ON THIS PAGE
Time Series Database (TSDB) Overview
Paragon Insights collects a lot of time-sensitive data through its various ingest methods. This is why Paragon Insights uses a time-series database (TSDB) to store and manage all of the information received from the various network devices. This topic provides an overview of the TSDB.
Paragon Insights Microservice
Paragon Insights uses Kubernetes for clustering its docker-based
microservices across multiple physical or virtual servers (nodes).
Kubernetes clusters consist of a primary node and multiple worker
nodes. During the Healthbot setup portion of Paragon Insights
multinode installations, the installer asks for the IP addresses
(or hostnames) of the Kubernetes primary node and worker nodes. You
can add as many worker nodes to your setup as you need. However, the
number of nodes you add must be more than the value of the replication
factor.
TSDB Elements
Paragon Insights supports the following TSDB elements to provide TSDB high availability (HA).
Database Sharding
Database sharding refers to selectively storing data on certain nodes. This method distributes the data among available TSDB nodes and permits greater scaling. This ensures that a TSDB instance handles only a portion of the time series data from the devices.
To achieve sharding, Paragon Insights creates one database per device group/device pair and writes the resulting database to a system determined instance of TSDB hosted on one (or more) of the Paragon Insights nodes.
For example, consider that we have two devices, D1 and D2, and two device groups, G1 and G2. If D1 resides in groups G1 and G2, and D2 resides only in group G2, then we end up with 3 databases: G1:D1, G2:D1, and G2:D2. Each database is stored on its own TSDB instance on a separate Paragon Insights node as shown in Figure 1. When a new device is onboarded and placed within a device group, Paragon Insights chooses a TSDB database instance on which to store that device data.
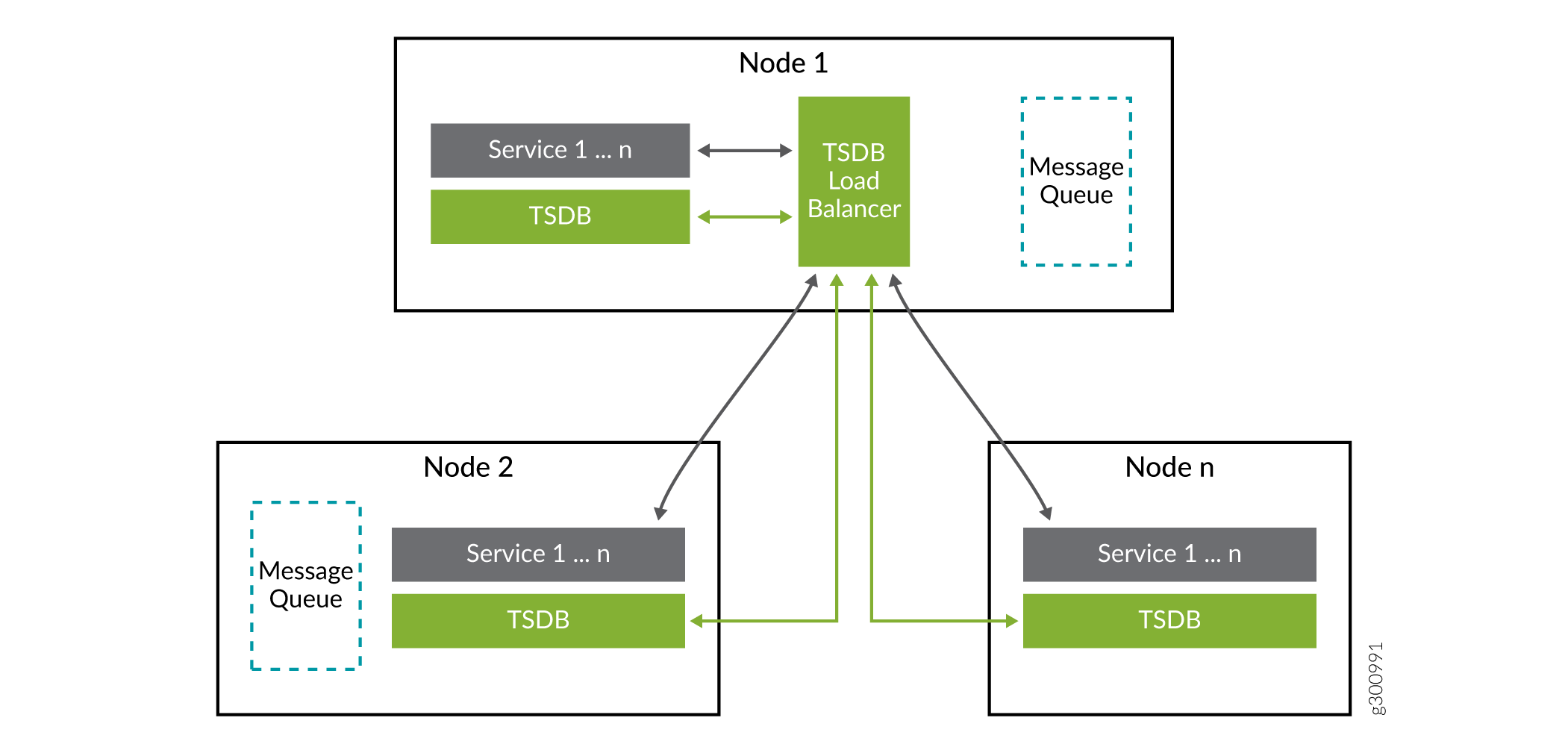
Figure 1, shows 3 Paragon Insights nodes. Each of these nodes have a TSDB instance and other Paragon Insights services running.
-
A maximum of 1 TSDB instance is allowed on any given Paragon Insights node. Therefore, a Paragon Insights node can have 0 or 1 TSDB instances at any time.
-
A Paragon Insights node can be dedicated to running only TSDB functions. No other Paragon Insights functions can run on nodes dedicated to running TSDB functions. This prevents other Paragon Insights functions from starving the TSDB instance of resources.
-
We recommend that you dedicate nodes to TSDB to provide the best performance.
-
Paragon Insights and TSDB nodes can be added to a running system using the Paragon Insights CLI.
Database Replication
As with any other database system, replication refers to storing the data in multiple instances on multiple nodes. In Paragon Insights, we configure a replication factor to determine how many copies of the database are needed.
A replication factor of 1 creates only one copy of data, and therefore, provides no HA. When multiple Paragon Insights nodes are available and replication factor is set to 1, then only sharding is achieved. The replication factor determines the minimum number of Paragon Insights nodes needed. A replication factor of 3 creates three copies of data, requires at least 3 Paragon Insights nodes, and provides HA. The higher the replication factor, the stronger the HA and higher the resource requirements in terms of Paragon Insights nodes. If you want to scale your system further, you must add Paragon Insights nodes in exact multiples of the replication factor. For example, 3, 6, 9, etc.
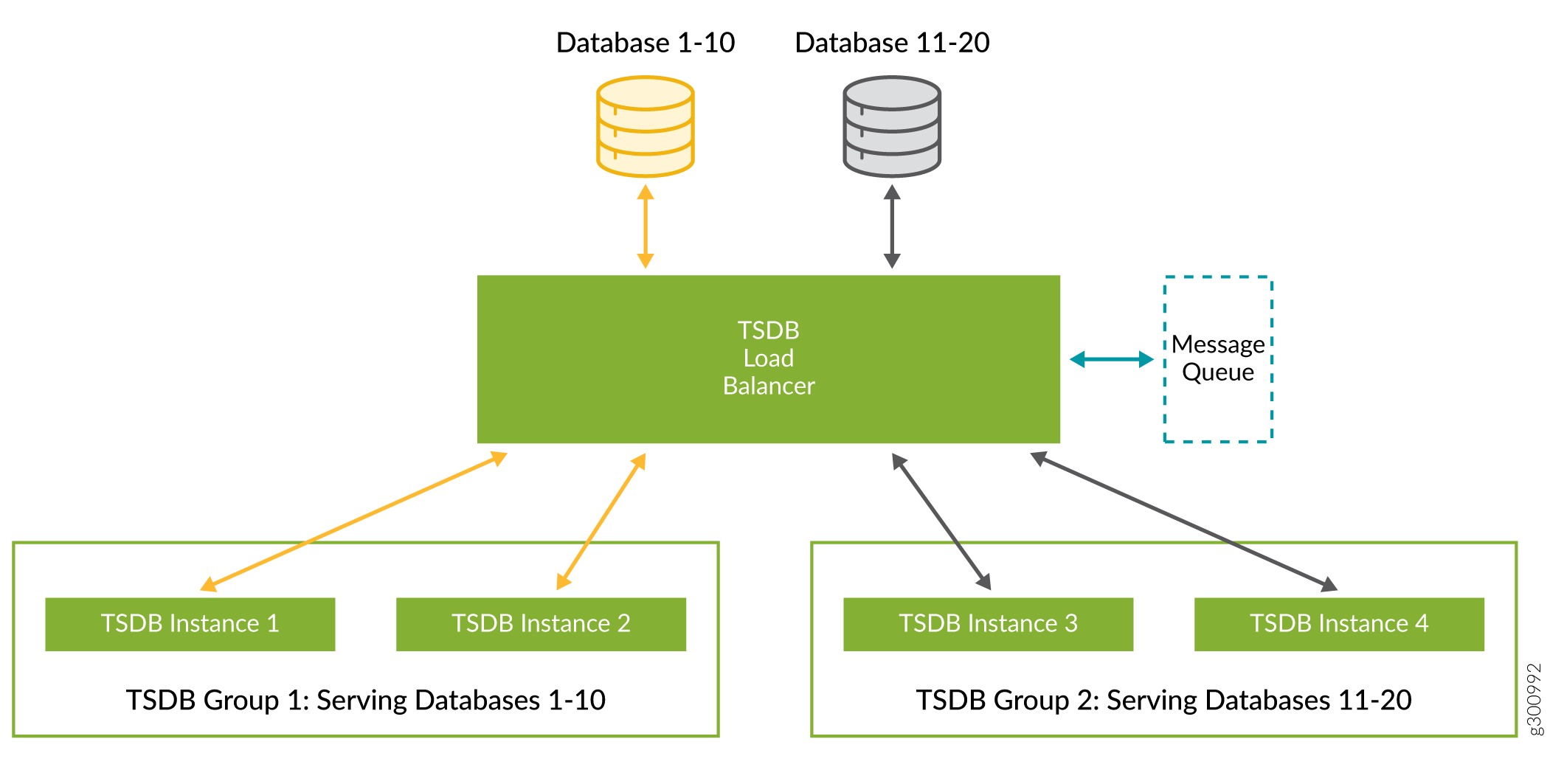
Consider an example where, based on device/device-group pairing mentioned earlier, Paragon Insights has created 20 databases. The Paragon Insights system in question has a replication factor of 2 and has 4 nodes running TSDB. Based on this, two TSDB replication groups are created; in our example they are TSDB Group 1 and TSDB Group 2. In Figure 2, the data from databases 1-10 is being written to TSDB instances 1 and 2 in TSDB group 1. Data from databases 11-20 is written to TSDB instances 3 and 4 in TSDB group 2. The outline around the TSDB instances represents a TSDB replication group. The size of the replication group is determined by the replication factor.
Database Reads and Writes
As shown in Figure 1, Paragon Insights can make use of a distributed messaging queue. In cases of performance problems or errors within a given TSDB instance, this allows for writes to the database to be performed in a sequential manner ensuring that all data is written in proper time sequence.
All Paragon Insights microservices use standardized database query (read) and write functions. This can be used even if the underlying database system is changed at some point in the future. This allows for flexibility in growth and future changes. Other read and write features of the database system include:
-
In normal operation, database writes are sent to all TSDB instances within a TSDB group.
-
Database writes can be buffered up to 1GB per TSDB instance so that failed writes can be retried until successful.
-
If problems persist and the buffer fills up, the oldest data is dropped in favor of new data.
-
When buffering is active, database writes are performed sequentially so that new data cannot be written until the previous write attempts are successful.
-
Database queries (reads) are sent to the TSDB instance which has reported the fewest write errors in the last 5 minutes. If all instances are performing equally, then the query is sent to a random TSDB instance in the required group.