rhel-84-airgap.tar.gz, which installs Paragon Automation using the air-gap method on nodes only where the base OS is Red Hat Enterprise Linux (RHEL). You can choose to delete this file if you are not installing Paragon Automation using the air-gapped method on an RHEL base OS.
-
runscript, which executes the installer image.
Now that you've downloaded the software, you're ready to install Paragon Automation.
-
Install Paragon Automation on a Multinode Cluster
-
Make the
runscript executable in the pa-download-dir directory.# chmod +x run
-
Use the
runscript to create and initialize a configuration directory with the configuration template files.# ./run -c config-dir init
config-dir is a user-defined directory on the control host that contains configuration information for a particular installation. The
initcommand automatically creates the directory if it does not exist. Alternatively, you can create the directory before you execute theinitcommand.Ensure that you include the dot and slash (./) with the
runcommand.If you are using the same control host to manage multiple installations of Paragon Automation, you can differentiate between installations by using differently named configuration directories.
-
Ensure that the control host can connect to the cluster nodes through SSH
using the install-user account.
Copy the private key that you generated in Configure SSH client authentication to the user-defined config-dir directory. The installer allows the Docker container to access the config-dir directory. The SSH key must be available in the directory for the control host to connect to the cluster nodes.
# cd config-dir # cp ~/.ssh/id_rsa . # cd ..
Ensure that you include the dot (.) at the end of the copy command (
cp). -
Customize the inventory file, available in the
config-dir
directory, with
the IP addresses or hostnames of the cluster nodes, as well as the usernames
and authentication information that are required to connect to the nodes.
The inventory file is in the YAML format and describes the cluster nodes on
which Paragon Automation will be installed. You can edit the file using the
invcommand or a Linux text editor such as vi.-
Customize the inventory file using the
invcommand:# ./run -c config-dir inv
The following table lists the configuration options that the
invcommand prompts you to enter.Table 1: inv Command Options inv Command Prompts Description Kubernetes master nodes Enter IP addresses of the Kubernetes primary nodes. Kubernetes worker nodes Enter IP addresses of the Kubernetes worker nodes. Local storage nodes Define the nodes that have disk space available for applications. The local storage nodes are prepopulated with the IP addresses of the primary and worker nodes. You can edit these addresses. Enter IP addresses of the nodes on which you want to run applications that require local storage.
Services such as Postgres, ZooKeeper, and Kafka use local storage or disk space partitioned inside export/local-volumes. By default, worker nodes have local storage available. If you do not add primary nodes here, you can run only those applications that do not require local storage on the primary nodes.
Note:Local storage is different from Ceph storage.
Kubernetes nodes' username (for example, root) Configure the user account and authentication methods to authenticate the installer with the cluster nodes. The user account must be root or, in the case of non-root users, the account must have superuser (sudo) privileges. SSH private key file (optional) If you chose
ssh-keyauthentication, for the control host to authenticate with the nodes during the installation process, configure the directory ( config-dir ) where the ansible_ssh_private_key_file is located, and the id_rsa file, as "{{ config-dir }}/id_rsa".Kubernetes nodes' password (optional) If you chose password authentication for the control host to authenticate with the nodes during the installation process, enter the authentication password directly. WARNING: The password is written in plain text.
We do not recommend using this option for authentication.
Kubernetes cluster name (optional) Enter a name for your Kubernetes cluster. Write inventory file? Click
Yesto save the inventory information.For example:
$ ./run -c config-dir inv Loaded image: paragonautomation:latest ==================== PO-Runtime installer ==================== Supported command: deploy [-t tags] deploy runtime destroy [-t tags] destroy runtime init init configuration skeleton inv basic inventory editor conf basic configuration editor info [-mc] cluster installation info Starting now: inv INVENTORY This script will prompt for the DNS names or IP addresses of the Kubernetes master and worker nodes. Addresses should be provided as comma-delimited lists. At least three master nodes are recommended. The number of masters should be an odd number. A minimum of four nodes are recommended. Root access to the Kubernetes nodes is required. See https://docs.ansible.com/ansible/2.10/user_guide/intro_inventory.html ? Kubernetes master nodes 10.12.xx.x3,10.12.xx.x4,10.12.xx.x5 ? Kubernetes worker nodes 10.12.xx.x6 ? Local storage nodes 10.12.xx.x3,10.12.xx.x4,10.12.xx.x5,10.12.xx.x6 ? Kubernetes nodes' username (e.g. root) root ? SSH private key file (optional; e.g. "{{ inventory_dir }}/id_rsa") config/id_rsa ? Kubernetes nodes' password (optional; WARNING - written as plain text) ? Kubernetes cluster name (optional) k8scluster ? Write inventory file? Yes -
Alternatively, you can customize the inventory file manually using a text editor.
# vi config-dir/inventory
Edit the following groups in the inventory file.
-
Add the IP addresses of the Kubernetes primary and worker nodes of the cluster.
The
mastergroup identifies the primary nodes, and thenodegroup identifies the worker nodes. You cannot have the same IP address in bothmasterandnodegroups.To create a multi-primary node setup, list the addresses or hostnames of all the nodes that will be acting as primary nodes under the
mastergroup. Add the addresses or hostnames of the nodes that will be acting as worker nodes under thenodegroup.master: hosts: 10.12.xx.x3: {} 10.12.xx.x4: {} 10.12.xx.x5: {} node: hosts: 10.12.xx.x6: {} -
Define the nodes that have disk space available for applications under the
local_storage_nodes:childrengroup.local_storage_nodes: children: master: hosts: 10.12.xx.x3: {} 10.12.xx.x4: {} 10.12.xx.x5: {} node: hosts: 10.12.xx.x6: {} -
Configure the user account and authentication methods to authenticate the installer in the Ansible control host with the cluster nodes under the
varsgroup.vars: ansible_user: root ansible_ssh_private_key_file: config/id_rsa ansible_password: -
(Optional) Specify a name for your Kubernetes cluster in the
kubernetes_cluster_namegroup.kubernetes_cluster_name: k8scluster
-
-
-
Configure the installer using the
confcommand.# ./run -c config-dir conf
The
confcommand runs an interactive installation wizard that enables you to choose the components you want to install and configure a basic Paragon Automation setup. The command populates the config.yml file with your input configuration. For advanced configuration, you must edit the config.yml file manually.Enter the information as prompted by the wizard. Use the cursor keys to move the cursor, use the space key to select an option, and use the
aorikey to toggle selecting or clearing all options. Press Enter to move to the next configuration option. You can skip configuration options by entering a period (.). You can reenter all your choices by exiting the wizard and restarting from the beginning. The installer allows you to exit the wizard after you save the choices that you already made or to restart from the beginning. You cannot go back and redo the choices that you already made in the current workflow without exiting and restarting the wizard altogether.The following table lists the configuration options that the
confcommand prompts you to enter :Table 2: conf Command Options confCommand PromptsDescription/Options
Select components
You can install the Infrastructure, Pathfinder, Insights, and base platform components. By default, all components are selected.
You can choose to install Pathfinder based on your requirement. However, you must install all other components.
Infrastructure Options
These options appear only if you selected to install the Infrastructure component at the previous prompt.
-
Install Kubernetes Cluster—Install the required Kubernetes cluster. If you are installing Paragon Automation on an existing cluster, you can clear this selection.
-
Install MetalLB LoadBalancer—Install an internal load balancer for the Kubernetes cluster. By default, this option is already selected. If you are installing Paragon Automation on an existing cluster with preconfigured load balancing, you can clear this selection.
-
Install Nginx Ingress Controller—Install Nginx Ingress Controller is a load-balancing proxy for the Pathfinder components.
-
Install Chrony NTP Client—Install Chrony NTP. You need NTP to synchronize the clocks of the cluster nodes. If NTP is already installed and configured, you need not install Chrony. All nodes must run NTP or some other time-synchronization protocol at all times.
-
Allow Master Scheduling—Select to enable master scheduling. Master scheduling determines how the nodes acting as primary nodes are used. Master is another term for a node acting as primary.
If you select this option, the primary nodes can also act as worker nodes, which means they not only act as the control plane but can run application workloads as well. If you do not select master scheduling, the primary nodes are used only as the control plane.
Master scheduling allows the available resources of the nodes acting as primary to be available for workloads. However, if you select this option, a misbehaving workload might exhaust resources on the primary node and affect the stability of the whole cluster. Without master scheduling, if you have multiple primary nodes with high capacity and disk space, you risk wasting their resources by not utilizing them completely.
Note:This option is required for Ceph storage redundancy.
List of NTP servers
Enter a comma-separated list of NTP servers. This option is displayed only if you chose to install Chrony NTP.
Virtual IP address (es) for ingress controller
Enter a VIP address to be used for Web access of the Kubernetes cluster or the Paragon Automation UI. This must be an unused IP address that is managed by the MetalLB load balancer pool.
Virtual IP address for Infrastructure Nginx Ingress Controller Enter a VIP address for the Nginx Ingress Controller. This must be an unused IP address that is managed by the MetalLB load balancer pool. This address is used for NetFlow traffic.
Virtual IP address for Insights services
Enter a VIP address for Paragon Insights services. This must be an unused IP address that is managed by the MetalLB load balancer pool.
Virtual IP address for SNMP trap receiver (optional) Enter a VIP address for the SNMP trap receiver proxy only if this functionality is required. If you do not need this option, enter a period (.).
Pathfinder Options Select to install Netflowd. You can configure a VIP address for netflowd or use a proxy for netflowd (same as the VIP address for the Infrastructure Nginx Ingress Controller). If you choose to not install netflowd, you cannot configure a VIP address for netflowd.
Use netflowd proxy Enter Yto use a netflowd proxy. This option appears only if you chose to install netflowd.If you chose to use a netflowd proxy, you needn't configure a VIP address for netflowd. The VIP address for the Infrastructure Nginx Ingress Controller is used as the proxy for netflowd.
Virtual IP address for Pathfinder Netflowd Enter a VIP address to be used for Paragon Pathfinder netflowd. This option appears only if you chose not to use netflowd proxy. PCE Server Proxy Select the proxy mode for the PCE server. Select from NoneandNginx-Ingress.Virtual IP address for Pathfinder PCE server Enter a VIP address to be used for Paragon Pathfinder PCE server access. This address must be an unused IP address that is managed by the load balancer.
If you selected Nginx-Ingress, as the PCE Server Proxy, this VIP address is not necessary. The wizard does not prompt you to enter this address and PCEP will use the same address as the VIP address for Infrastructure Nginx Ingress Controller.
Note:The addresses for ingress controller, Infrastructure Nginx Ingress Controller, Insights services, and PCE server must be unique. You cannot use the same address for all four VIP addresses.
All these addresses are listed automatically in the LoadBalancer IP address ranges option.
LoadBalancer IP address ranges
The LoadBalancer IP addresses are prepopulated from your VIP addresses range. You can edit these addresses. The externally accessible services are handled through MetalLB, which needs one or more IP address ranges that are accessible from outside the cluster. VIPs addresses for the different servers are selected from these ranges of addresses.
The address ranges can be (but need not be) in the same broadcast domain as the cluster nodes. For ease of management, because the network topologies need access to Insights services and the PCE server clients, we recommend that you select the VIP addresses from the same range.
For more information, see Virtual IP Address Considerations.
Addresses can be entered as comma-separated values (CSV), as a range, or as a combination of both. For example:
-
10.x.x.1, 10.x.x.2, 10.x.x.3
-
10.x.x.1-10.x.x.3
-
10.x.x.1, 10.x.x.3-10.x.x.5
-
10.x.x.1-3 is not a valid format.
Multi-master node detected do you want to setup multiple registries Enter
yto configure a configure registry on each primary node.You see this option only if you've configured multiple primary nodes in the inventory file (multi-primary installation).
Virtual IP address for registry
Enter a VIP address for the container registry for a multi-primary node deployment only. Make sure that the VIP address is in the same Layer 2 domain as the primary nodes. This VIP address is not part of the LoadBalancer pool of VIP addresses.
You see this option only if you chose to configure multiple container registries.
Enable md5 for PCE Server
Enter Yto configure MD5 authentication between the router and Pathfinder.Note:If you enable MD5 on PCEP sessions, you must also configure the authentication key in the Paragon Automation UI and the same authentication key and the VIP address on the router. For information on how to configure the authentication key and VIP address, see VIP Addresses for MD5 Authentication.
IP for PCEP server (must be outside metallb range and must be in the same subnet as the host with its subnet prefix in CIDR notation)
Enter a VIP address for the PCE server. The IP address must in the CIDR format.
Make sure that the VIP address is in the same Layer 2 domain as the primary nodes. This VIP address is not part of the LoadBalancer pool of VIP addresses.
Enable md5 for BGP
Enter Yto configure MD5 authentication between cRPD and the BGP-LS router.IP for CRPD (must be outside metallb range and must be in the same subnet as the host with its subnet prefix in CIDR notation)
Enter a VIP address for the BGP Monitoring Protocol (BMP) pod. The IP address must in the CIDR format.
Make sure that the VIP address is in the same Layer 2 domain as the primary nodes. This VIP address is not part of the LoadBalancer pool of VIP addresses.
Note:If you enable MD5 on cRPD sessions, you must also configure the router to enable MD5 for cRPD and configure the VIP address on the router. For information on how to determine the MD5 authentication key and configure the router, see VIP Addresses for MD5 Authentication.
To determine the
crpd-md5-key, check thecrpd_auth_keyparameter in the config.yml file, after running theconfcommand. For example:crpd_auth_key : northstar. If there is a key present, it indicates that cRPD is configured for MD5. You can use the key present in the config.yml file (or you can also edit the key) and enter it on the router.If no key is present in the config.ymlfile, you must log in to cRPD and set the authentication key using one of the following commands:
set groups extra protocols bgp group name authentication-key crpd-md5-keyor
set protocols bgp group name authentication-key crpd-md5-keyThe MD5 authentication key must be less than or equal to 79 characters. The same key must be entered in cRPD and on the router.
Multus Interface
Enter the Multus interface type.
Multus Destination routes ? can be more than 1 peer with its subnet prefix in CIDR notation
Enter the Multus routes in the CIDR format.
Multus Gateway IP address
Enter the IP address of the Multus gateway.
Hostname of Main web application
Enter a hostname for the ingress controller. You can configure this value as an IP address or as a fully qualified domain name (FQDN). For example, you can enter 10.12.xx.100 or www.paragon.juniper.net (DNS name). Do not include http:// or https://.
Note:You will use this hostname to access the Paragon Automation Web UI from your browser. For example, https://hostname or https://IP-address.
BGP autonomous system number of CRPD peer
Set up the Containerized Routing Protocol Daemon (cRPD) autonomous systems and the nodes with which cRPD creates its BGP sessions.
You must configure the autonomous system (AS) number of the network to allow cRPD to peer with one or more BGP Link State (BGP-LS) routers in the network. By default, the AS number is 64500.
Note:While you can configure the AS number at the time of installation, you can also modify the cRPD configuration later. See Modify cRPD Configuration .
Comma separated list of CRPD peers
Configure cRPD to peer with at least one BGP-LS router in the network to import the network topology. For a single autonomous system, configure the address of the BGP-LS routers that will peer with cRPD to provide topology information to Paragon Pathfinder. The cRPD instance running as part of a cluster will initiate a BGP-LS connection to the specified peer routers and import topology data after the session is established. If more than one peer is required, you can add the peers as CSVs, as a range, or as a combination of both, similar to how you add LoadBalancer IP addresses.
Note:While you can configure the peer IP addresses at the time of installation, you can also modify the cRPD configuration later, as described in Modify cRPD Configuration.
You must configure the BGP peer routers to accept BGP connections initiated from cRPD. The BGP session will be initiated from cRPD using the address of the worker where the bmp pod is running as the source address.
Because cRPD could be running on any of the worker nodes at a given time, you must allow connections from any of these addresses. You can allow the range of IP addresses that the worker addresses belong to (for example, 10.xx.43.0/24), or the specific IP address of each worker (for example, 10.xx.43.1/32, 10.xx.43.2/32, and 10.xx.43.3). You could also configure this using the
neighborcommand with thepassiveoption to prevent the router from attempting to initiate the connection.If you chose to enter each individual worker address, either with the
allowcommand or theneighborcommand, make sure you include all the workers, because any worker could be running cRPD at a given time. Only one BGP session will be initiated. If the node running cRPD fails, the bmp pod that contains the cRPD container will be created in a different node, and the BGP session will be re-initiated.The sequence of commands in the following example shows the options to configure a Juniper device to allow BGP-LS connections from cRPD.
The following commands configure the router to accept BGP-LS sessions from any host in the 10.xx.43.0/24 network, where all the worker nodes are connected.
[edit groups northstar] root@system# show protocols bgp group northstar type internal; family traffic-engineering { unicast; } export TE; allow 10.xx.43.0/24; [edit groups northstar] root@system# show policy-options policy-statement TE from family traffic-engineering; then accept;The following commands configure the router to accept BGP-LS sessions from 10.xx.43.1, 10.xx.43.2, and 10.xx.43.3 (the addresses of the three workers in the cluster) only.
[edit protocols bgp group BGP-LS] root@vmx101# show | display set set protocols bgp group BGP-LS family traffic-engineering unicast set protocols bgp group BGP-LS peer-as 11 set protocols bgp group BGP-LS allow 10.x.43.1 set protocols bgp group BGP-LS allow 10.x.43.2 set protocols bgp group BGP-LS allow 10.x.43.3 set protocols bgp group BGP-LS export TE
cRPD initiates the BGP session. Only one session is established at a time and is initiated using the address of the worker node currently running cRPD. If you choose to configure the specific IP addresses instead of using the
allowoption, configure the addresses of all the workers nodes for redundancy.The following commands also configure the router to accept BGP-LS sessions from 10.xx.43.1, 10.xx.43.2, and 10.xx.43.3 only (the addresses of the three workers in the cluster). The
passiveoption prevents the router from attempting to initiate a BGP-LS session with cRPD. The router will wait for the session to be initiated by any of these three routers.[edit protocols bgp group BGP-LS] root@vmx101# show | display set set protocols bgp group BGP-LS family traffic-engineering unicast set protocols bgp group BGP-LS peer-as 11 set protocols bgp group BGP-LS neighbor 10.xx.43.1 set protocols bgp group BGP-LS neighbor 10.xx.43.2 set protocols bgp group BGP-LS neighbor 10.xx.43.3 set protocols bgp group BGP-LS passive set protocols bgp group BGP-LS export TE
You will also need to enable OSPF/IS-IS and MPLS traffic engineering as shown here:
set protocols rsvp interface interface.unit set protocols isis interface interface.unit set protocols isis traffic-engineering igp-topology Or set protocols ospf area area interface interface.unit set protocols ospf traffic-engineering igp-topology set protocols mpls interface interface.unit set protocols mpls traffic-engineering database import igp-topologyFor more information, see https://www.juniper.net/documentation/us/en/software/junos/mpls/topics/topic-map/mpls-traffic-engineering-configuration.html.
Finish and write configuration to file Click Yesto save the configuration information.This action configures a basic setup and saves the information in the config.yml file in the config-dir directory.
$ ./run -c config conf Loaded image: paragonautomation.latest ==================== PO-Runtime installer ==================== Supported command: deploy [-t tags] deploy runtime destroy [-t tags] destroy runtime init init configuration skeleton inv basic inventory editor conf basic configuration editor info [-mc] cluster installation info Starting now: conf NOTE: depending on options chosen additional IP addresses may be required for: multi-master Kubernetes Master Virtual IP address Infrastructure Virtual IP address(es) for ingress controller Infrastructure Virtual IP address for Infrastructure Nginx Ingress Cont roller Insights Virtual IP address for Insights services Insights Virtual IP address for SNMP Trap receiver (optional) Pathfinder Virtual IP address for Pathfinder Netflowd Pathfinder Virtual IP address for Pathfinder PCE server multi-registry Paragon External Registry Virtual IP address ? Select components done (4 selections) ? Infrastructure Options done (4 selections) ? List of NTP servers 0.pool.ntp.org ? Virtual IP address(es) for ingress controller 10.12.xx.x7 ? Virtual IP address for Insights services 10.12.xx.x8 ? Virtual IP address for SNMP Trap receiver (optional) ? Pathfinder Options [Install Netflowd] ? Use netflowd proxy? Yes ? PCEServer proxy Nginx Ingress ? LoadBalancer IP address ranges 10.12.xx.x7-10.12.xx.x9 ? Multi-master node detected do you want to setup multiple registries Yes ? Virtual IP address for registry 10.12.xx.10 ? Enable md5 for PCE Server ? Yes ? IP for PCEP server (must be outside metallb range and must be in the same subnet as the host with its subnet prefix in CIDR notation) 10.12.xx.219/24 ? Enable md5 for BGP ? Yes ? IP for CRPD (must be outside metallb range and must be in the same subnet as the host with its subnet prefix in CIDR notation) 10.12.xx.220/24 ? Multus Interface ? eth1 ? Multus Destination routes ? can be more than 1 peer with its subnet prefix in CIDR notation 10.12.xx.41/24,10.13.xx.21/24 ? Multus Gateway IP Address ? 10.12.xx.101 ? Hostname of Main web application host.example.net ? BGP autonomous system number of CRPD peer 64500 ? Comma separated list of CRPD peers 10.12.xx.11 ? Finish and write configuration to file Yes -
-
(Optional) For more advanced configuration of the cluster, use a text
editor to manually edit the config.yml file.
The config.yml file consists of an essential section at the beginning of the file that corresponds to the configuration options that the installation wizard prompts you to enter. The file also has an extensive list of sections under the essential section that allows you to enter complex configuration values directly in the file.
You can configure the following options:
-
(Optional) Set the
grafana_admin_passwordpassword to log in to the Grafana application. Grafana is a visualization tool commonly used to visualize and analyze data from various sources, including logs.By default, the username is preconfigured as admin in
# grafana_admin_user: admin. Use admin as username and the password you configure to log in to Grafana.grafana_admin_user: admin grafana_admin_password: grafana_passwordIf you do not configure the
grafana_admin_passwordpassword, the installer generates a random password. You can retrieve the password using the command:# kubectl get secret -n kube-system grafana -o jsonpath={..grafana-password} | base64 -d -
Set the
iam_skip_mail_verificationconfiguration option to true for user management without SMTP by Identity and Access Management (IAM). By default, this option is set to false for user management with SMTP. You must configure SMTP in Paragon Automation so that you can notify Paragon Automation users when their account is created, activated, or locked, or when their account password is changed. -
Configure the
callback_vipoption with an IP address different from that of the virtual IP (VIP) address of the ingress controller. You can use an IP address from the MetalLB pool of VIP addresses. You configure this IP address to enable segregation of management and data traffic from the southbound and northbound interfaces. By default,callback_vipis assigned the same or one of the addresses of the ingress controller.
Save and exit the file after you finish editing it.
-
-
(Optional) If you want to deploy custom SSL certificates signed by a
recognized certificate authority (CA), store the private key and certificate
in the
config-dir
directory. Save
the private key as ambassador.key.pem and the
certificate as ambassador.cert.pem.
By default, Ambassador uses a locally generated certificate signed by the Kubernetes cluster-internal CA.
Note:If the certificate is about to expire, save the new certificate as ambassador.cert.pem in the same directory, and execute the
./run -c config-dir deploy -t ambassadorcommand. -
Install the Paragon Automation cluster based on the information that you
configured in the config.yml and
inventory files.
# ./run -c config-dir deploy
The installation time to install the configured cluster depends on the complexity of the cluster. A basic setup installation takes at least 45 minutes to complete.
The installer checks NTP synchronization at the beginning of installation. If clocks are out of sync, installation fails.
For multi-primary node deployments only, the installer checks both individual server CPU and memory as well as total available CPU and memory per cluster. If the following requirements are not met, installation fails.
-
Minimum CPU per cluster: 20 CPU
-
Minimum Memory per cluster: 32-GB
-
Minimum CPU per node: 4 CPU
-
Minimum memory per node: 6-GB
To disable CPU and memory check, use the following command and rerun the deployment.
# ./run -c config-dir deploy -e ignore_iops_check=yesIf you are installing Paragon Automation on an existing Kubernetes cluster, the
deploycommand upgrades the currently deployed cluster to the latest Kubernetes version. The command also upgrades the Docker CE version, if required. If Docker EE is already installed on the nodes, thedeploycommand does not overwrite it with Docker CE. When upgrading the Kubernetes version or the Docker version, the command performs the upgrade sequentially on one node at a time. The command cordons off each node and removes it from scheduling. It performs upgrades, restarts Kubernetes on the node, and finally uncordons the node and brings it back into scheduling. -
-
After deployment is completed, log in to the worker nodes.
Use a text editor to configure the following recommended information for Paragon Insights in the limits.conf and sysctl.conf files. These values set the soft and hard memory limits for influx DB memory requirements. If you do not set these limits, you might see errors such as “out of memory” or “too many open files” because of the default system limits.
-
# vi /etc/security/limits.conf # End of file * hard nofile 1048576 * soft nofile 1048576 root hard nofile 1048576 root soft nofile 1048576 influxdb hard nofile 1048576 influxdb soft nofile 1048576 -
# vi /etc/sysctl.conf fs.file-max = 2097152 vm.max_map_count=262144 fs.inotify.max_user_watches=524288 fs.inotify.max_user_instances=512
Repeat this step for all worker nodes.
-
Now that you've installed and deployed your Paragon Automation cluster, you're ready to log in to the Paragon Automation UI.
Log in to the Paragon Automation UI
To log in to the Paragon Automation UI:
-
Open a browser, and enter either the hostname of the main Web application
or the VIP address of the ingress controller that you entered in the URL
field of the installation wizard.
For example, https://vip-of-ingress-controller-or-hostname-of-main-web-application . The Paragon Automation login page is displayed.
-
For first-time access, enter admin as username and
Admin123! as the password to log in. You must
change the password immediately.
The Set Password page appears. To access the Paragon Automation setup, you must set a new password.
-
Set a new password that meets the password requirements.
Use between 6 and 20 characters and a combination of uppercase letters, lowercase letters, numbers, and special characters. Confirm the new password, and click OK.The Dashboard page appears. You have successfully installed and logged in to the Paragon Automation UI.
-
Update the URL to access the Paragon Automation UI in
Administration > Authentication > Portal
Settings to ensure that the activation e-mail sent to users
for activating their account contains the correct link to access the GUI.
For more information, see Configure
Portal Settings.
For high-level tasks that you can perform after you log in to the Paragon Automation UI, see Paragon Automation Quick Start - Up and Running.