NorthStar Controller System Requirements
The NorthStar Controller runs on Linux systems running or Red Hat Enterprise Linux (RHEL).
Ensure that:
You use a Juniper-validated version of CentOS Linux or Red Hat Enterprise Linux (RHEL). These are our Linux recommendations:
-
CentOS Linux 7.x or RHEL 7.x (7.6, 7.7, 7.9), or 8.x (8.4, 8.10) image. Earlier versions are not supported.
Note:If you use RHEL 8.x (8.4, 8.10), ensure that you:
-
Install legacy network scripts and tools by running the following command:
yum -y install net-tools bridge-utils ntp wget ksh telnet java-1.8.0-openjdk-headless network-scripts -
Remove the following RPM bundles:
rpm -e buildah cockpit-podman podman-catatonit podmanyum -y remove runc-1:1.1.12-5.module+el8.10.0+22346+28c02849.x86_64 -
If you use RHEL 8.10, ensure that you disable Reverse Path Filtering (RPF) on the interface where JTI packets are received. See Analytics Requirements.
-
Install your choice of supported Linux version using the minimal ISO.
-
You use RAM, number of virtual CPUs, and hard disk specified in Server Sizing Guidance for your installation.
You open the ports listed in Firewall Port Guidance.
When upgrading NorthStar Controller, files are backed up to the /opt directory.
Server Sizing Guidance
The guidance in this section should help you to configure your servers with sufficient resources to efficiently and effectively support the NorthStar Controller functions. The recommendations in this section are the result of internal testing combined with field data.
A typical NorthStar deployment contains the following systems:
An application system
The application system contains the path computation element (PCE), the path computation server (PCS), the components for Web access, topology acquisition, CLI or SNMP message collection and, a configuration database.
An analytics system
The analytics system is used for telemetry and collecting NetFlow data, and contains the analytics database. The analytics system is used in deployments tracking traffic levels of a network.
(Optional) A dedicated or secondary collector
A secondary collector is used for collecting CLI and SNMP messages from large nodes and is needed when there is a need for a heavy collection of data; see Table 2.
(Optional) A dedicated planner node
A planner node is required for running offline network simulation on a system other than the application system; see Table 2.
For high availability deployments, described in Configuring a NorthStar Cluster for High Availability, a cluster would have 3 or more application and analytics systems, but they would be sized similarly to a deployment with a single application system and a single analytics system.
Table 1 outlines the estimated server requirements of the application and analytics systems by network size.
Instance Type |
POC/LAB (RAM / vCPU / HDD) |
Medium (<75 nodes) (RAM / vCPU / HDD) |
Large (<300 nodes) (RAM / vCPU / HDD) |
XL (300+ nodes)* (RAM / vCPU / HDD) |
|---|---|---|---|---|
Application |
16G / 4vCPU / 500G |
64G / 8vCPU / 1T |
96G / 8vCPU / 1.5T |
128G / 8vCPU / 2T |
For collecting a large number of SNMP and CLI messages on a single, non-high availability (HA) system, you may require additional 16GB RAM and 8 vCPUs or a secondary collector; see Table 2. |
||||
Analytics |
16G/ 4vCPU/ 500G |
48G / 6vCPU/ 1T |
64G / 8vCPU/ 2T |
64G / 12vCPU / 3T |
NetFlow deployments may require additional 16G to 32G RAM and doubling of the virtual CPUs on the analytics system. |
||||
Note:
Based on the number of devices in your network, check with your Juniper Networks representative to confirm your specific requirements for networks in the XL category. |
||||
Table 2 outlines the estimated server requirements for the secondary collectors and dedicated planner.
Instance Type |
POC/LAB (RAM / vCPU / HDD) |
Medium (<75 nodes) (RAM / vCPU / HDD) |
Large (<300 nodes) (RAM / vCPU / HDD) |
XL (300+ nodes) (RAM / vCPU / HDD) |
|---|---|---|---|---|
All-In-One |
24G / 8vCPU/ 1T |
Not applicable |
Not applicable |
Not applicable |
Secondary Collectors |
8G / 4vCPU / 200G |
16G / 8vCPU / 500G |
16G / 8vCPU / 500G |
16G / 8vCPU / 500G |
Dedicated Planner |
8G / 4vCPU / 200G |
16G / 8vCPU / 1T |
16G / 8vCPU / 1T |
16G / 8vCPU / 1T |
Additional RAM may be necessary based on the number of active planner sessions and complexity of models. |
||||
Note:
All-In-One is a configuration, where all the components are installed in a single virtual machine, is intended only for demonstration purposes. It is not recommended for production deployments or lab configurations intended to model production deployments. |
||||
When installing the minimal installation CentOS or RHEL Linux, the filesystems can be collapsed to a single root (/) filesystem or separate filesystems. If you are using separate filesystems, you can assign space for each customer according to the size mentioned in Table 3 for the different directories.
Filesystem |
Space Requirement |
Purpose |
|---|---|---|
/boot |
1G |
Linux kernel and necessary files for boot |
swap |
0 to 4G |
Not needed, but can have minimal configuration |
/ |
10G |
Operating system (including /usr) |
/var/lib/docker |
20G |
Containerized processes (application system only) |
/tmp |
24G |
NorthStar debug files in case of process error (application system only) |
/opt |
Remaining space in the filesystem |
NorthStar components |
- Additional Disk Space for JTI Analytics in ElasticSearch
- Additional Disk Space for Network Events in Cassandra
- Collector (Celery) Memory Requirements
Additional Disk Space for JTI Analytics in ElasticSearch
Considerable storage space is needed to support JTI analytics in ElasticSearch. Each JTI record event requires approximately 330 bytes of disk space. A reasonable estimate of the number of events generated is (<num-of-interfaces> + <number-of-LSPs>) ÷ reporting-interval-in-seconds = events per second.
So for a network with 500 routers, 50K interfaces, and 60K LSPs, with a configured five-minute reporting interval (300 seconds), you can expect something in the neighborhood of 366 events per second to be generated. At 330 bytes per event, it comes out to 366 events x 330 bytes x 86,400 seconds in a day = over 10G of disk space per day or 3.65T per year. For the same size network, but with a one-minute reporting interval (60 seconds), you would have a much larger disk space requirement—over 50G per day or 18T per year.
There is an additional roll-up event created per hour per element for data aggregation. In a network with 50K interfaces and 60K LSPs (total of 110K elements), you would have 110K roll-up events per hour. In terms of disk space, that would be 110K events per hour x 330 bytes per event x 24 hours per day = almost 1G of disk space required per day.
For a typical network of about 100K elements (interfaces + LSPs), we recommend that you allow for an additional 11G of disk space per day if you have a five-minute reporting interval, or 51G per day if you have a one-minute reporting interval.
See NorthStar Analytics Raw and Aggregated Data Retention in the NorthStar Controller User Guide for information about customizing data aggregation and retention parameters to reduce the amount of disk space required by ElasticSearch.
Additional Disk Space for Network Events in Cassandra
The Cassandra database is another component that requires additional disk space for storage of network events.
Using that same example of 50K interfaces and 60K LSPs (110 elements) and estimating one event every 15 minutes (900 seconds) per element, there would be 122 events per second. The storage needed would then be 122 events per second x 300 bytes per event x 86,400 seconds per day = about 3.2 G per day, or 1.2T per year.
Using one event every 5 minutes per element as an estimate instead of every 15 minutes, the additional storage requirement is more like 9.6G per day or 3.6T per year.
For a typical network of about 100K elements (interfaces + LSPs), we recommend that you allow for an additional 3-10G of disk space per day, depending on the rate of event generation in your network.
By default, NorthStar keeps event history for 35 days. To customize the number of days event data is retained:
Modify the dbCapacity parameter in
/opt/northstar/data/web_config.jsonRestart the pruneDB process using the
supervisorctl restart infra:prunedbcommand.
Collector (Celery) Memory Requirements
When you use the collector.sh script to install secondary collectors on a server separate from the NorthStar application (for distributed collection), the script installs the default number of collector workers described in Table 4. The number of celery processes started by each worker is the number of cores in the CPU plus one. So in a 32-core server (for example), the one installed default worker would start 33 celery processes. Each celery process uses about 50M of RAM.
|
CPU Cores |
Workers Installed |
Total Worker Processes |
Minimum RAM Required |
|---|---|---|---|
|
1-4 |
4 |
20 (CPUs +1) x 4 = 20 |
1 GB |
|
5-8 |
3 |
18 (CPUs +1) x 2 = 18 |
1 GB |
|
16 |
1 |
17 (CPUs +1) x 1 = 17 |
1 GB |
|
32 |
1 |
33 (CPUs +1) x 1 = 33 |
2 GB |
See Secondary Collector Installation for Distributed Data Collection for more information about distributed data collection and secondary workers.
The default number of workers installed is intended to optimize server resources, but you can change the number by using the provided config_celery_workers.sh script. See Collector Worker Installation Customization for more information. You can use this script to balance the number of workers installed with the amount of memory available on the server.
This script is also available to change the number of workers installed on the NorthStar application server from the default, which also follows the formulas shown in Table 4.
Firewall Port Guidance
The ports listed in Table 5 must be allowed by any external firewall being used. The ports with the word cluster in their purpose descriptions are associated with high availability (HA) functionality. If you are not planning to configure an HA environment, you can ignore those ports. The ports with the word Analytics in their purpose descriptions are associated with the Analytics feature. If you are not planning to use Analytics, you can ignore those ports. The remaining ports listed must be kept open in all configurations.
Port |
Purpose |
|---|---|
179 |
BGP: JunosVM or cRPD for router BGP-LS—not needed if IGP is used for topology acquisition. In a cRPD installation, the router connects port 179/TCP (BGP) directly to the NorthStar application server. cRPD runs as a process inside the NorthStar application server. Junos VM and cRPD are mutually exclusive. |
161 |
SNMP |
450 |
NTAD |
830 |
NETCONF communication between NorthStar Controller and routers. This is the default port for NETCONFD, but in some installations, port 22 is preferred. To change to port 22, access the NorthStar CLI as described in Configuring NorthStar Settings Using the NorthStar CLI, and modify the value of the port setting. Use the set northstar netconfd device-connection-pool netconf port command. |
1514 |
Syslog: Default Junos Telemetry Interface reports for RPM probe statistics (supports Analytics) |
1812 |
RADIUS authentication |
2222 |
Containerized Management Daemon (cMGD). Used to access NorthStar CLI. |
2888 |
Zookeeper cluster |
3000 |
JTI: Default Junos Telemetry Interface reports for IFD, IFL, and LSP (supports NorthStar Analytics). In previous NorthStar releases, three JTI ports were required (2000, 2001, 2002). Starting with Release 4.3.0, this single port is used instead. |
3001 |
Model Driven Telemetry (MDT) |
3100 |
Streaming telemetry for Ericsson. |
3888 |
Zookeeper cluster |
4000 |
MDT (pipeline) - Logstash communication |
4189 |
PCEP: PCC (router) to NorthStar PCE server |
5000 |
cMGD-REST |
5672 |
RabbitMQ |
6379 |
Redis |
7000 |
Communications port to NorthStar Planner |
7001 |
Cassandra database cluster |
8123 |
Health Monitor notification when the NorthStar controller and analytics are installed on different servers; |
8124 |
Health Monitor |
8443 |
Web: Web client/REST to secure web server (https) |
9000 |
Netflow |
9042 |
Remote Planner Server |
9200 |
Elasticsearch API calls (monitoring, search, and aggregation) over HTTP. |
9201 |
Elasticsearch when NorthStar controller and analytics server are installed on separate servers. |
9300 |
Elasticsearch cluster |
10001 |
BMP passive mode: By default, the monitor listens on this port for incoming connections from the network. |
17000 |
Cassandra database cluster |
50051 |
PRPD: NorthStar application to router network |
Figure 1 details the direction of data flow through the ports, when node clusters are not being used. Figure 2 and Figure 3 detail the additional flows for NorthStar application HA clusters and analytics HA clusters, respectively.
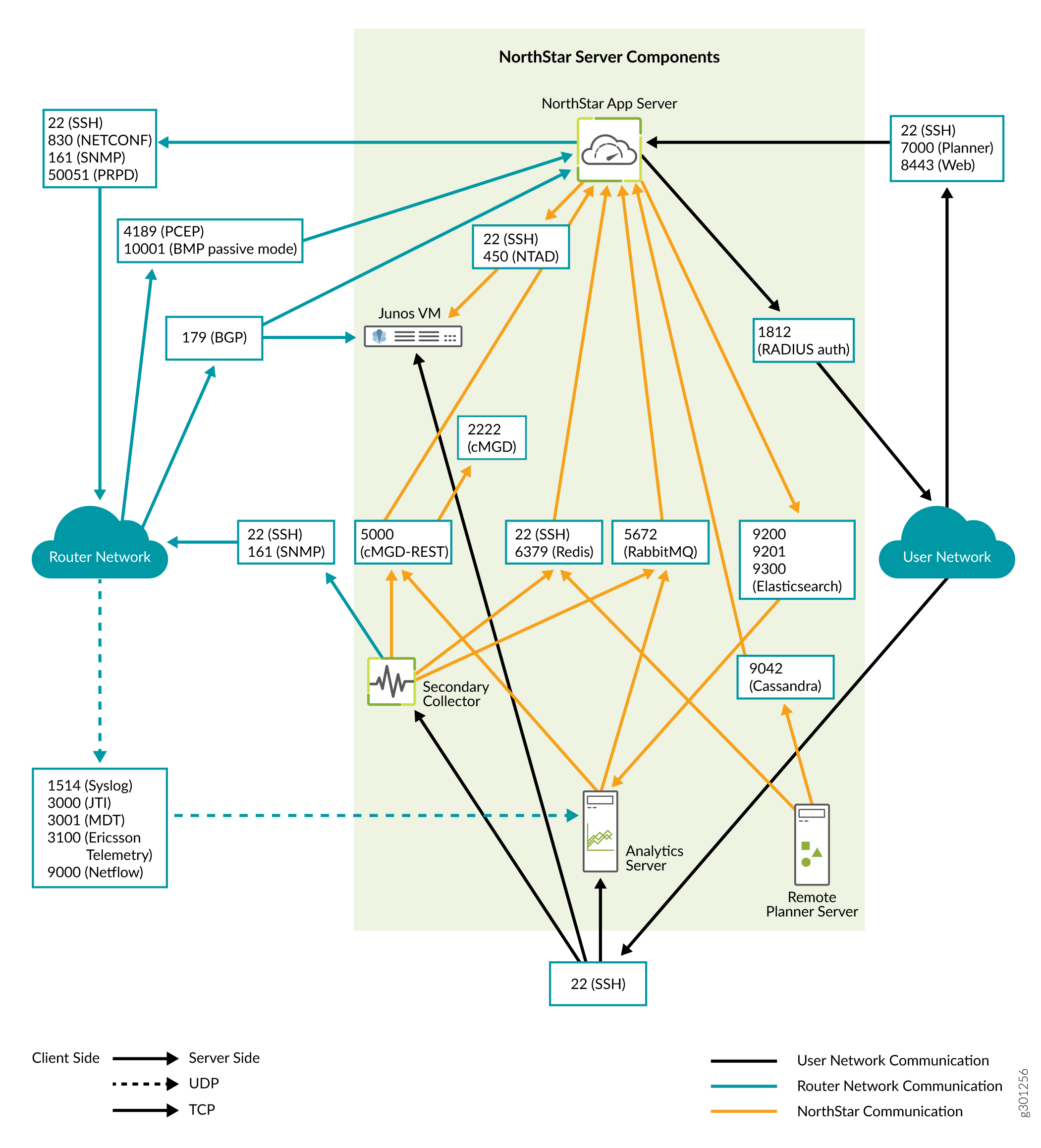
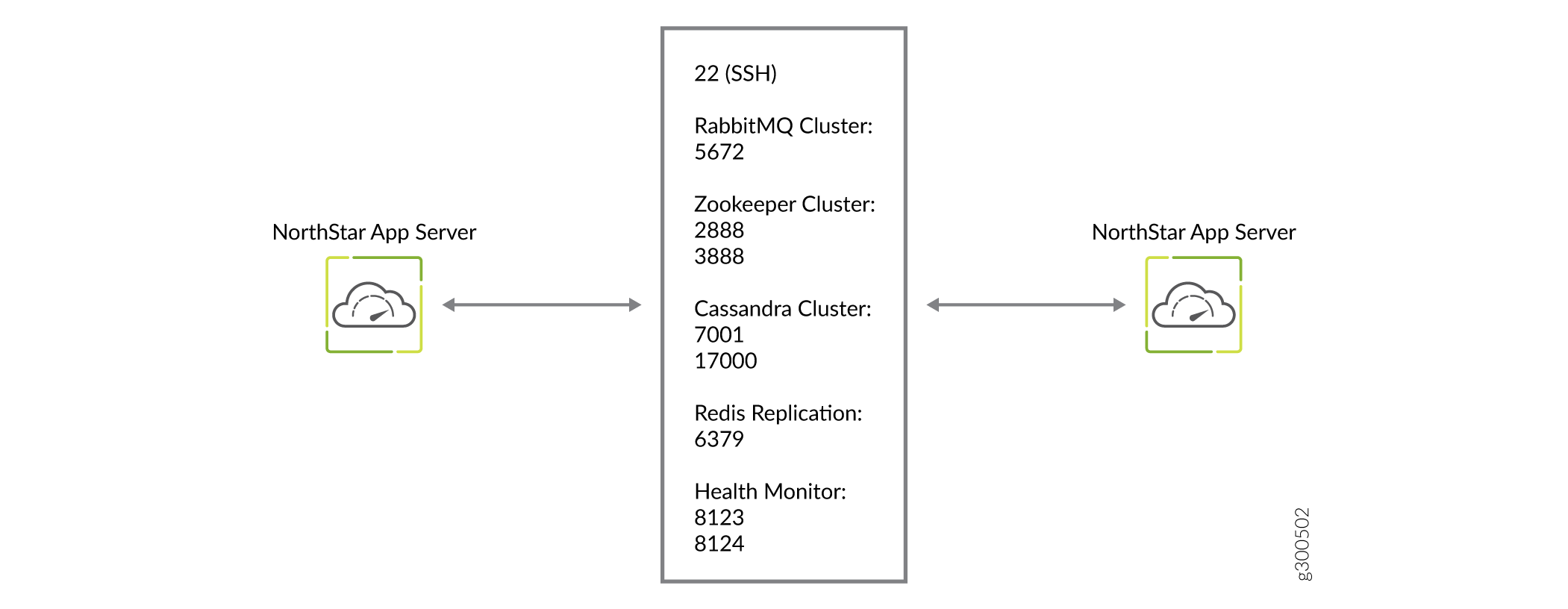
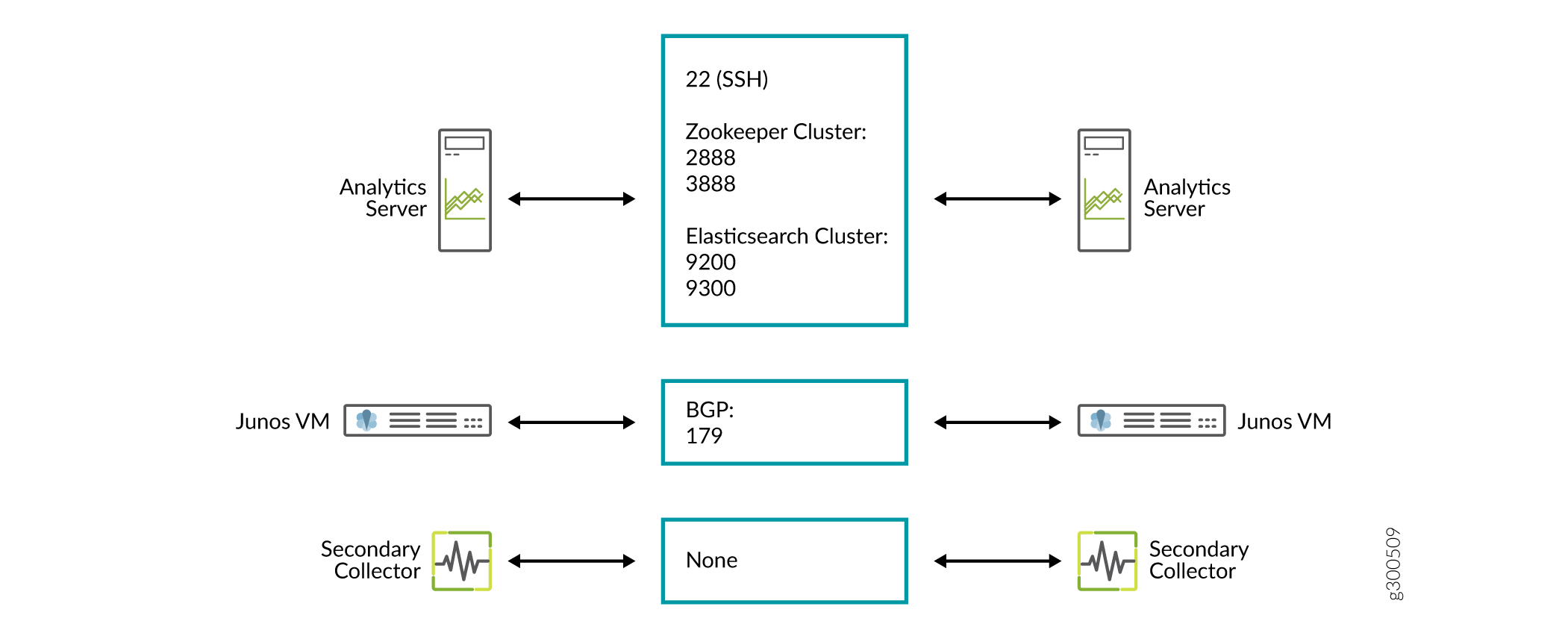
Analytics Requirements
In addition to ensuring that ports 3000 and 1514 are kept open, using the NorthStar analytics features requires that you counter the effects of Reverse Path Filtering (RPF) if necessary. If your kernel does RPF by default, you must do one of the following to counter the effects:
-
Disable RPF.
-
Ensure there is a route to the source IP address of the probes pointing to the interface where those probes are received.
-
Specify loose mode reverse filtering (if the source address is routable with any of the routes on any of the interfaces).
If you use RHEL 8.10, ensure that you disable Reverse Path Filtering (RPF) on the interface where JTI packets are received.
The following commands are examples of how you can disable RPF:
sysctl -w net.ipv4.conf.all.rp_filter=0 sysctl -w net.ipv4.conf.ens3f0.rp_filter=0 sysctl -w net.ipv4.conf.ens3f2.rp_filter=0
Two-VM Installation Requirements
A two-VM installation is one in which the JunosVM is not bundled with the NorthStar Controller software.
VM Image Requirements
The NorthStar Controller application VM is installed on top of a Linux VM, so Linux VM is required. You can obtain a Linux VM image in either of the following ways:
Use the generic version provided by most Linux distributors. Typically, these are cloud-based images for use in a cloud-init-enabled environment, and do not require a password. These images are fully compatible with OpenStack.
Create your own VM image. Some hypervisors, such as generic DVM, allow you to create your own VM image. We recommend this approach if you are not using OpenStack and your hypervisor does not natively support cloud-init.
The JunosVM is provided in Qcow2 format when inside the NorthStar Controller bundle. If you download the JunosVM separately (not bundled with NorthStar) from the NorthStar download site, it is provided in VMDK format.
The JunosVM image is only compatible with IDE disk controllers. You must configure the hypervisor to use IDE rather than SATA controller type for the JunosVM disk image.
glance image-update --property hw_disk_bus=ide --property hw_cdrom_bus=ide
JunosVM Version Requirements
If you have, and want to continue using a version of JunosVM older than Release 17.2R1, you can change the NorthStar configuration to support it, but segment routing support would not be available. See Installing the NorthStar Controller for the configuration steps.
VM Networking Requirements
The following networking requirements must be met for the two-VM installation approach to be successful:
Each VM requires the following virtual NICs:
One connected to the external network
One for the internal connection between the NorthStar application and the JunosVM
One connected to the management network if a different interface is required between the router facing and client facing interfaces
We recommend a flat or routed network without any NAT for full compatibility.
A virtual network with one-to-one NAT (usually referenced as a floating IP) can be used as long as BGP-LS is used as the topology acquisition mechanism. If IS-IS or OSPF adjacency is required, it should be established over a GRE tunnel.
Note:A virtual network with n-to-one NAT is not supported.